
【python大作业/爬虫实战】——基于智联招聘的数据采集(爬虫)+可视化(附完整代码)

在当今数字化时代,网络爬虫技术已成为数据获取的重要手段之一。本文将通过一个实际案例——采集智联招聘信息,详细介绍如何使用Python和Selenium框架实现数据采集。我们将从环境准备、网页结构分析、采集字段说明到爬虫实现步骤等方面展开,帮助读者快速掌握相关技术。
> 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本篇文章使用的是seleniunm接管已经打开的浏览器进行数据采集,原理不懂的可以看之前的技术博客 ( selenium接管已经打开的浏览器)
更新时间:2025-5-29
可用版本:drissonpage版本、selenium版本
一、项目背景
随着大数据技术的快速发展,大数据相关岗位需求激增。为了更好地了解全国各地区大数据岗位的分布情况、薪资水平及企业需求,我开发了这个基于Selenium的智联招聘爬虫项目。该项目能够自动搜索"大数据"相关岗位,并按省份分类采集岗位详细信息,为求职者、人力资源研究者和数据分析师提供有价值的数据支持。
二、环境准备
所需工具和库
-
Python
-
Selenium
-
Chrome浏览器
-
ChromeDriver驱动
pip install selenium
ChromeDriver配置
-
下载与本地Chrome浏览器版本匹配的ChromeDriver
-
将ChromeDriver.exe放在指定路径(或者放在anaconda根目录下,不懂的直接指定路径)
-
确保Chrome浏览器已安装并可正常运行
三、采集字段说明
字段类别 字段名称 字段说明 示例值 岗位信息 岗位名称 招聘职位的名称 "大数据开发工程师" 岗位薪资 职位提供的薪资范围 "15-25k/月" 岗位标签 职位的福利或特点标签列表 ["五险一金", "年终奖", "带薪年假"] 工作省份 职位所在的省份 "北京" 工作地点 职位的具体工作城市/区域 "海淀区" 工作经验 职位要求的工作年限 "3-5年" 学历要求 职位要求的学历水平 "本科" 公司信息 公司名字 招聘企业的名称 "XX科技有限公司" 公司类型 企业的所有制类型 "民营" 公司规模 企业的人员规模范围 "1000-9999人" 公司行业 企业所属的行业领域 "互联网/IT" 四、网页结构分析
在编写爬虫之前,我们需要对51job的网页结构进行分析,以便准确提取所需信息。
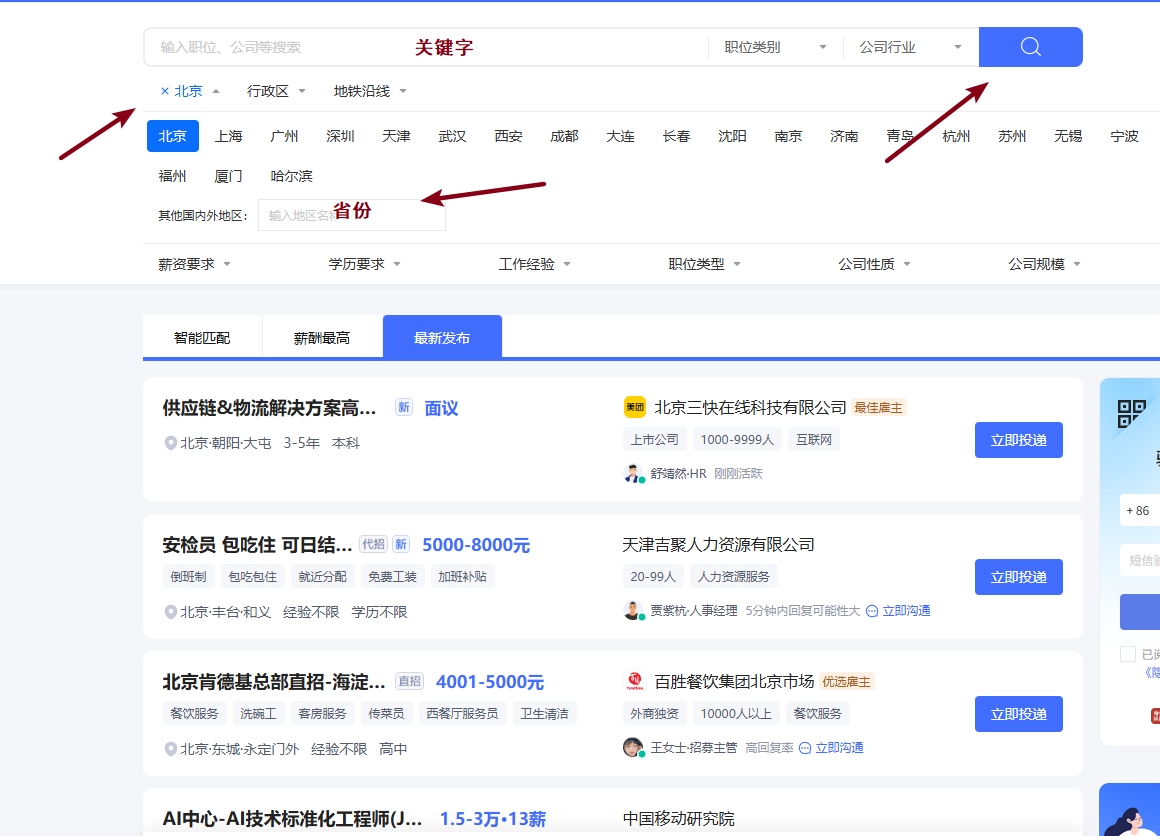
职位列表页面 智联招聘
对于该网页,第一步应该是在搜索框输入关键字,然后点击搜索;第二步是选择地区,然后对网页进行数据解析和数据保存。
-
动态加载:页面采用动态加载技术,需要模拟浏览器操作
-
反爬机制:有一定反爬措施,需要合理设置等待时间和随机延迟
五、爬虫步骤分析
(一)关键字搜索
关键字搜索是整个爬虫的起始步骤,通过模拟用户在智联招聘网站上的搜索行为来定位目标数据。
-
访问初始页面:首先使用bro.get()方法打开智联招聘的搜索页面(基础URL为https://www.zhaopin.com/sou/jl779/p1)
-
定位搜索框:通过XPath语法找到搜索输入框元素
-
输入关键词:使用send_keys(keyword)方法输入目标关键词("大数据")
-
触发搜索:点击搜索按钮
(二)区域选择
区域选择功能允许按省份筛选职位,通过job_area(province)函数实现:
-
打开地区筛选器:点击地区筛选按钮
-
输入目标省份:在地区搜索框中输入省份名称(注意:海南和吉林是情况,不能简单的回车)
-
确认选择:
-
对于特殊省份(如吉林、海南)需要单独处理,点击特定列表项
-
其他省份直接按回车键确认
-
等待结果刷新:选择后等待1-2秒让页面刷新
-
特殊处理:
-
使用WebDriverWait显式等待确保元素可交互,确保按钮已经可以点击
-
对"香港"、"澳门"、"台湾"地区做了跳过处理,因为没有数据
(三)数据解析和保存
数据解析是核心功能,通过parsel_data()函数实现:
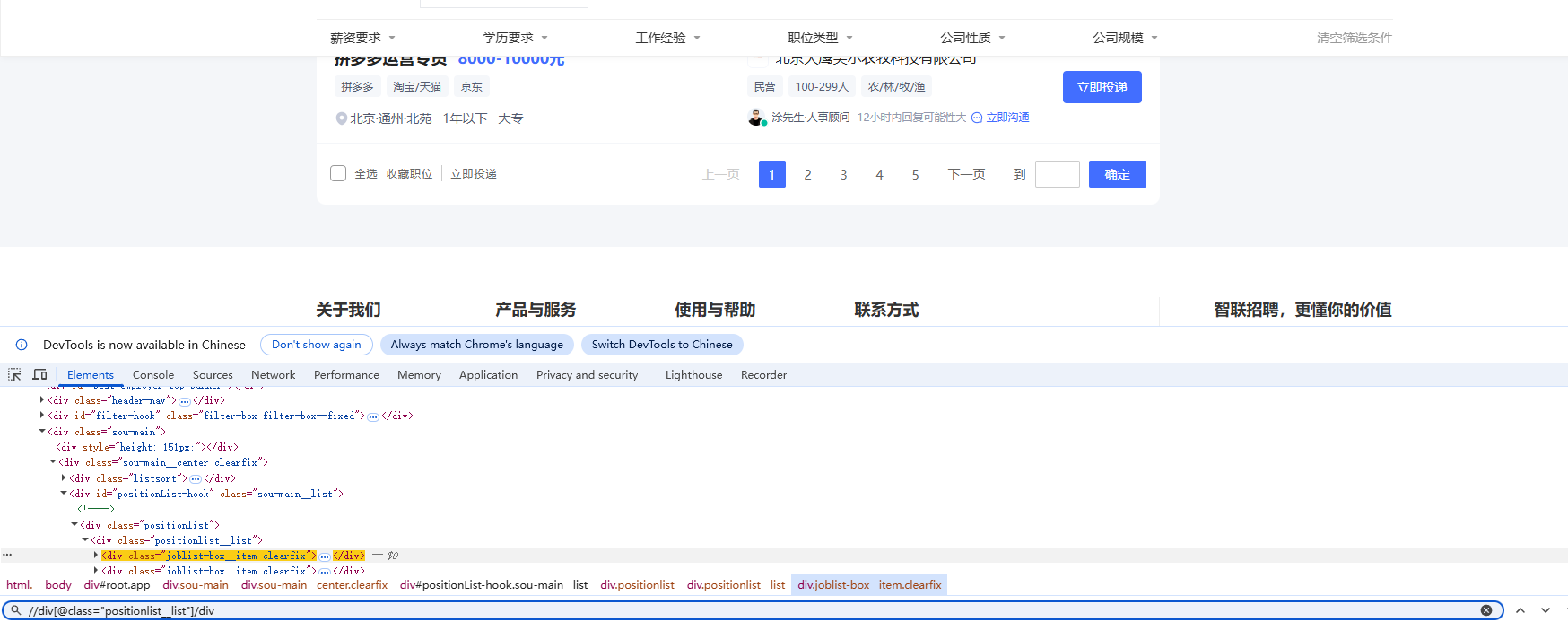
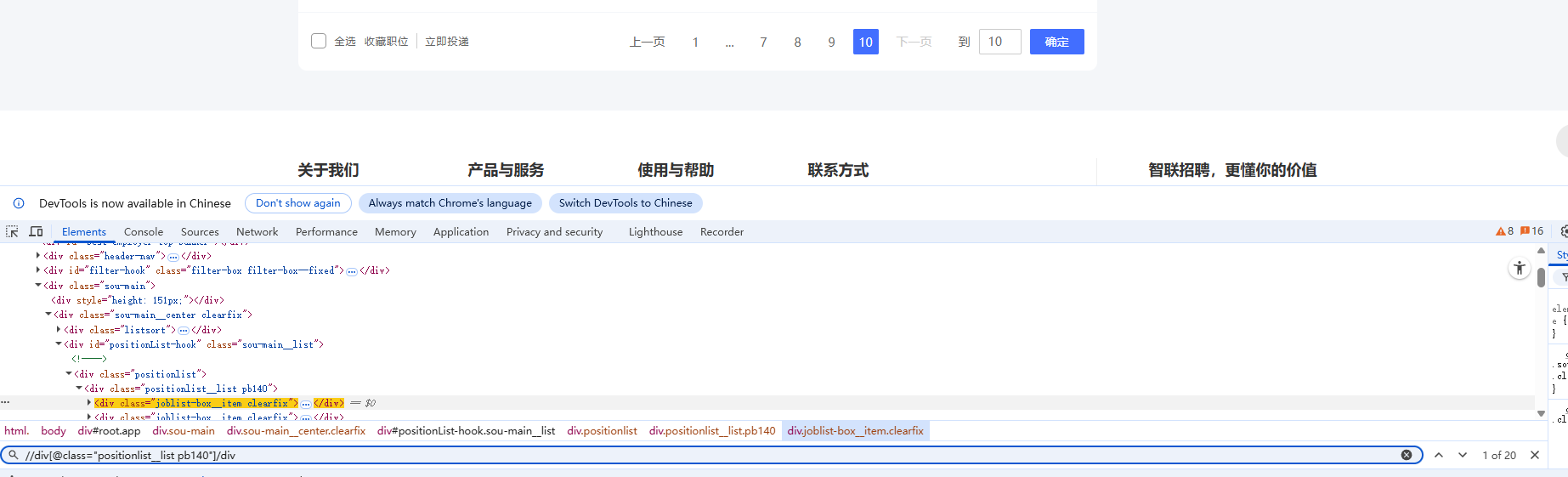
1.定位职位列表
本案例用的是二次提取,最后一页的岗位信息标签存在不一致,应该是第二套标签内容。
或者直接//div[@] 这样定位就不会出现定位不到的问题
2.提取岗位信息
-
岗位名称:从jobinfo__top类下的标签获取
-
薪资:从jobinfo__salary类提取
-
标签:收集jobinfo__tag下的所有div文本
3.提取公司信息
-
公司名称:从companyinfo__top类下的标签获取
-
公司标签:解析companyinfo__tag下的div,分别提取类型、规模和行业
4.数据存储
-
使用csv.DictWriter将数据写入CSV文件(按实际需求进行对应的数据保存)
-
字段包括11个关键信息点
-
对可能缺失的字段(如公司类型)进行异常处理
(四)翻页
-
定位翻页按钮:使用XPath//div[@]/a[last()]找到"下一页"按钮
-
执行翻页操作:
-
直接调用click()方法点击
-
也可使用JS执行点击(注释掉的execute_script方案)
-
页码追踪:通过page += 1记录当前页码
-
终止条件:
-
当找不到下一页按钮时触发异常
-
通过try-except捕获异常并终止循环
-
-
建议采用click点击翻页,因为最后一页点击不到就报错,然后捕获异常break
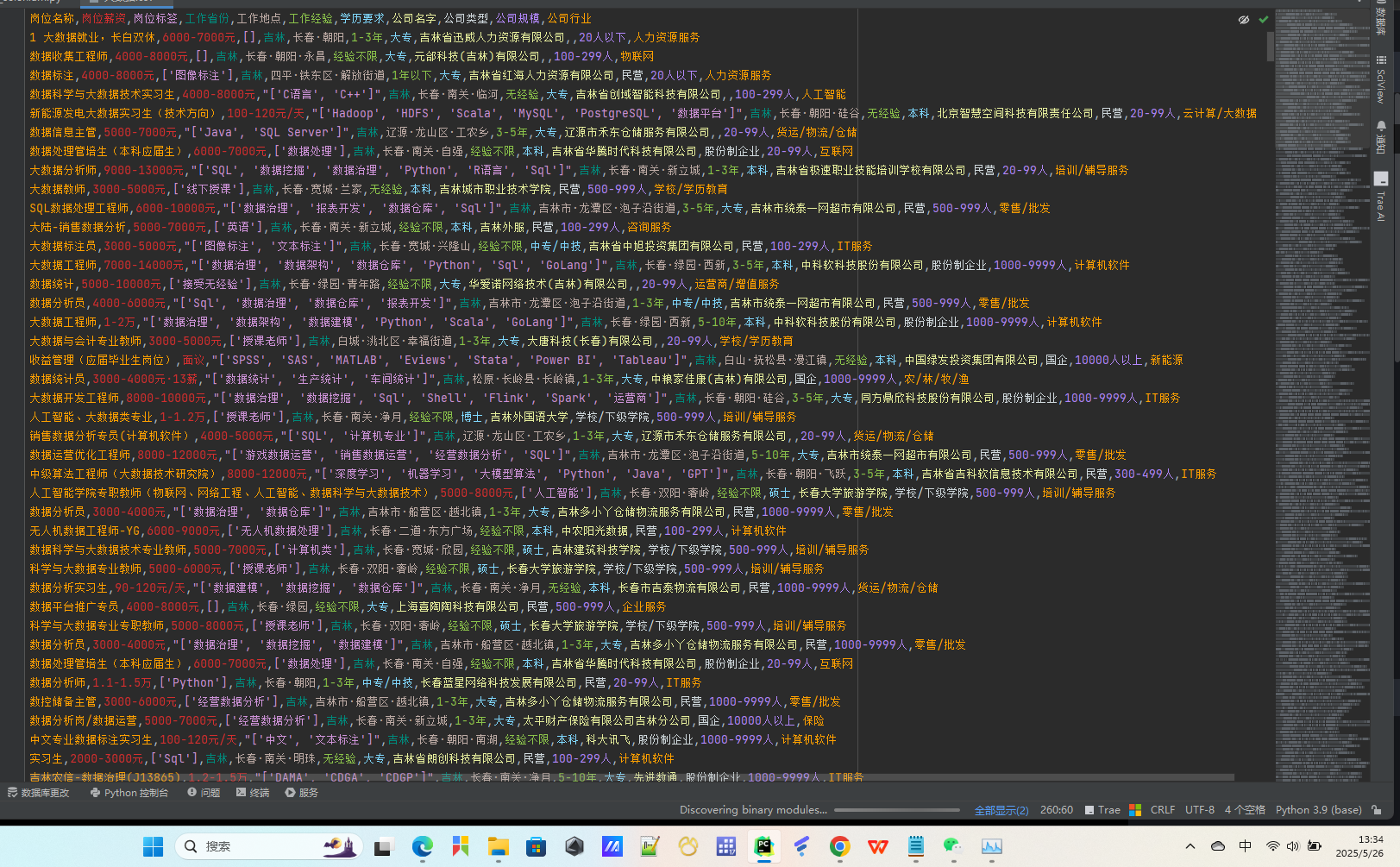
六、结果展示
七、完整代码
(一)数据采集(爬虫)部分
(二)可视化部分
1.岗位数量地域分布地图
from pyecharts import options as opts from pyecharts.charts import Map map_data = df['工作省份'].value_counts().reset_index().values.tolist() map_chart = ( Map() .add( series_name="", data_pair=map_data, maptype="china", is_map_symbol_show=False, # 禁用标记点 label_opts=opts.LabelOpts(is_show=True, font_size=8), # 调整省份字体大小 ) .set_global_opts( title_opts=opts.TitleOpts(title="岗位数量地域分布地图"), visualmap_opts=opts.VisualMapOpts( is_piecewise=True, # 分段显示 pieces=[ {"min": 300, "label": "300以上", "color": "#FF4500"}, {"min": 150, "max": 299, "label": "150-300", "color": "#FFA07A"}, {"min": 50, "max": 149, "label": "50-150", "color": "#FFE4B5"}, {"min": 0, "max": 49, "label": "50以下", "color": "#FFF5E6"}, ], ), ) ) map_chart.render('./可视化结果/岗位数量地域分布地图.html') map_chart.render_notebook()
2 .不同学历的平均月薪
education_order = [ '学历不限', '初中及以下', '高中', '中专/中技', '大专', '本科', '硕士', '博士', ] avg_salary = df['岗位薪资(元/月)'].groupby(df['学历要求']).mean() avg_salary = avg_salary.reindex(education_order) # 按学历由低到稿排列 plt.figure(figsize=(8, 6)) # 设置图形大小 sns.barplot(x=avg_salary.index, y=avg_salary.values, palette='viridis') # 使用 seaborn 绘制柱状图 # 添加标题和标签 plt.title('不同学历的平均月薪', fontsize=16) plt.xlabel('') plt.ylabel('') plt.savefig('./可视化结果/不同学历的平均月薪.png') # 显示图形 plt.show()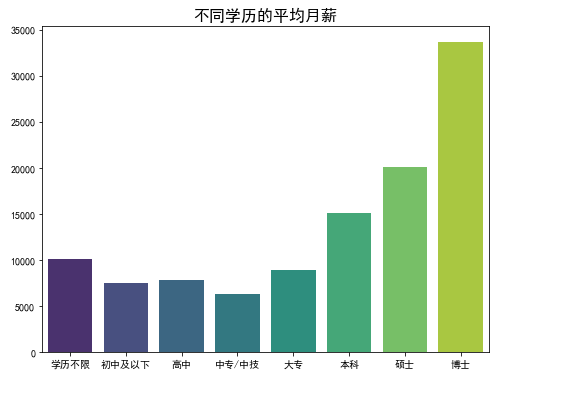
3 .中国城市月薪Top 7
avg_salary_city = df['岗位薪资(元/月)'].groupby(df['工作地点']).mean().sort_values(ascending=False)[:7] plt.figure(figsize=(10, 6)) # 设置图形大小 sns.barplot(x=avg_salary_city.values, y=avg_salary_city.index, palette='viridis') # 使用 seaborn 绘制柱状图 # 添加标题和标签 plt.title('中国城市月薪Top 7', fontsize=16) plt.xlabel('') plt.ylabel('') plt.grid(False) plt.savefig('./可视化结果/中国城市月薪Top7.png') plt.show()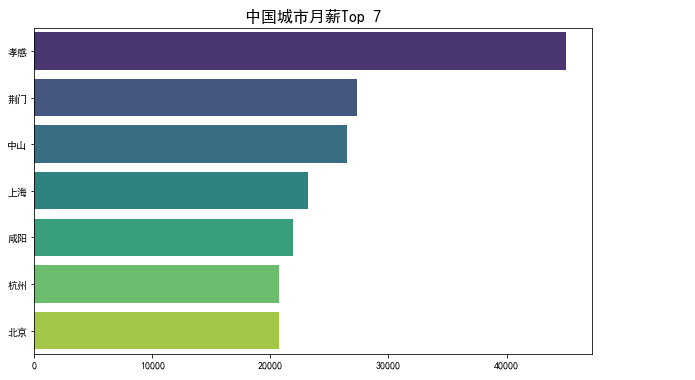
4. 工作经验占比分布
size_counts = df['工作经验'].value_counts() # 主题 sns.set_theme(,rc={ "font.sans-serif": ["SimHei"], "axes.unicode_minus": False, "font.family": "sans-serif" }) plt.figure(figsize=(8, 8)) # 设置画布大小 plt.pie( size_counts, # 数据 labels=size_counts.index, # 标签 autopct='%1.1f%%', # 显示百分比 startangle=90, # 起始角度 colors=sns.color_palette("pastel"), # 使用 Seaborn 的 pastel 调色板 wedgeprops={'edgecolor': 'white', 'linewidth': 1.5}, # 设置扇形边缘样式 textprops={'fontsize': 12, 'color': 'black'} # 设置文本样式 ) plt.title("工作经验占比分布", fontsize=16, fontweight='bold', pad=20) plt.savefig('./可视化结果/工作经验占比分布.png') plt.show()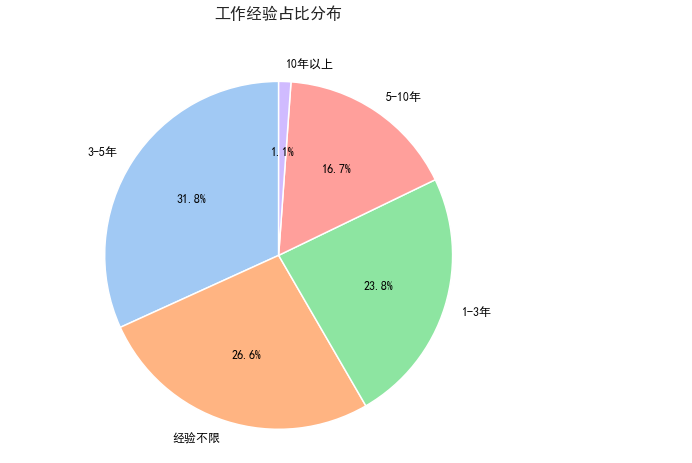
5.企业规模占比分布
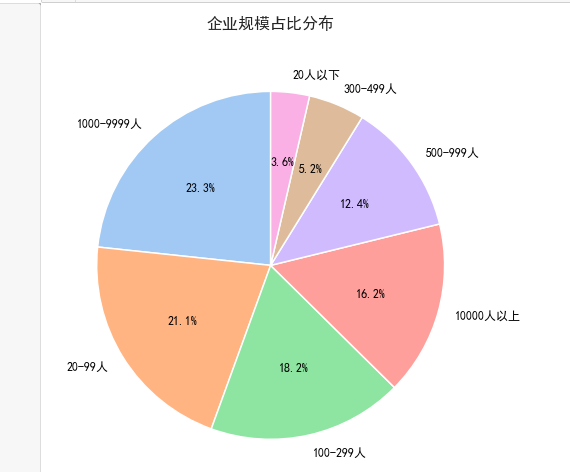
6.企业类型占比分布
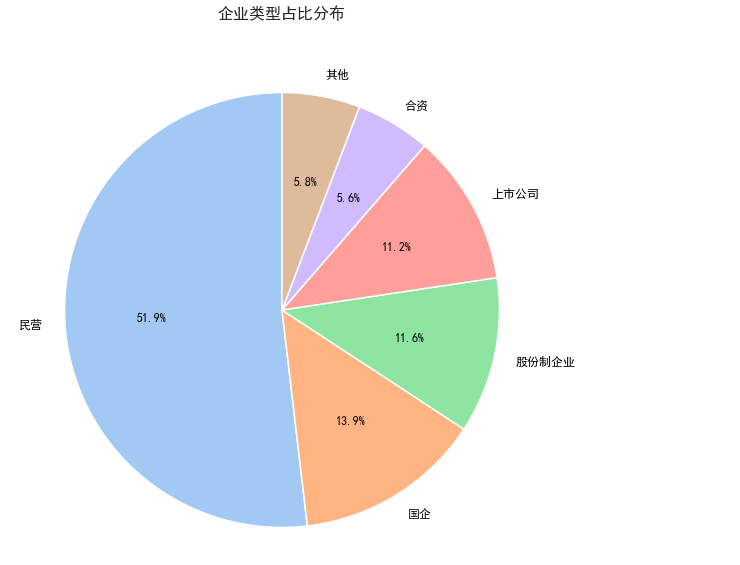
7.岗位标签词云
from wordcloud import WordCloud import jieba all_text = ' '.join(df['岗位标签']) words = jieba.lcut(all_text) all_text = ' '.join(words) wordcloud = WordCloud( font_path='simhei.ttf', # 设置字体路径(支持中文) width=800, height=600, background_color='white', # 设置背景颜色 max_words=100, # 设置最多显示的词数 min_font_size=10, # 设置最小字体大小 max_font_size=100, # 设置最大字体大小 random_state=42 # 设置随机种子 ).generate(all_text) plt.figure(figsize=(10, 8)) plt.imshow(wordcloud, interpolation='bilinear') plt.axis('off') # 关闭坐标轴 plt.title('', fontsize=16) plt.savefig('./可视化结果/岗位标签词云.png') plt.show()
-
-
-
-
-







