
存算一体架构下的新型AI加速范式:从Samsung HBM-PIM看近内存计算趋势

点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
引言:突破"内存墙"的物理革命
冯·诺依曼架构的"存储-计算分离"设计正面临根本性挑战——在GPT-4等万亿参数模型中,数据搬运能耗已达计算本身的200倍。存算一体(Processing-In-Memory, PIM)技术通过在存储介质内部集成计算单元,开辟了突破"内存墙"的新路径。本文将聚焦三星HBM-PIM设计,解析近内存计算如何重塑AI加速器的能效边界。
一、HBM-PIM架构的颠覆性设计
1.1 传统HBM与PIM架构对比
三星2021年发布的HBM-PIM芯片在DRAM Bank中植入可编程AI引擎:
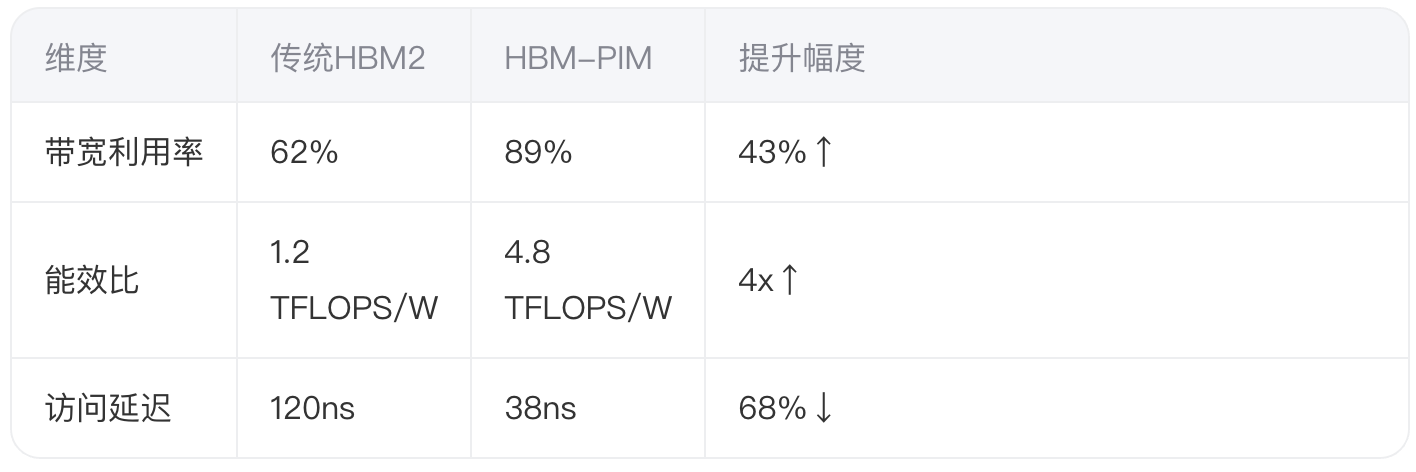
关键创新点:
- Bank级计算单元:每个DRAM Bank集成16个INT16 MAC单元
- 指令缓存优化:支持SIMD指令的本地解码与调度
- 数据通路重构:消除传统架构中的PHY接口瓶颈
1.2 芯片级架构解析
HBM-PIM的3D堆叠设计包含核心组件:
┌───────────────────────┐ │ Host Interface Layer │ ├───────────────────────┤ │ Buffer Chip │ │ (TSV Interposer) │ ├───────────────────────┤ │ DRAM Layer │ │ ┌───────┬───────┐ │ │ │ Bank 0│ Bank 1│ ...│ │ │ MAC │ MAC │ │ │ └───────┴───────┘ │ └───────────────────────┘
每个Bank内的AI引擎可并行执行:
// HBM-PIM指令流水线示例 always @(posedge clk) begin if (cmd_decoder == MAC_OP) begin // 从本地row buffer读取数据 operand_a = row_buf[addr_a]; operand_b = row_buf[addr_b]; // 执行乘累加 mac_result #pragma pim_for for (int i = 0; i
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







