
美团Leaf分布式ID生成器:雪花算法原理与应用

📖 前言
在分布式系统中,全局唯一ID生成是保证数据一致性的核心技术之一。传统方案(如数据库自增ID、UUID)存在性能瓶颈或无序性问题,而美团开源的Leaf框架提供了高可用、高性能的分布式ID解决方案。本文重点解析Leaf中**雪花算法(Snowflake)**的使用与优化技巧。
一、为什么需要分布式ID?
1. 分库分表场景:避免全局ID冲突
传统单库问题:单库使用数据库自增ID时,分库分表后,各库独立自增会导致ID重复(例如用户表分成10个库,每个库从1开始自增,插入10个用户后所有库的ID都是1~10)。
分布式协调代价高:若依赖数据库序列或中央节点生成ID,跨库事务和网络延迟会成为瓶颈。
美团场景:
美团早期使用数据库代理(如Atlas)分库,若ID不全局唯一,订单可能重复。采用Leaf-segment方案,通过代理批量申请ID段(如1~1000),每个服务节点缓存一段ID本地生成,避免实时访问数据库,同时保证全局唯一。
2. 高并发场景:突破数据库性能瓶颈
自增ID的瓶颈:单库每秒写入上限约几万次(如MySQL的TPS通常在数千级别),而美团峰值每秒订单量可能超百万,传统自增ID无法支撑。
锁竞争与延迟:数据库自增锁(AUTO_INCREMENT)在并发插入时会导致线程阻塞,影响吞吐量。
3. 业务需求:ID的智能性与可解析性
时间有序性:
订单/日志ID按时间递增,可直接通过ID比较数据新旧(如美团的订单ID高位嵌入时间戳),避免按时间字段排序的开销。
业务信息嵌入:
例1:订单ID 20231015123456789 中,前8位 20231015 表示日期,便于按天归档或排查问题。
例2:用户ID包含分库分表位(如末2位表示库编号),可直接路由到对应数据库。 安全与风控:
避免ID连续(如自增ID暴露业务量),可采用哈希或时间戳+随机数,但需权衡有序性需求。
4. 为什么不用UUID?
无序性:UUID的随机性导致数据库索引频繁分裂,插入性能下降(B+树维护代价高)。
存储空间:UUID是128位字符串(如550e8400-e29b-41d4-a716-446655440000),比64位数字占用更多空间,影响存储和查询效率。

可读性差:无法直接解析业务信息(如时间、业务类型)。
二、美团Leaf核心模式
Leaf提供两种ID生成模式:
- 号段模式(Leaf-segment):
-通过缓存号段提升性能,依赖数据库。
-预分配ID段(如每次从DB获取1000个ID),减少DB访问频率。
 (图片来源网络,侵删)
(图片来源网络,侵删)-双Buffer异步加载,避免ID段用尽时等待。
- 雪花算法模式(Leaf-snowflake):(本文重点)
-完全分布式,无需依赖数据库。
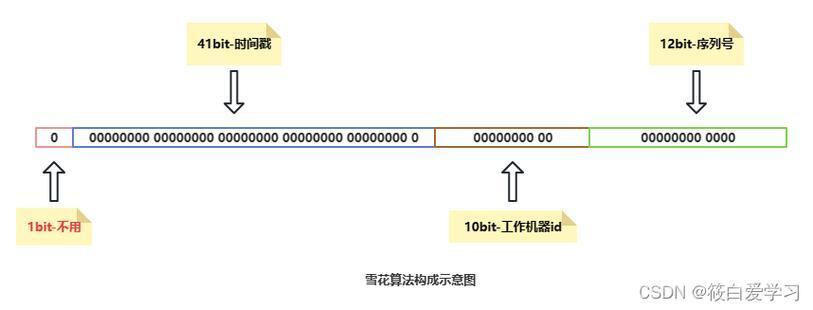
-64位ID = 时间戳(41位) + WorkerID(10位) + 序列号(12位)。
-通过时钟同步(NTP)解决时间回拨问题,若回拨时间短则等待,长则报警降级。
雪花模式的两种方案
1.基于Snowflake算法
完全本地生成ID(无需DB交互),利用工作进程ID(WorkerID)区分不同节点,单机每秒可生成数万ID。
2.动态调整WorkerID:
通过ZooKeeper或DB分配WorkerID,避免手动配置,解决节点扩容时的ID冲突问题。
三、Leaf雪花算法实战
1. 环境准备
博主找了好久才找到这个可以直接引用腾讯的依赖,如果依赖下载不来可以将Maven镜像源配置为腾讯的
依赖引入(Maven):
Zookeeper依赖 org.apache.curator curator-framework 4.0.1 美团分布式ID依赖 com.tencent.devops.leaf leaf-boot-starter 1.0.2-RELEASE2. 配置Leaf服务
新建 leaf.properties:
leaf.name=your-service-name leaf.snowflake.enable=true leaf.snowflake.zk.address=127.0.0.1:2181 # Zookeeper地址(用于节点ID分配) leaf.snowflake.port=8080 # 本地服务端口
3. 初始化
@Configuration public class LeafConfiguration { @SneakyThrows @Bean public SnowflakeService snowflakeService(){ return new SnowflakeService("127.0.0.1",2128); } }注入服务并生成分布式ID
@Autowired private SnowflakeService snowflakeService; @PostMapping("add") public ResponseResult add(@RequestBody User user) { Result id = snowflakeService.getId("od"); user.setId(id.getId() + ""); System.out.println(id.toString()); loginService.add(user); return ResponseResult.success(); }4. 关键参数调优
- Zookeeper地址:确保集群配置一致。
- workerId分配:Leaf通过Zookeeper自动分配,避免手动配置冲突。
- 时钟回拨处理:Leaf默认容忍少量回拨(可通过-Dleaf.snowflake.tolerant.time=2000调整)。
如果你希望简化部署或避免引入Zookeeper,也可以通过其他方式实现。以下是具体分析及替代方案:
方案一:手动指定workerId(不推荐)
在配置文件中直接指定workerId,无需Zookeeper协调,但需确保不同节点的workerId不重复。
配置示例(leaf.properties):
leaf.snowflake.enable=true leaf.snowflake.zk.address= # 置空,不使用Zookeeper leaf.snowflake.workerId=1 # 手动指定当前节点的workerId(范围:0~31)
注意事项:
- 需自行保证集群中各节点的workerId唯一性(例如通过环境变量或启动参数注入)。
- 节点扩容时需手动管理workerId,易出错,仅适用于小型固定集群。
方案二:改用号段模式(无Zookeeper依赖)
如果不想依赖Zookeeper,可切换至Leaf的号段模式,直接基于数据库生成ID段。
配置示例:
leaf.segment.enable=true leaf.jdbc.url=jdbc:mysql://localhost:3306/leaf?useSSL=false leaf.jdbc.username=root leaf.jdbc.password=123456
优势:
- 无需Zookeeper,仅依赖数据库。
- 适合对ID连续性无严格要求的场景(如日志流水号)。
劣势:
- 性能略低于雪花算法(TPS约1万~10万,依赖数据库性能)。
4. 总结:如何选择?
场景 推荐方案 依赖组件 复杂度 中小集群,可控节点 Leaf手动指定workerId 无(需人工管理) 低 大型分布式系统 Leaf + Zookeeper Zookeeper 中 无协调服务,轻量级需求 自实现雪花算法 无 高 可接受数据库依赖 Leaf号段模式 数据库 低 用Docker快速搭建Zookeeper(备用参考)
若仍希望使用Zookeeper,可通过Docker快速启动单节点:
# 拉取镜像 docker pull zookeeper:3.8 # 启动容器 docker run -d --name zookeeper -p 2181:2181 zookeeper:3.8
在Leaf配置中填写leaf.snowflake.zk.address=127.0.0.1:2181即可。
通过以上方案,你可以根据实际需求选择是否整合Zookeeper。如果追求高可用和自动化,Zookeeper仍是推荐选择;若资源有限,手动管理或号段模式也能满足基本需求。
总结
美团Leaf的雪花算法通过以下优势成为分布式ID首选:
- 去中心化:无需DB依赖,通过Zookeeper自动分配节点。
- 高性能:单节点每秒可生成400万+ ID。
- 易用性:开箱即用,API简洁。
适用场景:电商订单、物流跟踪、实时消息等需要有序唯一ID的业务。







