PostgreSQL - pgvector 插件构建向量数据库并进行相似度查询

在现代的机器学习和人工智能应用中,向量相似度检索是一个非常重要的技术,尤其是在文本、图像或其他类型的嵌入向量的操作中。本文将介绍如何在 PostgreSQL 中安装 pgvector 插件,用于存储和检索向量数据,并展示如何通过 Python 脚本向数据库插入向量并执行相似度查询。
一、安装 PostgreSQL 并配置 pgvector 插件
1. 安装 PostgreSQL
首先,确保你已经安装了 PostgreSQL。可以通过 Docker 快速安装 PostgreSQL。
docker pull postgres docker run --name my_postgres -e POSTGRES_PASSWORD=mysecretpassword -e POSTGRES_USER=myuser -e POSTGRES_DB=mydb -p 5432:5432 -d postgres
上述命令会启动一个名为 my_postgres 的容器,并暴露 5432 端口以便外部连接。
2. 安装 pgvector 插件
pgvector 插件可以让你在 PostgreSQL 中存储向量,并支持高效的向量相似度查询。通过以下步骤安装 pgvector:
进入 PostgreSQL 容器后,执行以下命令:
docker exec -it my_postgres bash apt update apt install -y postgresql-server-dev-all make gcc git git clone https://github.com/pgvector/pgvector.git cd pgvector make make install
3. 创建数据库并启用 pgvector 插件
进入 PostgreSQL 终端,创建一个数据库并启用 pgvector 插件:
psql -U myuser -d mydb
在 PostgreSQL 终端中执行:
CREATE EXTENSION vector;
这样我们就可以使用 pgvector 插件来存储和检索向量了。
二、创建向量表
接下来,我们需要创建一个用于存储向量的表。假设我们有一个名为 knowledge.vector_data 的表,它将存储用户 ID、文件 ID、文本内容以及对应的向量。
-- 创建 schema
CREATE SCHEMA knowledge;
-- 创建 vector_data 表
CREATE TABLE knowledge.vector_data (
id SERIAL PRIMARY KEY, -- 自动递增的主键
user_id BIGINT NOT NULL DEFAULT 0,
file_id BIGINT NOT NULL DEFAULT 0,
content VARCHAR(65535) NOT NULL DEFAULT '', -- 存储文本内容
featrue VECTOR(1024), -- 存储1024维向量
created TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建 HNSW 索引并指定操作符类 (例如,使用余弦相似度)
CREATE INDEX ON knowledge.vector_data USING hnsw (featrue vector_cosine_ops);
这个表将存储文本内容及其对应的 1024 维向量。我们选择 1024 维是因为一些嵌入模型生成的向量维度较高。如果你的向量维度不同,可以调整此值。
三、Python 测试程序:向量化并插入数据库
接下来,我们将编写一个 Python 脚本,将一些测试句子向量化后插入数据库,并进行相似度查询。
1. 安装所需 Python 库
首先,你需要安装 sentence-transformers 库来进行句子的向量化处理,并使用 psycopg2 连接 PostgreSQL:
pip install sentence-transformers psycopg2 numpy
2. 完整的 Python 脚本
以下是完整的 Python 脚本,它可以将测试语句向量化后插入 PostgreSQL 数据库,然后执行相似度查询并返回相似的句子及其相似度评分:
import psycopg2
from sentence_transformers import SentenceTransformer
import numpy as np
# 数据库连接信息
DB_HOST = "localhost"
DB_PORT = "5432"
DB_NAME = "mydb"
DB_USER = "myuser"
DB_PASSWORD = "mysecretpassword"
# 连接 PostgreSQL 数据库
def connect_db():
conn = psycopg2.connect(
host=DB_HOST,
port=DB_PORT,
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD
)
return conn
# 向量化函数
def vectorize_sentences(sentences, target_dim=1024):
# 使用预训练模型 "all-MiniLM-L6-v2" 向量化句子
model = SentenceTransformer('paraphrase-MiniLM-L12-v2')
sentence_vectors = model.encode(sentences)
# 将 384 维向量扩展到 1024 维,使用 0 进行填充
padded_vectors = [np.pad(vector, (0, target_dim - len(vector)), 'constant') for vector in sentence_vectors]
return padded_vectors
# 将向量插入数据库
def insert_vectors_to_db(sentences, vectors):
conn = connect_db()
cursor = conn.cursor()
# 将句子和其对应的向量插入表中
for sentence, vector in zip(sentences, vectors):
sql = """
INSERT INTO knowledge.vector_data (user_id, file_id, content, featrue)
VALUES (%s, %s, %s, %s)
"""
cursor.execute(sql, (1, 1, sentence, vector.tolist())) # 假设 user_id 和 file_id 为 1
print(f"Inserted sentence: {sentence}")
conn.commit()
cursor.close()
conn.close()
# 查询最相似的句子
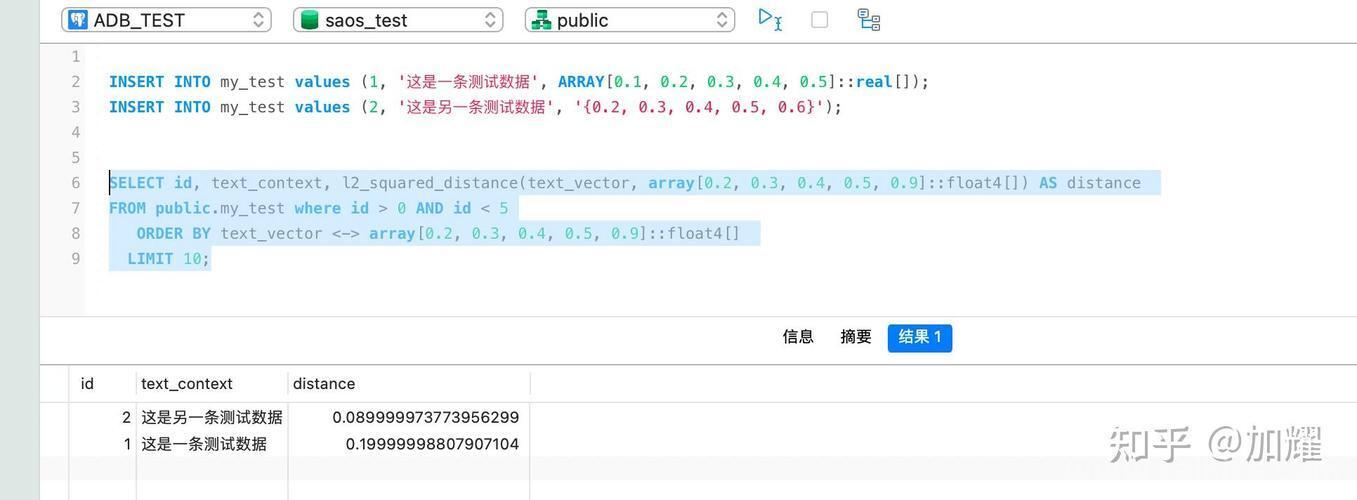
def query_similar_sentences(target_vector):
conn = connect_db()
cursor = conn.cursor()
# 转换向量为 PostgreSQL 可接受的格式
vector_str = '[' + ','.join(map(str, target_vector)) + ']'
# 查询相似句子
sql = """
SELECT content, 1 - (featrue %s) AS similarity
FROM knowledge.vector_data
ORDER BY featrue %s ASC
LIMIT 5;
"""
cursor.execute(sql, (vector_str, vector_str))
results = cursor.fetchall()
for row in results:
print(f"Sentence: {row[0]}, Similarity: {row[1]}")
cursor.close()
conn.close()
if __name__ == "__main__":
# 测试语句
sentences = [
"This is a test sentence.",
"Another sentence for testing.",
"PostgreSQL vector database integration."
]
# 向量化测试语句
# vectors = vectorize_sentences(sentences)
# 将向量插入数据库
# insert_vectors_to_db(sentences, vectors)
# 目标句子,用于查询相似句子
target_sentence = "This is a sentence."
# 获取目标句子的向量
target_vector = vectorize_sentences([target_sentence], target_dim=1024)[0]
# 查询最相似的句子
query_similar_sentences(target_vector)
四、执行流程
- 向量化并插入数据库:通过 insert_vectors_to_db 函数,脚本会将输入的测试语句向量化,并将其存储到 PostgreSQL 中的 knowledge.vector_data 表。
- 相似度查询:通过 query_similar_sentences 函数,脚本会根据输入的目标句子,查询出最相似的句子,并按相似度排序返回结果。
五、结论
通过本文的步骤,你可以在 PostgreSQL 中使用 pgvector 插件存储和查询向量数据。这种方法可以用于文本、图像等数据的相似度检索。我们利用 sentence-transformers 生成句子嵌入,将其存储在 PostgreSQL 数据库中,并通过 SQL 查询高效地返回相似的句子。
使用向量数据库,可以让我们在处理大量嵌入数据时,充分发挥数据库和机器学习的结合力量,实现高效、快速的向量检索。