
Kafka 如何保证顺序消费

在消息队列的应用场景中,保证消息的顺序消费对于一些业务至关重要,例如金融交易中的订单处理、电商系统的库存变更等。Kafka 作为高性能的分布式消息队列系统,通过巧妙的设计和配置,能够实现消息的顺序消费。接下来,我们将深入探讨 Kafka 保证顺序消费的原理与方法,并结合图文进行详细说明。
一、Kafka 顺序消费的基础:分区特性
Kafka 的主题(Topic)由多个分区(Partition)组成,每个分区都是一个有序的、不可变的消息序列。在单个分区内,消息按照生产者发送的顺序依次追加到日志文件中,并且每个消息都有唯一的偏移量(Offset)来标识其在分区内的位置。这就意味着,在同一个分区内,消息天然是有序的,这是 Kafka 实现顺序消费的基础。
1.1 分区的作用
分区的存在使得 Kafka 能够实现水平扩展,提高消息处理的并行度。多个生产者可以同时向不同的分区发送消息,多个消费者也可以同时从不同的分区消费消息。然而,这种并行处理的方式可能会导致消息在主题层面的顺序被打乱,因为不同分区之间的消息是相互独立的,没有严格的顺序关系。所以,要保证消息的顺序消费,就需要对分区进行合理的管理和控制。
1.2 分区与消息顺序的关系
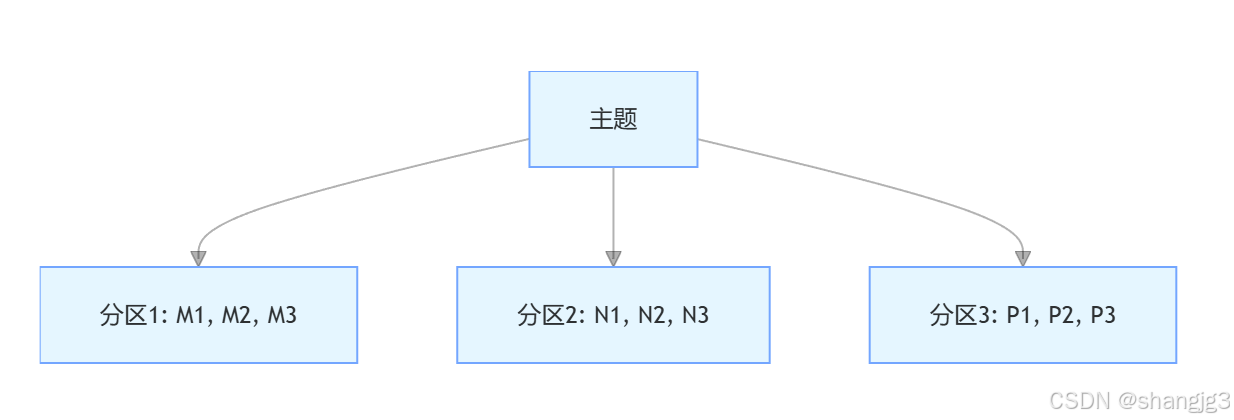
如下图所示,一个主题包含三个分区,每个分区内的消息都是有序的,但分区之间的消息顺序无法保证。例如,分区 1 中的消息 M1、M2、M3 按顺序写入,分区 2 中的消息 N1、N2、N3 也按顺序写入,但从主题整体来看,无法确定 M1 和 N1 谁先被处理。
二、保证顺序消费的方法
2.1 生产者端:控制消息发送到同一分区
为了保证消息的顺序消费,生产者需要将具有顺序依赖关系的消息发送到同一个分区。可以通过以下几种方式实现:
- 自定义分区器:开发者可以实现Partitioner接口来自定义分区策略。例如,在电商系统中,可以根据订单 ID 的哈希值将同一订单相关的消息发送到同一个分区。
import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; public class OrderPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { // 假设key为订单ID,通过哈希值取模分配到固定分区 return Math.abs(key.hashCode()) % cluster.partitionCountForTopic(topic); } @Override public void close() {} @Override public void configure(Map configs) {} }在生产者配置中指定自定义分区器:
Properties properties = new Properties(); properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, OrderPartitioner.class.getName());
- 固定分区策略:如果业务场景允许,也可以直接将消息发送到固定的分区。例如,在一些简单的日志记录场景中,将所有日志消息都发送到分区 0。
ProducerRecord record = new ProducerRecord("log_topic", 0, "log_key", "log_message");2.2 消费者端:一个分区仅由一个消费者消费
在消费者端,为了确保分区内的消息按顺序消费,需要保证一个分区只能被消费者组内的一个消费者消费。Kafka 的消费者组机制天然支持这一点,当消费者组内的消费者数量小于或等于分区数量时,Kafka 会自动将分区分配给消费者,且每个分区最多被一个消费者消费。
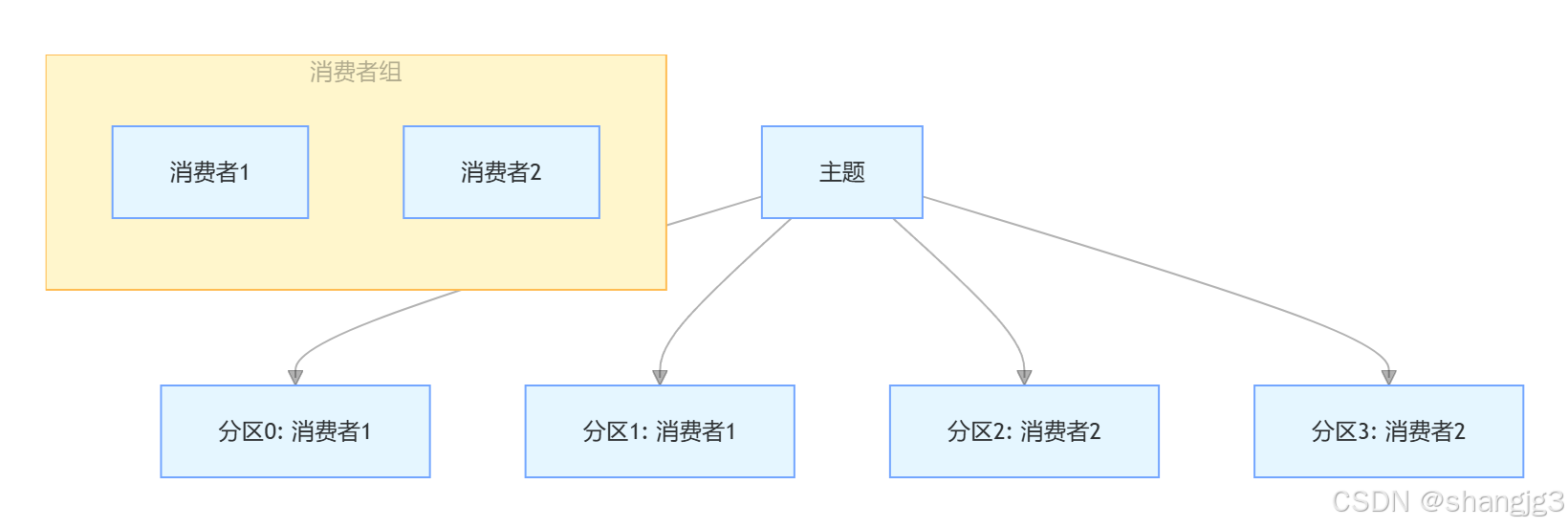
如下图所示,消费者组中有两个消费者,主题有四个分区,Kafka 会将分区 0 和 1 分配给消费者 1,分区 2 和 3 分配给消费者 2,这样每个消费者都能按顺序消费自己负责的分区内的消息。
2.3 消费者端:控制消费线程
如果消费者使用多线程处理消息,需要注意控制线程的消费顺序,避免出现乱序消费的情况。一种常见的方法是为每个分区分配一个独立的消费线程,确保同一分区的消息在同一个线程中按顺序处理。例如:
import java.util.List; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; public class OrderedConsumer { private static final int THREAD_POOL_SIZE = 10; private final KafkaConsumer consumer; private final ExecutorService executorService; private final Map partitionThreads = new ConcurrentHashMap(); public OrderedConsumer(KafkaConsumer consumer) { this.consumer = consumer; this.executorService = Executors.newFixedThreadPool(THREAD_POOL_SIZE); } public void startConsuming() { try { while (true) { ConsumerRecords records = consumer.poll(100); for (ConsumerRecord record : records) { String partition = record.partition() + ""; Thread thread = partitionThreads.get(partition); if (thread == null ||!thread.isAlive()) { thread = new Thread(() -> consumePartition(partition)); partitionThreads.put(partition, thread); executorService.submit(thread); } } } } finally { consumer.close(); executorService.shutdown(); } } private void consumePartition(String partition) { while (true) { ConsumerRecords records = consumer.poll(100); for (ConsumerRecord record : records) { if (record.partition() + "".equals(partition)) { // 处理消息 processMessage(record); } } } } private void processMessage(ConsumerRecord record) { // 具体的消息处理逻辑 System.out.println("Consumed message: " + record.value()); } }三、顺序消费的应用场景
3.1 金融交易场景
在金融交易系统中,订单的创建、支付、退款等操作必须按照顺序进行处理,否则可能会导致资金错误或业务逻辑混乱。通过将同一订单的相关消息发送到同一个分区,并保证分区按顺序消费,可以确保订单操作的正确性和一致性。
3.2 数据库变更日志
在数据库的变更数据捕获(Change Data Capture,CDC)场景中,Kafka 可以用于记录数据库表的增删改操作。为了保证数据库状态的一致性,这些变更日志必须按照顺序消费和应用。利用 Kafka 的顺序消费特性,能够准确地将数据库变更同步到其他系统。
3.3 电商库存管理
在电商系统中,库存的扣减和回补操作需要严格按顺序执行,否则可能会出现超卖或库存数据不准确的问题。将库存相关的消息发送到同一分区并顺序消费,可以保证库存操作的准确性。
Kafka 通过分区特性、生产者分区策略以及消费者消费方式的控制,能够有效地保证消息的顺序消费。在实际应用中,开发者需要根据具体的业务场景,合理配置和使用这些机制,以满足业务对消息顺序性的要求。同时,也要注意顺序消费可能带来的性能影响,在保证顺序的前提下,通过合理的优化措施提高系统的整体性能。
- 固定分区策略:如果业务场景允许,也可以直接将消息发送到固定的分区。例如,在一些简单的日志记录场景中,将所有日志消息都发送到分区 0。







