
MySQL 性能优化 7 大建议:配置、SQL、索引、缓存全覆盖

数据库慢不是天生的,大多数性能瓶颈都源于“配置不当 + 查询低效”。这篇推文带你从架构到底层,系统掌握 MySQL 性能优化的关键路径。
一、合理配置 MySQL 服务参数
MySQL 初始配置并不适合所有业务,尤其是高并发环境下容易成为瓶颈:
✅ 调整 innodb_buffer_pool_size:推荐设置为物理内存的 60%-75%,确保热数据命中内存。
-
作用:决定了 InnoDB 可用于缓存表数据、索引的内存空间。
-
原理:InnoDB 优先从 Buffer Pool 读取数据,命中则避免磁盘 IO。
-
推荐值:约为总内存的 60%~75%(物理机,专用数据库服务)。
[mysqld]innodb_buffer_pool_size=12G
✅ 配置 innodb_log_file_size:写多系统建议加大至 512MB 或以上,减少 checkpoint 频率。
✅ 优化连接管理:如 max_connections、wait_timeout,避免连接泄露拖垮服务。
-
控制最大连接数,防止资源耗尽。
-
建议值视业务并发、连接池配置而定。
✅ 使用性能模式启动:如开启 performance_schema 但避免开启过多采样细节项。
📌 推荐工具:mysqltuner.pl 自动检测配置瓶颈。
二、优化 SQL 编写与使用场景
99% 的慢查询都能归结为 SQL 写法问题:
-
使用 LIMIT 分页优化,结合索引字段大于某 ID,而不是 OFFSET。
-
避免在 WHERE 中使用函数(如 DATE()、LOWER())会导致索引失效。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
SELECT 精准字段,而不是 SELECT *,减少网络开销和内存消耗。
-
大事务拆分为小事务,减少锁等待和回滚成本。
 (图片来源网络,侵删)
(图片来源网络,侵删)🛠 推荐工具:EXPLAIN、SHOW PROFILE、ANALYZE FORMAT=JSON
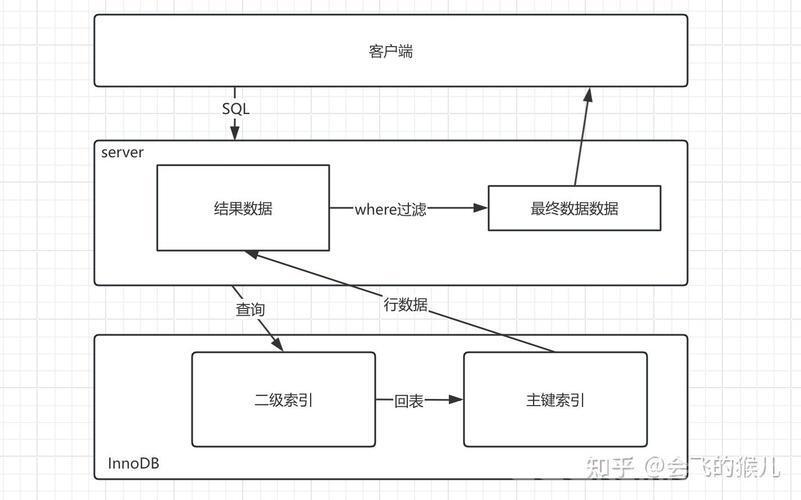
三、建立并维护高效的索引策略
索引设计决定了大部分查询性能的上限:
 (图片来源网络,侵删)
(图片来源网络,侵删)✅ 优先使用 B+ 树索引;避免全表扫描。
✅ 尽量构造覆盖索引(覆盖字段全在索引中)。
-- 覆盖索引:只用索引访问数据 CREATE INDEX idx_user_id_amount ON orders(user_id, amount); SELECT amount FROM orders WHERE user_id = 123;
✅ 索引列顺序遵循“高过滤度 + 等值优先 + 范围在后”原则。
CREATE INDEX idx_a_b_c ON table(a, b, c); -- 能用 a, a+b, a+b+c -- 不能用 b+c(跳过了 a)
✅ 联合索引满足最左前缀匹配原则。
-- 最左匹配才生效 SELECT * FROM t WHERE a = ? AND b = ?; -- ✅ SELECT * FROM t WHERE b = ?; -- ❌(跳过 a)
⚠ 警惕冗余索引和重复索引,影响写性能。
📌 工具推荐:pt-duplicate-key-checker 查冗余索引。
四、表结构设计与分库分表实践【设计规范 + 拆分策略】
表结构不仅决定了可扩展性,也直接影响查询效率和维护成本。
设计规范与原则
1. 拒绝过宽表与过长字段
-
宽表(字段数量 100+)会带来行数据膨胀、更新开销高、内存命中率低。
-
字段类型选择应避免使用 TEXT/BLOB,优先使用 VARCHAR(n)。
2. 字段类型选择要精细化
-
优先选择定长整数(TINYINT / SMALLINT / INT / BIGINT)代替 VARCHAR。
-
避免使用浮点数(FLOAT/DOUBLE)存储金额,推荐使用 DECIMAL(18,2) 或整数分(如以“分”为单位)。
3. 主键策略统一且避免热点
-
自增 ID(AUTO_INCREMENT)适合单机,但在高并发写入时易造成页分裂、锁竞争。
-
推荐使用:分布式唯一 ID(如 Snowflake、UUIDv7、MySQL8 的 UUID_TO_BIN)
分库分表实践指南
当单表数据超过千万级别或 QPS 超过单库承载极限时,需要考虑拆分。
1. 垂直拆分(按模块)
-
拆业务:如 user, order, product 分库
-
目标:减小单库表数量,按功能分离,提升可维护性
2. 水平拆分(按数据)
-
拆数据:如订单表按 user_id % 64 拆成 64 张子表
-
目标:均衡压力、减小单表体积、加快查询响应
3. 实现方式
-
客户端代理:如 ShardingSphere、MyCAT
-
应用层封装:封装分库分表路由逻辑 + 跨库聚合(推荐封装成中间层)
-
高级封装:结合中间件、缓存和归档逻辑(如冷热分离)
五、缓存与数据库配合策略【热数据 + 一致性 + 双写问题】
缓存是一种“加速器”,但使用不当也可能变成“踩雷场”。
缓存常见模式
1. Cache Aside(旁路缓存)
-
应用先查缓存,未命中则查库并写回缓存
-
常见实现:
// 伪代码示意 String key = "user:1001"; String value = redis.get(key); if (value == null) { value = db.query("SELECT name FROM user WHERE id=1001"); redis.set(key, value); } return value;2. Read Through / Write Through(由缓存代理 DB)
-
缓存中间层维护数据生命周期(适用于 Redis Proxy 场景)
3. Write Behind(异步回写)
-
先写缓存,异步持久化到 DB,延迟低但存在数据丢失风险
缓存一致性难题及解决方案
1. 缓存 + DB 双写一致性
-
先更新 DB → 删除缓存(推荐)
-
严禁先删除缓存后写 DB(可能导致缓存穿透)
db.update(...); redis.del(key); // 延迟删除策略可加重试
2. 缓存雪崩
缓存集中失效,导致 DB 被压垮
解决方案:
-
添加缓存过期随机值(防止同时过期)
-
本地缓存 + 分布式缓存组合(如 Caffeine + Redis)
3. 缓存击穿
热点 key 被频繁访问,恰好过期
解决方案:
-
加互斥锁(如 Redisson tryLock)
-
设置永不过期 + 异步更新缓存策略
4. 缓存穿透
查询不存在的 key,频繁打到 DB
解决方案:
-
空值缓存(如设定“空占位符”)
-
布隆过滤器拦截不存在 key
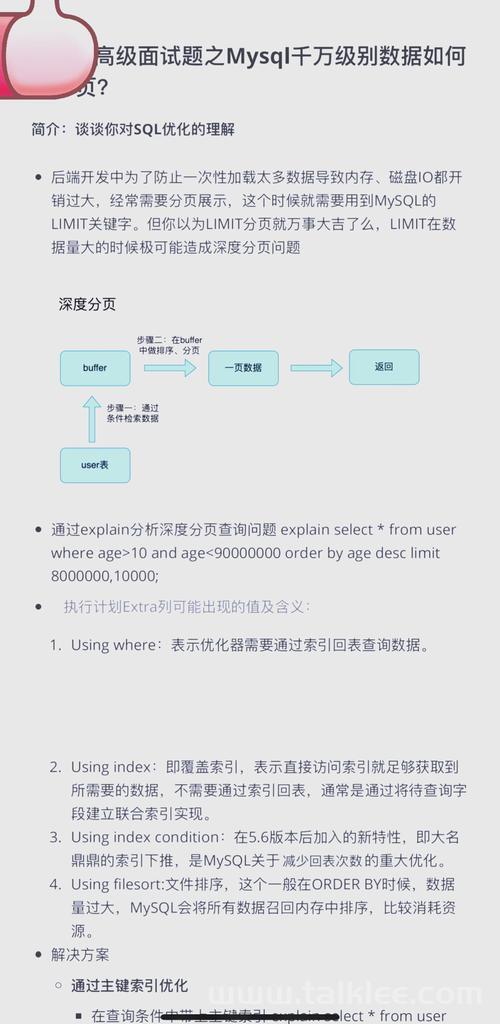
六、慢查询与执行计划优化【EXPLAIN 深度分析 + 索引策略调整】
SQL 是数据库的接口语言,但也是性能瓶颈最常见的来源。慢查询不仅拖垮响应速度,还会压垮数据库 CPU 与 IO。
1. 使用 EXPLAIN 分析执行路径
EXPLAIN SELECT * FROM user WHERE email = 'a@example.com';
常见字段含义:
字段
含义
id
查询中每个 select 子句的标识
select_type
查询类型(SIMPLE / PRIMARY / DERIVED 等)
type
联接类型(ALL > index > range > ref > const)
key
实际使用的索引
rows
预估扫描行数
Extra
额外信息,如 Using filesort、Using temporary 等
优化建议:
-
type != “ALL”,避免全表扫描;
-
rows 尽可能少;
-
Extra 不出现 filesort / temporary;
-
key 显示有效索引命中。
2. 典型慢查询优化思路
1.索引未命中场景
-
条件中函数包裹字段(如 WHERE DATE(created_at) = '2023-01-01') → 使用范围查询替代
-
隐式类型转换(如 id = '123',字段为 INT) → 确保类型匹配
-
多列联合索引未使用最左前缀 → 确保按顺序使用(如 (a,b) 必须从 a 开始)
2.可视化工具辅助
-
使用 MySQL Workbench / Navicat 查看可视化执行计划
-
使用 SHOW PROFILE + ANALYZE 精确分析耗时阶段
七、MySQL 与中间件协同优化【连接池、读写分离、负载均衡】
数据库本身固然重要,但在大型系统中,中间件的使用同样关键。
1. 连接池配置(Druid / HikariCP)
核心参数:
-
maximumPoolSize(并发连接数)
-
connectionTimeout(获取连接超时)
-
idleTimeout(连接空闲回收时间)
建议配置:
-
根据 CPU 核数和业务吞吐量调优并发数
-
启用连接泄漏检测(如 Druid 的 removeAbandoned)
spring.datasource.hikari.maximum-pool-size: 20spring.datasource.hikari.connection-timeout: 3000
2. 读写分离配置
适用于读多写少的系统场景,降低主库压力。
实现方式:
-
客户端中间件(ShardingSphere、MyCAT)
-
数据层代理(阿里 DRC、Vitess)
-
主从库配置示例:
[mysqld]server-id=1log-bin=mysql-binread-only=1 # 只读从库
应用端需基于事务强一致性原则,读写尽量保持在主库中完成或使用强一致读。
3. 多活 + 负载均衡
-
适用于高并发场景,通过代理或中间件将请求均衡分发到多个节点。
-
应用层分发:Spring Cloud Gateway + 灰度规则
-
数据中间层:Vitess、TiDB、Citus
-
数据层代理:ProxySQL + Consul + Keepalived
🔚 总结一句话:
MySQL 优化,不是靠一个参数、一句 SQL 就能解决的,它是数据库设计、索引布局、代码质量、服务配置共同作用的结果。
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-







