
基于 Flink+Paimon+Hologres 搭建淘天集团湖仓一体数据链路

摘要:本文整理自淘天集团高级数据开发工程师朱奥老师在 Flink Forward Asia 2024 流式湖仓论坛的分享。内容主要为以下五部分:
1、项目背景
2、核心策略
3、解决方案
4、项目价值
5、未来计划
01、项目背景
1.1 当前实时数仓架构
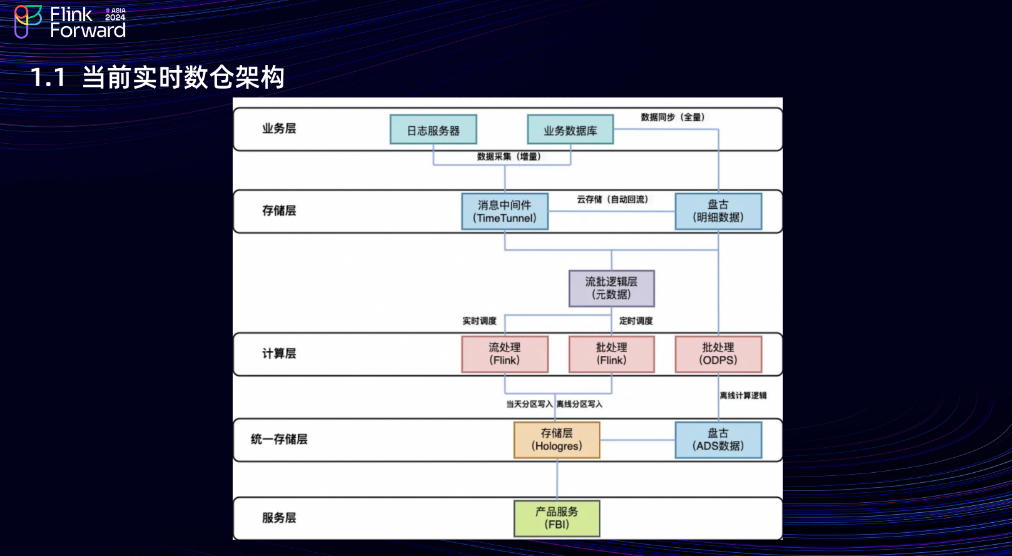
当前的淘天实时架构是从日志服务器和业务数据库采集数据,实时数据采集到 TT (消息队列中间件,对标 Kafka)中,离线数据采集到盘古存储中;在公共层会启一个流批任务做流批计算,实时运行流任务,定时调度批任务;在计算层,实时和离线数据会写到 Hologres(OLAP 组件)中,服务层的数据产品会基于 Hologres 表做数据产品的搭建和数据看板的展示。可以看到,数据直接从 DWD 层写到 ADS 层,没有实时的DWS层,因为TT 不支持去重,Kafka 同样如此。我们希望有一个流批一体的统一存储组件,能把实时的 DWS 层建设好,并且公共层数据可见。
1.2 业务诉求与核心痛点

2024年初以来,业务方主要有两个诉求,第一个是希望有更多的实时数据产品,第二个是业务 BI希望自定义的数据分析。这两个诉求对流批数据开发效率提出一个很大的挑战。当前流批数据链路的核心痛点,第一,流批存储不统一,实时是 TT,离线是 ODPS;第二,实时数据的可见性差,TT 数据对于用户不可见,TT 里面每一条数据都是一条字符串,业务无法直接基于字符串进行 OLAP 分析,虽然TT数据可以导出到离线分析,但数据时效性会降低到小时级或天级,并且有开发成本;第三,没有实时 DWS 中间层;第四,中间的流批一体开发效率比较低,推广比较困难,相关的工具化也比较弱;第五,没有一个高效易用的分钟级近实时数据加工方案。
02、核心策略
2.1 Paimon 技术引入

我们引入了Paimon 的技术,期望基于 Paimon 构建湖仓公共层的流批一体存储,统一流批数据口径,并且提高数据的可复用性。从系统架构角度,我们拿 Paimon 和 TT 做了对比,可以看到TT的性能可以达到 6000 万每秒,这个是业务的峰值,非TT系统峰值。Paimon 底层是盘古 HDFS,对于非主键表峰值可达 4000 万/秒,而主键表如 Page 日志,峰值可达 1200 万/秒,虽然峰值比不上 TT,但对于业务已经够用。稳定性方面,TT 用了很多年,几乎没有稳定性问题。Paimon 于今年开始使用,经历了 618 和双 11 大促等高并发场景,整体运行稳定。扩展性方面,TT 和 Paimon 都是分布式的架构,易扩展。TT 支持日志采集和数据的 Binlog 接入,Paimon 本身不具备这些功能,通过和FlinkCDC 结合可以支持这些功能。

从业务角度,当前 TT 的成本高,而Paimon 只收取存储费用,实时订阅不收费,存储在 HDFS 中,成本相对较低;在时效性方面,TT 更优是毫秒级,Paimon 是分钟级;TT 实时数据存储和离线ODPS存储,不是一个存储组件,在建映射表时需要逐个字段对齐离线表和 TT 的 Schema,比较费时费力,Paimon是流批一体存储,流批数据存储在一张底表中,不需要对齐 Schema 和口径,可以提高开发效率;TT不支持OLAP分析,Paimon 目前支持 Hive,Hologres OLAP分析和 Flink 查询;TT 需要全量拉取数据反序列化,把数据解析出来再根据某个字段过滤,Paimon 支持分区的存储,并且存储的数据有 Schema,可以使用分区过滤,特别像一些回追数据、分流的场景,用 Paimon 只需要读取分流或者当天对应的分区,不用回追更早的历史数据,以达到非常精准的过滤。
2.2 Hologres 动态表技术引入

第二个技术是Hologres,我们使用 Hologres 动态表做仓的建设。基于 Hologres 构建全增量一体的数仓分层,提升流批一体开发的效率,降低资源消耗。Hologres 支持增量计算,分钟级更新数据,可以满足业务的近实时需求;支持 Serverless 执行,将Hologres批任务提交到一个极大的共享资源池,批数据调度和回刷极快,同时支持自动规避机器的热点,显著提升运维效率;湖仓一体是指 Hologres 已实现直接读取 Paimon 的湖表数据,而数据湖本身具备开放性,可以实现高效的近实时的湖仓架构方案。
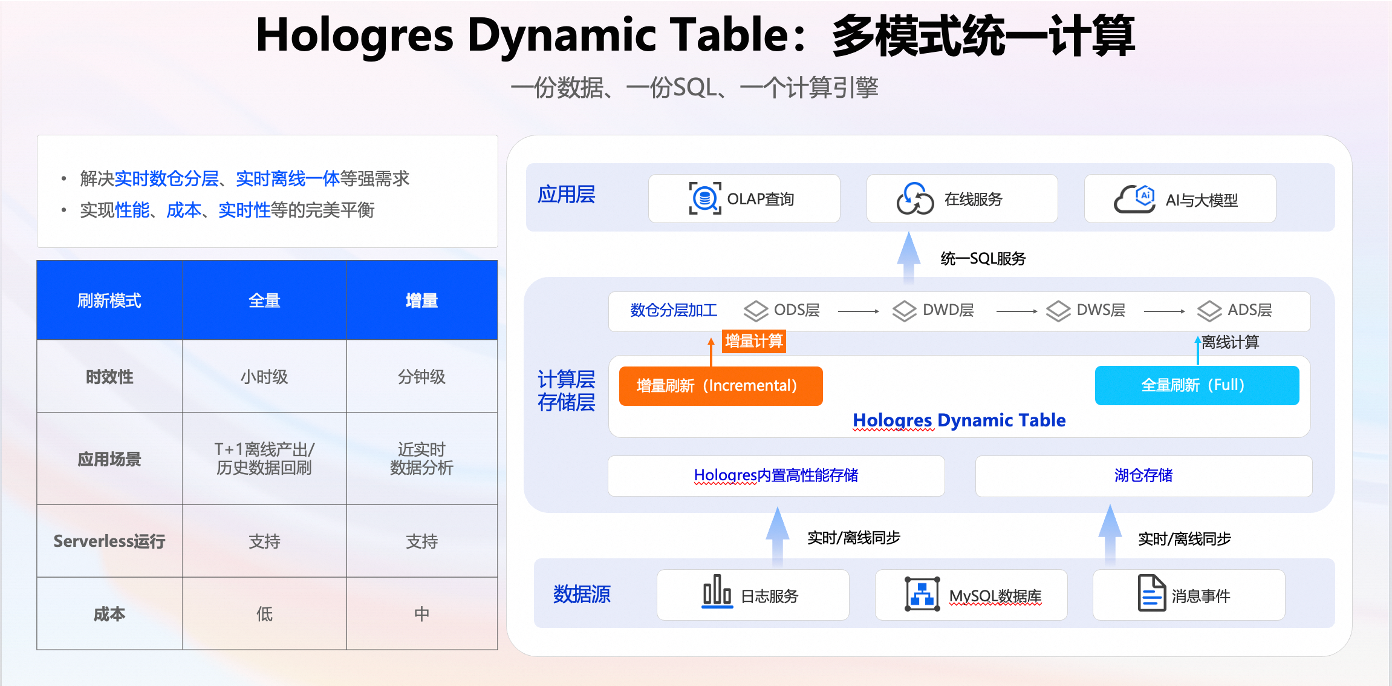
这是 Hologres 的一张图,从最下面的数据源采集,采集完之后导入到存储,在公共层用 Paimon 完成搭建后,在数仓的计算层主要用 Hologres 的增量更新和全量更新来计算,计算结果也会存储在 Hologres 表中。基于Hologres 表做一些 OLAP 的查询,在应用层服务于在线服务和 AI 大模型。
2.3 湖仓一体能力建设

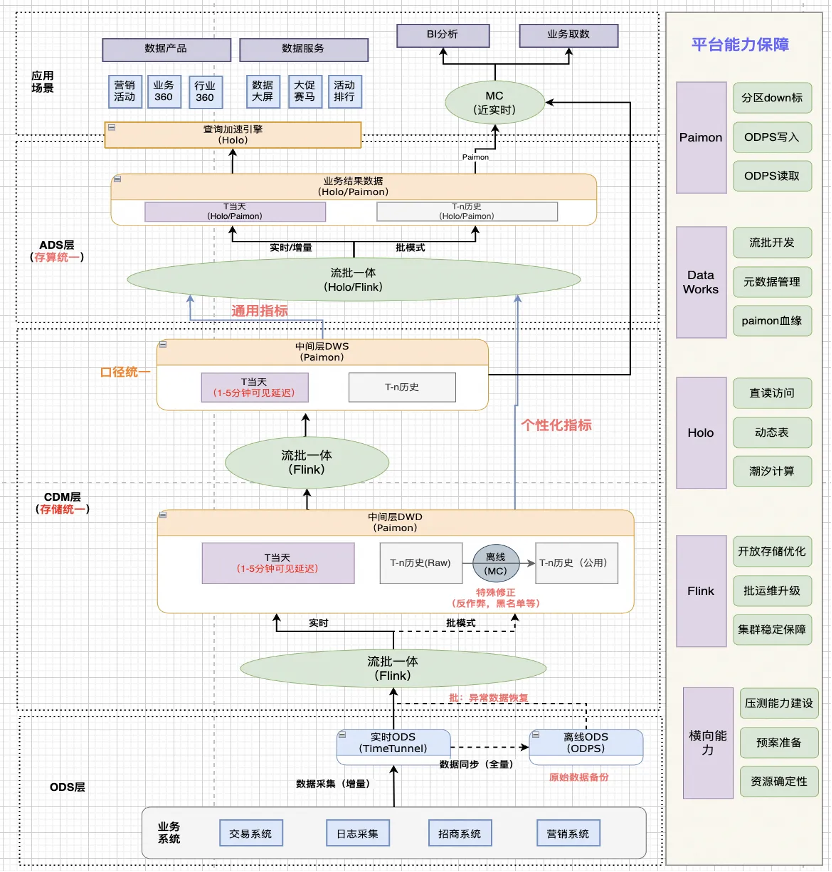
湖仓一体的能力建设是指基于 Paimon 构建湖仓公共层,然后基于Hologres 构建全增量一体的湖仓分层,还包括湖仓流批一体的能力建设、丰富的应用场景以及相关的平台保障能力的建设。
03、解决方案
3.1 公共层入湖方案架构

关于公共层入湖,首先做一个环境验证,开始排期开发搭建链路,最后在双 11 做大促验证。公共层入口的范围主要包括交易,日志、预售架构和流量通道等

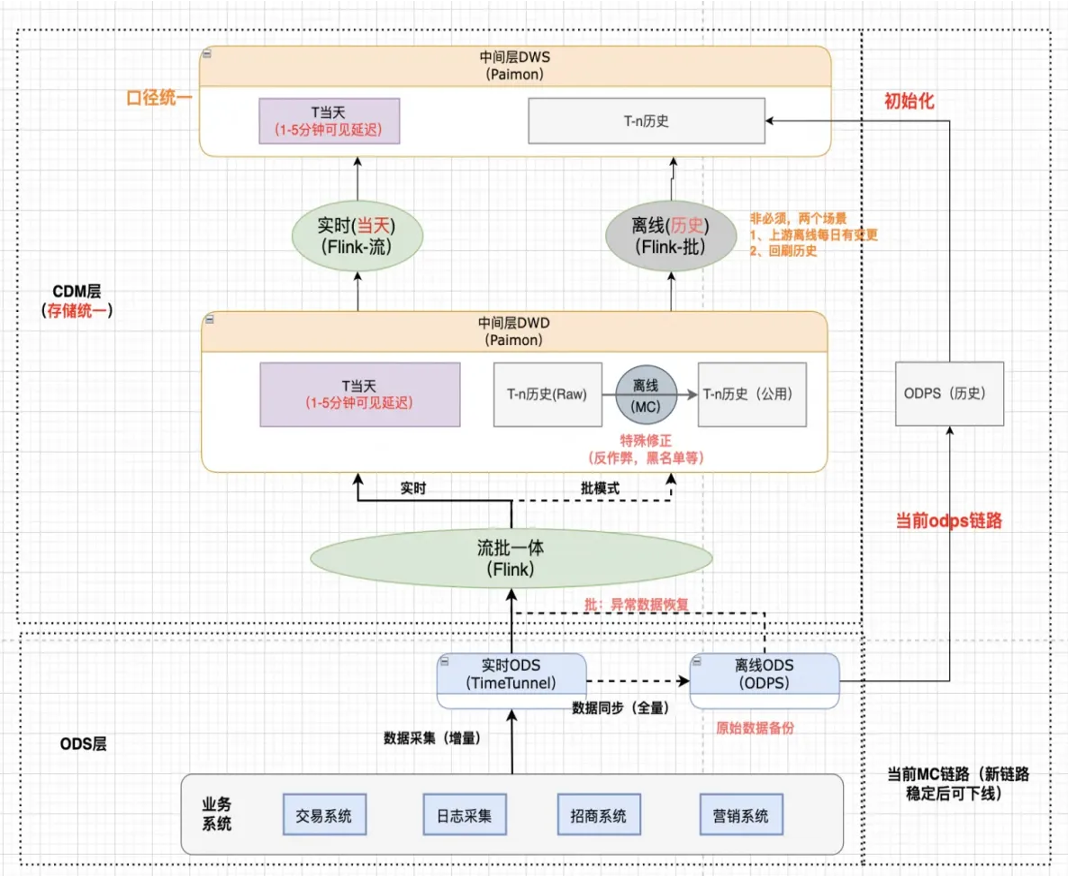
Paimon 的一个功能是数据分支功能—Branch,离线表默认是存储在 Master 分支,实时的 Paimon 表默认存储在 RT 分支,对于下游的业务,透出的是同一张 Paimon 表,业务在使用这张表的时候,默认会读 Master 分支,即离线数据。如果离线数据读不到,会去 RT分支上读实时的数据,可以解决实时数据延迟覆盖离线数据的问题。同时,Paimon支持不同with表参数的能力。比如实时场景,可能需要一张去重表,离线场景,可能就只需要append表。
3.2 爱橙交易域公共层入湖
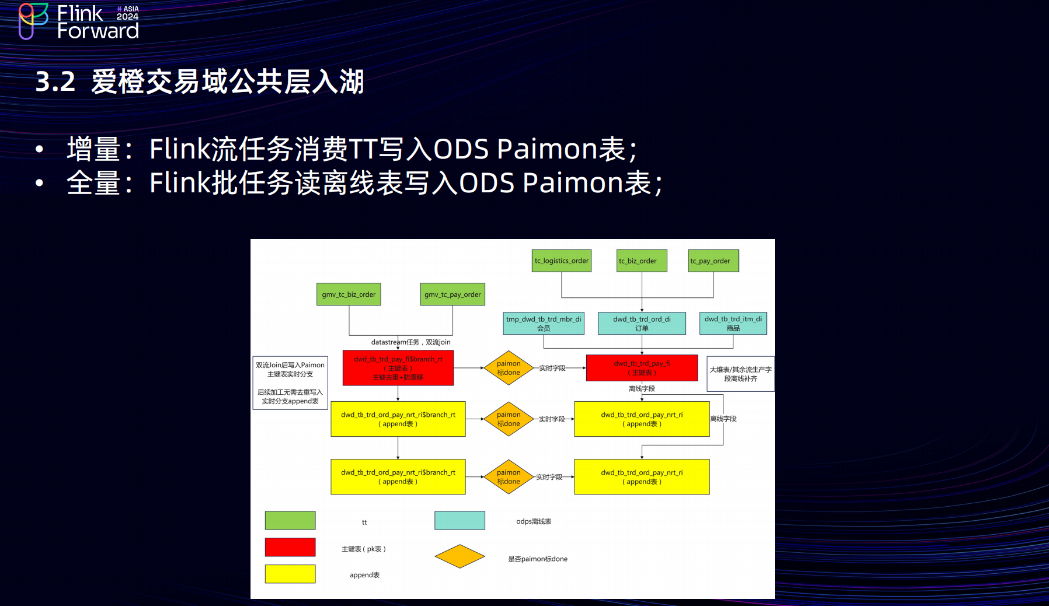
在爱橙的公共层入湖链路中,增量用 Flink 流任务消费 TT 写到 ODS Paimon 表当中,全量任务用 Flink 批任务读离线表,写入 ODS Paimon 表中。架构图最上面的是 TT,TT 会导到 ODPS 离线表中,然后会基于 Paimon 建PK表做数据去重。
3.3 爱橙流量域公共层入湖

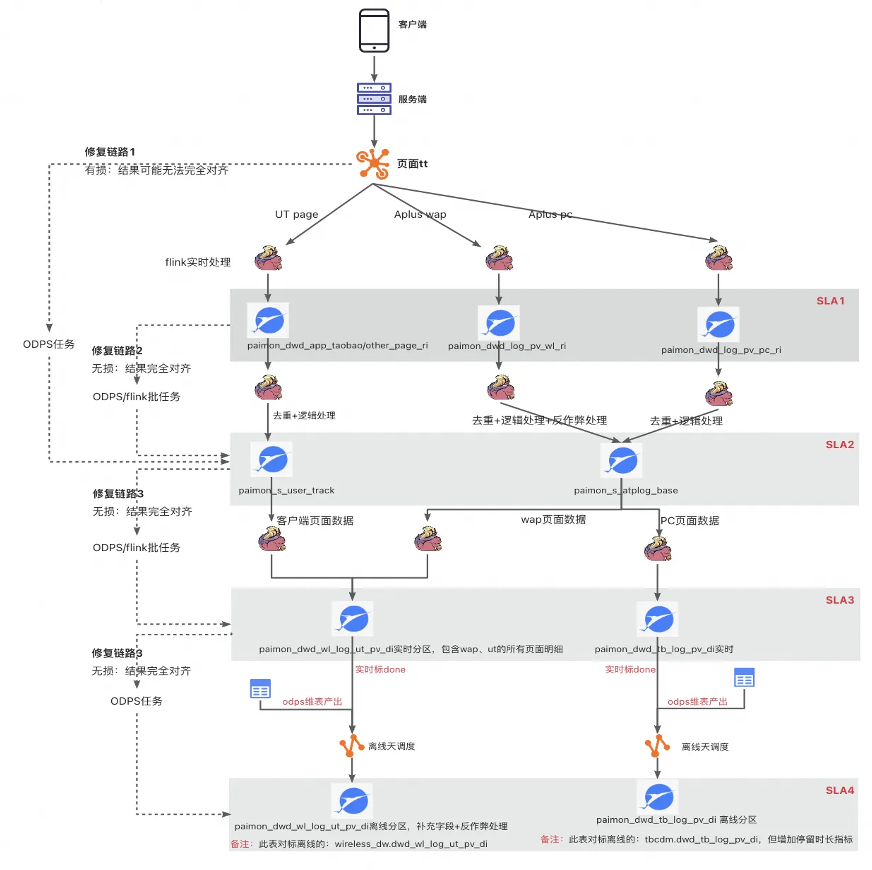
爱橙的流量域相对于交易域,数据要大很多,并且流量域的场景也更加复杂。我们把流量域分成四种服务协议等级来做保障,分别是 SLA1 到 4。第一种支持实时和离线,时效性在五分钟以内,和对应的 TT 完全对齐;第二种,实时表和离线表测会有一些差异,缺少反作弊过滤;第三种缺少一些反作弊的维表过滤还有排序相关的一些字段;第四种只支持离线,和对应的离线表完全对齐。
在流量域公共层的架构图中,首先是数据采集,从前端埋点采集到服务端,然后写到 TT 中,主要是用 Flink 做一些计算,分别写到不同的 Paimon 明细表中。因为流量域的日志字段比较复杂,比如一张流量表当中有 100 个字段,可能有 95 个字段是实时产出的,有另外五个字段,像反作弊和排序的字段不能实时产出,就会起一条修复的链路,用离线去回补这五个字段,反作弊和排序只能在离线算。实时也会做去重的逻辑处理,最后的数据写到 DWD 层的 Paimon 表中,下游业务会基于 Paimon 表来建设 Paimon 的 DWS 层。
3.4 淘天公共层入湖
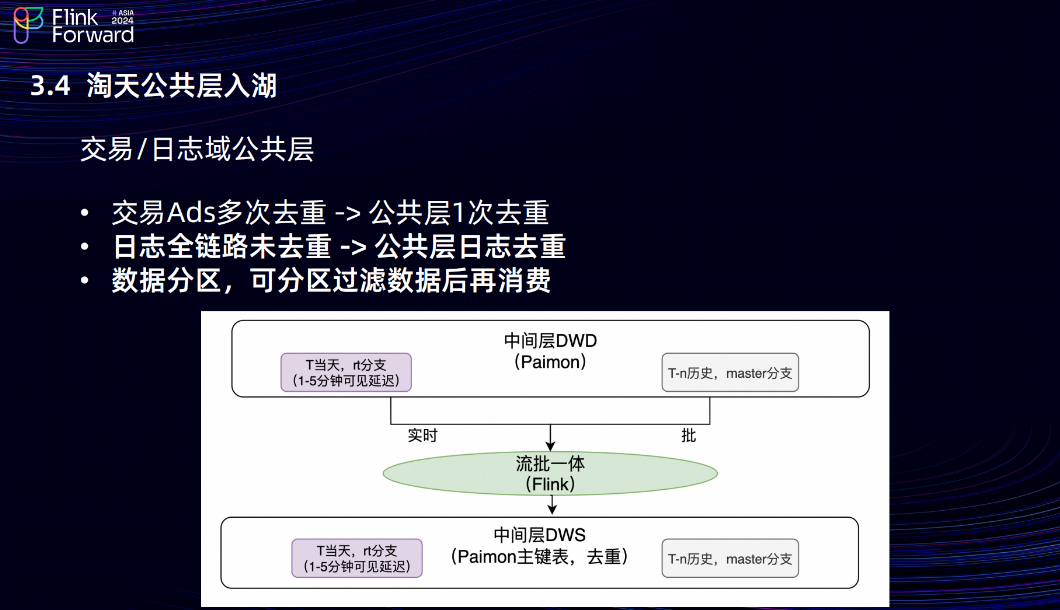
然后是淘天公共层的入湖。淘天公共层的上游是爱橙,主要把交易域和日志域的公共层入湖,我们做的工作主要分三点。第一点,以前的交易实时公共层没有去重,下游每一个 ADS 任务在消费 TT 的时候都要单独做一次去重;我们把交易日志放在公共层用paimon去重,只需要去重一次,1次公共层去重抵得上N次ADS去重,收益非常高,Flink 比较难解的一个场景是去重的时候 State 如果过大任务会不稳定,这也有效提高了ADSFlink任务的稳定性;第二个是日志链路,之前全链路日志都没有去重,这会产生一个问题,如果日志的实时任务重启,对于下游的业务数据会重复,体现在数据产品上,如果上个小时对比昨天的数据增长 5%,下个小时差不多也增长 5%,但当前重启的小时会增长百分之十几。基于 Paimon 在公共层做日志去重,收益是不管任务重启多少次,下游消费的数据都不会重复,都是exactly-once的语义。最后是数据的分区,Paimon 支持数据的分区,可以分区过滤数据后再消费,像一些分流的场景也可以把分流的 Tag 作为一个分区,下游消费的时候就不需要反序列化全量数据,只需要消费对应 Tag 的数据就可以,节省下游消费任务的计算资源。
3.5 基于 Hologres Dynamic Table 构建 ADS 近实时湖仓分层

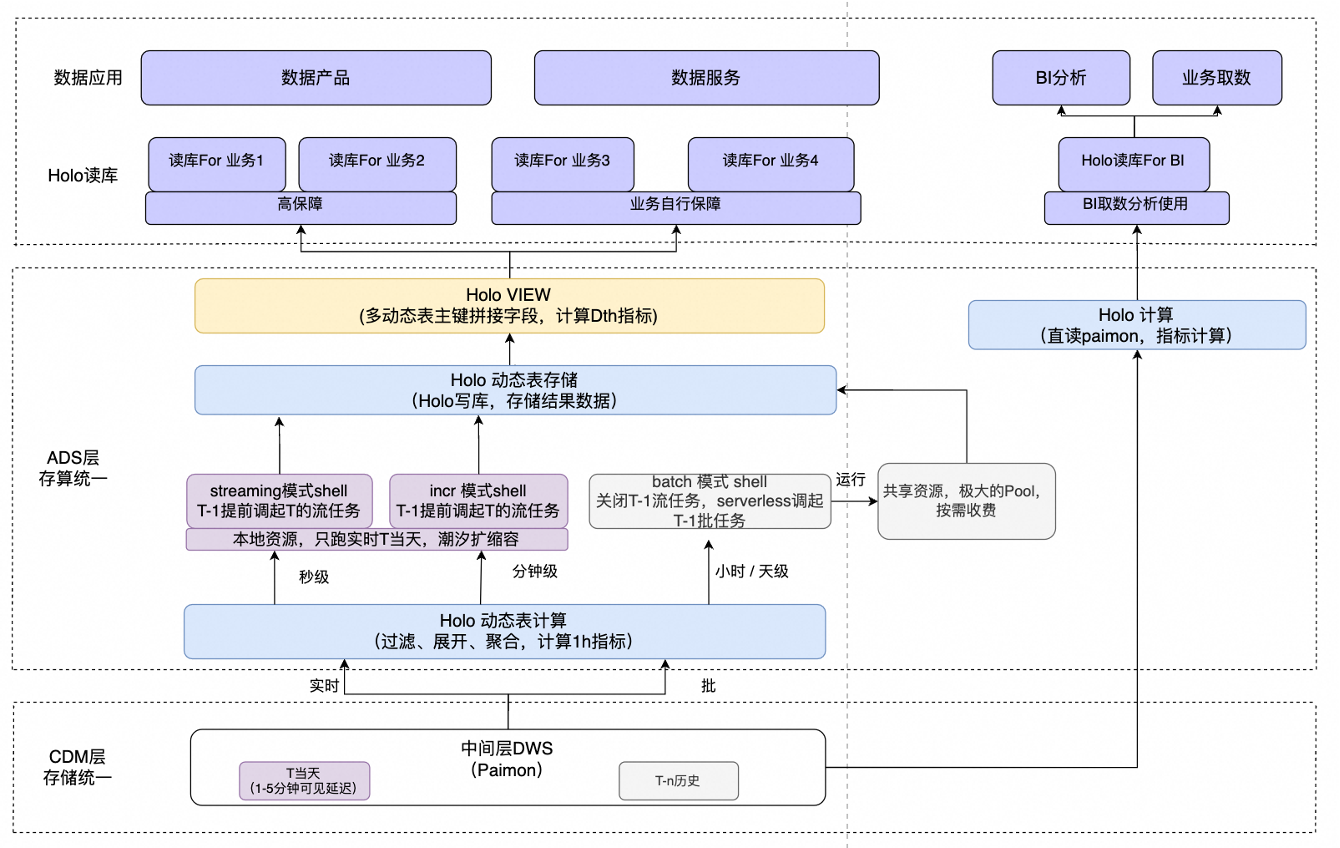
我们基于 Hologres 的动态表来构建 ADS层近实时的湖仓分层。Hologres 的外表支持直读DWS层 Paimon表,并且可以做分钟级的增量计算和离线场景的批计算,数据会在 ADS 层做动态表的过滤,展开,聚合和计算,分为增量和批两种方式,增量任务用独占的本地集群运行,批任务会提交一个极大的共享资源池中,共享资源池按需收费,并且它的资源比较大,可以用整个集群的资源瞬时跑批任务,运行速度极快,计算结果存储在动态表中,然后用Hologres 视图拼接多个动态表字段,视图的作用是方便展示和开窗计算 DTH 指标。业务基于 Hologres 表做读写分离,分为高保障的和业务自行保障两个等级。业务在读库上搭建数据产品和数据服务。
Hologres 已经支持直读 Paimon。之前如果业务 BI 有一些需求提过来,需要数据开发搭建一条完整的数据链路,在数据产品上展示;Hologres 支持直读 Paimon 后,如果业务 BI 有一些比较自定义的需求,并且需求不是很复杂,他完全可以自己通过 Hologres 直读 Paimon 的中间层DWS 表,自己做一些简单的数据开发和分钟级报表搭建,这样可以极大的节省实时数据研发的成本。同时,对于 BI 的取数效率也是巨大的提高。
04、项目价值

- 数据时效性提升:中间层产出效率提升,流量表产出时效提前40-60分钟;
- 实时开发运维效率提升:流批一体,实时开发和运维效率提升50%以上,开发验证时长从5天->2天,回刷速度提高15倍;
- 实时数据使用门槛下降:业务和BI同学获取中间层分钟级实时数据以支持临时实时分析场景;
- 成本下降:存储换用更廉价的hdfs,实时dws建设可降低tt重复读取成本和下游去重成本;
05、未来计划
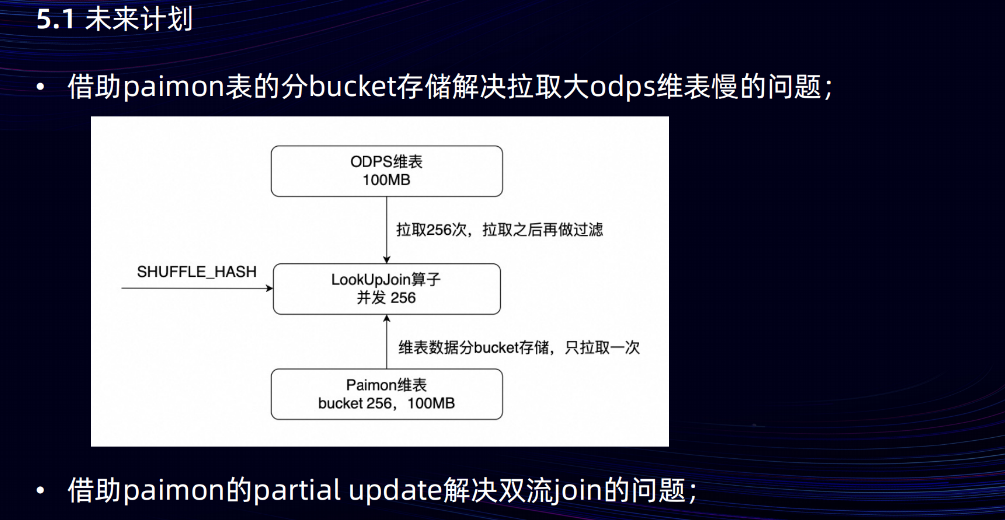
Paimon 表目前在双 11 大促取得的效果比较好,后面会在集团内继续大力推广。第一部分是希望借助 Paimon 表的分 Bucket 存储来解决拉取大ODPS维表 比较慢的问题。Flink 任务在重启时,对于ODPS大维表, LookUpJoin算子是先拉取再过滤,全量数据会拉取多次,对于Paimon维表,LookUpJoin算子只拉取join key对应bucket的数据,全量数据只拉取一次,任务重启时间从二三十分钟提升到秒级。
第二个是希望借助 Paimon 的 Partial Update 解决双流 Join 的问题。

第三个是希望在 Hologres 的全增量直读湖基础上,新增全增量的写湖能力,主要是 Paimon 相关的和 OLAP 引擎的打通,也是增强的 Paimon 的开放性,扩展 Hologres 的动态表在近实时的湖仓分层应用的场景;第四个是希望后面探索用 Fluss 做流存储的组件,希望可以用它代替像 Kafka,TT 等消息队列组件;第五个,后面会沉淀新一代的湖仓数据架构,在集团内大范围推广。基于目前已经在 618 和双 11 做的Paimon 探索,整体表现符合预期,甚至超出预期,在集团内已具备大范围推广基础。







