
大模型之Spring AI实战系列(三):Spring Boot + OpenAI 实现聊天应用上下文记忆功能

系列篇章💥
| No. | 文章 |
|---|---|
| 1 | 大模型之Spring AI实战系列(一):基础认知篇 - 开启智能应用开发之旅 |
| 2 | 大模型之Spring AI实战系列(二):Spring Boot + OpenAI 打造聊天应用全攻略 |
| 3 | 大模型之Spring AI实战系列(三):Spring Boot + OpenAI 实现聊天应用上下文记忆功能 |
目录
- 系列篇章💥
- 前言
- 一、开发环境准备
- (一)Java 版本要求
- (二)Maven 构建工具
- (三)OpenAI API 密钥
- 二、POM依赖引入
- (一)Spring AI与OpenAI集成依赖包
- (二)SpringAI相关依赖包版本管理
- 三、配置文件详解
- 四、核心代码详解
- (一)Application启动类
- (二)带上下文记忆的聊天控制器
- (三)上下文聊天接口 `/context`
- 五、上下文记忆机制原理剖析
- (一)什么是上下文记忆?
- (二)如何实现上下文记忆?
- 六、优化建议与进阶思路
- (一)控制上下文长度
- (二)使用 Redis 或数据库持久化上下文
- (三)引入角色设定与系统提示词
- 七、部署与测试
- (一)启动应用
- (二)测试接口
- 八、结语
前言
在上一篇文章中,我们介绍了如何使用 Spring AI 框架与 OpenAI 进行集成,并通过 ChatClient 和 OpenAiChatModel 实现了基础对话、流式对话、多提供商适配等功能。然而,在实际的企业级应用中,仅仅实现单轮对话是远远不够的。
为了让 AI 聊天机器人具备“记忆力”,能够理解上下文并进行连贯的多轮对话,我们需要引入上下文管理机制。本文将基于 spring-ai-openai-context 示例项目,详细介绍如何构建一个支持上下文记忆的 OpenAI 聊天服务。
一、开发环境准备
(一)Java 版本要求
本项目采用Java 17进行编译和运行,请务必确保你的开发环境已成功安装JDK 17。你可以在命令行中输入以下命令进行检查:
java -version
输出应类似如下内容:
openjdk version "17.0.8" 2023-07-18 OpenJDK Runtime Environment (build 17.0.8+7) OpenJDK 64-Bit Server VM (build 17.0.8+7, mixed mode, sharing)
(二)Maven 构建工具
确保你已安装 Maven 并配置好环境变量:
mvn -v
输出应类似如下内容:
Apache Maven 3.8.8 (4c87b05d9aedce574290d1acc98575ed5eb6cd39) Maven home: D:\Program Files (x86)\apache-maven-3.8.8 Java version: 17.0.12, vendor: Oracle Corporation, runtime: D:\Program Files\jdk-17.0.12 Default locale: zh_CN, platform encoding: GBK OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
(三)OpenAI API 密钥
你需要注册 OpenAI 官网 获取 API Key(国内可以直接使用中转地址),并设置为环境变量:
export OPENAI_API_KEY="your_openai_api_key" export OPENAI_API_URL="https://api.openai.com/v1"
注意:出于安全考虑,不建议将密钥硬编码在代码中,推荐使用环境变量或配置中心进行管理。
二、POM依赖引入
(一)Spring AI与OpenAI集成依赖包
org.springframework.ai spring-ai-starter-model-openai此依赖包用于实现Spring AI与OpenAI的集成,为后续与OpenAI API进行交互提供了必要的支持。
(二)SpringAI相关依赖包版本管理
版本管理
org.springframework.ai spring-ai-bom 1.0.0-SNAPSHOT pom import部分通过引入spring-ai-bom,实现了对SpringAI相关依赖包版本的统一管理。这样,在项目中使用Spring AI相关依赖时,无需在每个依赖声明中单独指定版本号,只需遵循spring-ai-bom中定义的版本即可,极大地简化了依赖管理工作,同时确保了项目中依赖版本的一致性和稳定性。
三、配置文件详解
在配置文件application.yml中我们需要进行openai API相关配置:
server: port: 8882 spring: ai: openai: base-url: ${OPENAI_API_URL} api-key: ${OPENAI_API_KEY} chat: options: model: gpt-3.5-turbo temperature: 0.7- base-url 和 api-key 从环境变量注入,这种方式增强了配置的安全性,避免了密钥在代码中硬编码带来的风险。
- model 指定了默认使用的模型版本,这里设置为gpt-3.5-turbo,开发者可以根据实际需求进行调整。
- temperature 用于控制输出的随机性,数值越高,生成的回复越随机,取值范围通常在0到1之间。
四、核心代码详解
(一)Application启动类
这是 Spring Boot 的启动类,非常简洁:
@SpringBootApplication public class SpringAiApplication { public static void main(String[] args) { SpringApplication.run(SpringAiApplication.class, args); } }Spring Boot会自动扫描并加载所有的Controller、Service等Bean,为项目的启动和运行奠定基础。它通过@SpringBootApplication注解开启了Spring Boot的自动配置功能,使得项目能够快速搭建起一个完整的Spring应用环境。
(二)带上下文记忆的聊天控制器
该类使用 OpenAiChatModel 接口来实现带有上下文记忆的聊天功能,适用于需要多轮对话的场景。
@RestController public class ContextChatController { // 历史消息列表,用于存储聊天的历史记录 private static List historyMessage = new ArrayList(); // 历史消息列表的最大长度,用于限制历史记录的数量 private static final int maxLen = 1000; // 聊天模型,用于生成AI的回复 private final OpenAiChatModel chatModel; @Autowired public ContextChatController(OpenAiChatModel chatModel) { this.chatModel = chatModel; } // 方法实现省略... }(三)上下文聊天接口 /context
@GetMapping("/context") public AssistantMessage context(@RequestParam String prompt) { historyMessage.add(new UserMessage(prompt)); if (historyMessage.size() > maxLen) { historyMessage = historyMessage.subList(historyMessage.size() - maxLen - 1, historyMessage.size()); } ChatResponse chatResponse = chatModel.call(new Prompt(historyMessage)); AssistantMessage assistantMessage = chatResponse.getResult().getOutput(); historyMessage.add(assistantMessage); return assistantMessage; }- 将用户输入作为 UserMessage 添加到历史记录中。
- 如果历史记录超过最大长度(默认 1000 条),则截取最近的记录。
- 使用 Prompt 构造器将整个历史记录封装后发送给 OpenAI。
- 获取 AI 回复后,将其作为 AssistantMessage 加入历史记录。
- 返回值为 AssistantMessage,包含完整的回复内容。
五、上下文记忆机制原理剖析
(一)什么是上下文记忆?
在自然语言处理中,上下文是指对话过程中积累的信息,它决定了当前语句的理解方式。例如:
- 用户说:“他昨天去了哪里?”
- 如果没有上下文,AI 不知道“他”是谁;
- 如果前面有提到“张三是我的朋友”,那么“他”就指的是“张三”。
因此,上下文对于构建连贯的多轮对话至关重要。
(二)如何实现上下文记忆?
在 Spring AI 中,可以通过向 Prompt 对象中传入多个 Message 实例(如 UserMessage, AssistantMessage, SystemMessage)来构造完整的历史上下文。
示例代码如下:
Prompt prompt = new Prompt(List.of( new SystemMessage("你是一个乐于助人的助手"), new UserMessage("你好"), new AssistantMessage("你好!有什么我可以帮助你的吗?"), new UserMessage("我今天心情不好") ));这样,模型就能基于完整的上下文进行推理并给出更准确的回应。
六、优化建议与进阶思路
(一)控制上下文长度
虽然 GPT 模型支持较长的上下文(如 GPT-4 支持 32k tokens),但每次请求携带过多历史数据会增加成本和延迟。建议:
- 设置合理的最大历史记录条数(如 100 条);
- 在每次调用时只保留最近的若干条记录;
- 或者采用“摘要 + 最近记录”的混合策略。
(二)使用 Redis 或数据库持久化上下文
目前我们的示例中使用的是内存中的静态 List,这意味着重启服务后上下文会丢失。为了实现真正的“长期记忆”,可以考虑:
- 使用 Redis 缓存每个用户的对话历史;
- 使用数据库持久化用户 ID 对应的上下文;
- 结合 Spring Session 或 JWT 实现身份识别,绑定上下文。
(三)引入角色设定与系统提示词
可以在每次对话开始前添加一条 SystemMessage,设定 AI 的人格、语气、风格等:
new SystemMessage("你是一个幽默风趣的朋友,喜欢讲笑话");这样可以让 AI 的回复更具个性化和一致性。
七、部署与测试
(一)启动应用
可以直接基于IntelliJ IDEA启动并运行Spring Boot应用程序,也可以进入项目根目录,执行 mvn clean package 进行打包,之后采用 java -jar xxx.jar 命令进行部署运行。运行成功后,应用将在 http://localhost:8882 启动。

(二)测试接口
你可以使用 Postman、curl 或浏览器访问以下接口:
-
上下文聊天:GET /context?prompt=你好
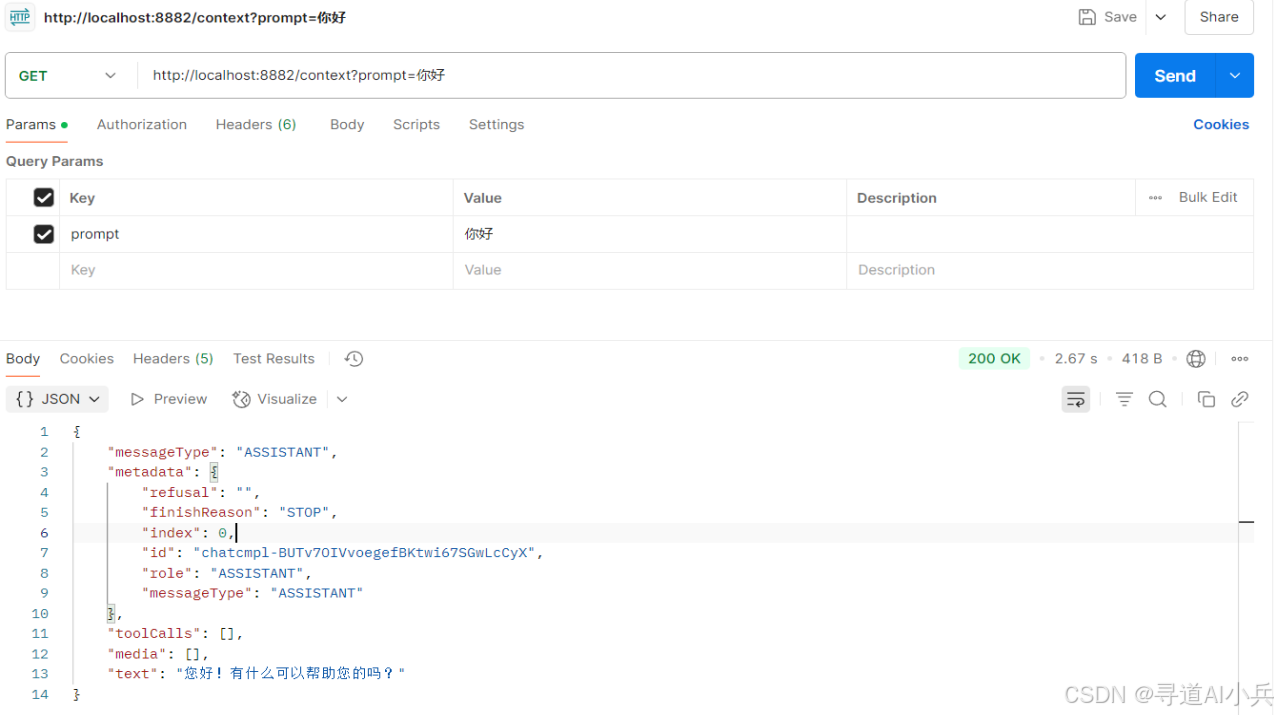
-
继续对话:GET /context?prompt=请写一首5言绝句
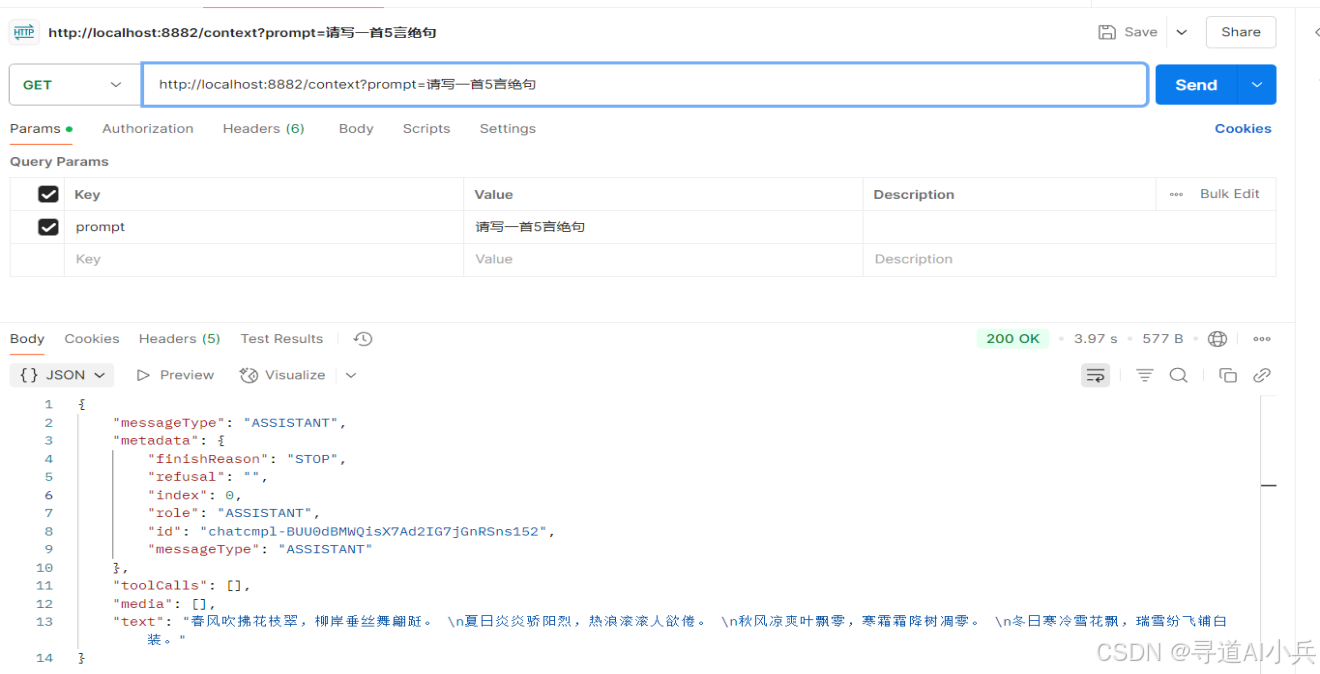
-
再次提问:GET /context?prompt=这首诗写的真好,请再输出一遍!
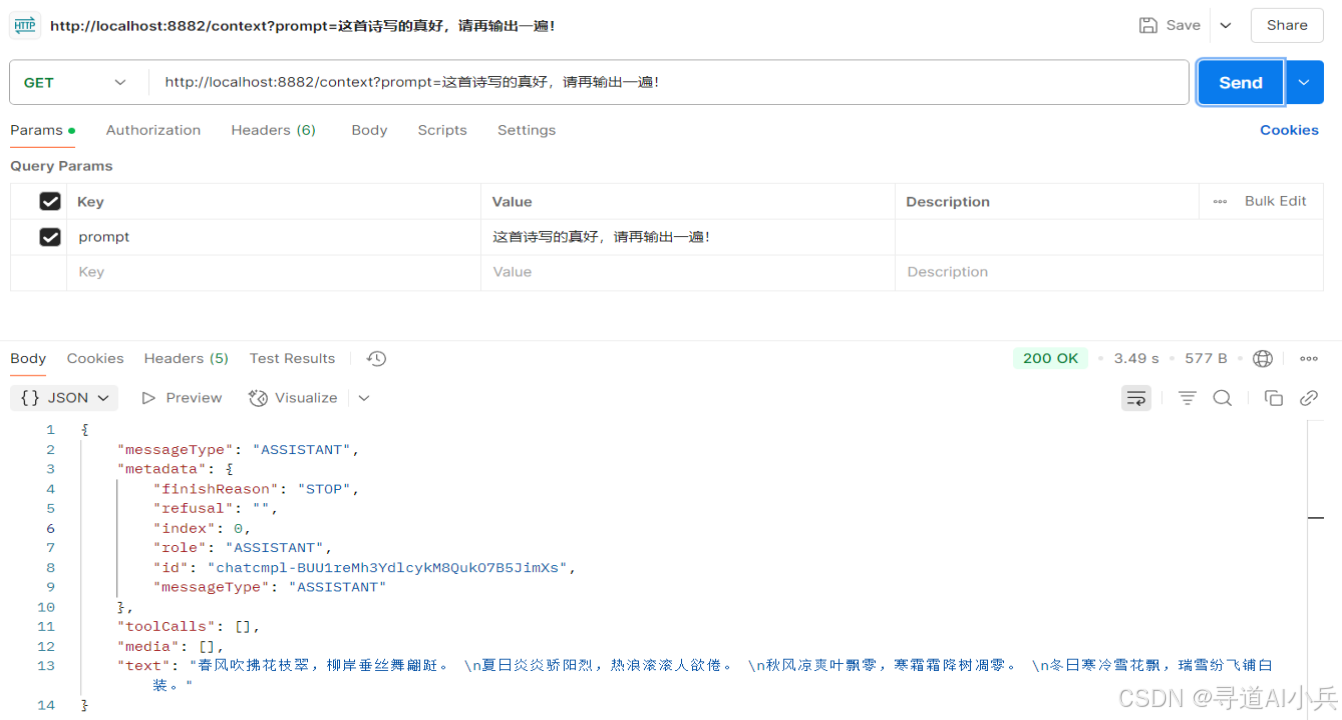
观察是否能正确记住之前的对话内容,并做出连贯的回应。
八、结语
通过本文的深入实践和详细讲解,我们可以构建一个具备上下文记忆能力的 OpenAI 聊天应用。在这个过程中,我们不仅掌握了如何在 Spring AI 中利用 OpenAiChatModel 和 Prompt 实现多轮对话管理的核心技术,还学习了如何通过优化上下文长度、持久化上下文信息以及引入角色设定等方法来提升应用的性能和用户体验。这些技术知识和实践经验将为我们在后续开发更复杂、更智能的 AI 交互功能提供坚实的基础和宝贵的参考。
在人工智能技术快速发展的今天,聊天应用的上下文记忆功能只是众多创新应用场景的一个缩影。随着技术的不断进步和创新,我们有理由相信,未来的人工智能聊天应用将变得更加智能、更加贴近人类的交流方式,为人们的生活和工作带来更多的便利和惊喜。
若您对本文介绍的技术内容感兴趣,希望进一步探索和实践,欢迎关注我,通过私信的方式与我联系,获取完整的项目代码,开启您的 Spring AI 开发之旅。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!
-







