
【小米拥抱AI】小米开源 MiMo-7B-RL-0530


更新日志
[2025.05.30] 在强化学习训练过程中,通过持续扩大训练窗口尺寸(从32K提升至48K),MiMo-7B-RL-0530模型在AIME24基准测试上的表现持续提升,最终超越DeepSeek R1模型的性能水平。
| Benchmark | MiMo-7B-RL | MiMo-7B-RL-0530 |
|---|---|---|
| MATH500 (Pass@1) | 95.8 | 97.2 |
| AIME 2024 (Pass@1) | 68.2 | 80.1 |
| AIME 2025 (Pass@1) | 55.4 | 70.2 |
| Code | ||
| LiveCodeBench v5 (Pass@1) | 57.8 | 60.9 |
| LiveCodeBench v6 (Pass@1) | 49.3 | 52.2 |
| STEM | ||
| GPQA-Diamond (Pass@1) | 54.4 | 60.6 |
| General | ||
| Alignbench1.1 (Evaluated by GPT4.1) | 6.9 | 7.4 |
简介
目前,包括开源研究在内的大多数成功强化学习(RL)成果都依赖于相对较大的基础模型(例如320亿参数模型),尤其是在提升代码推理能力方面。此外,学界普遍认为在小型模型中同时实现数学与代码能力的均衡提升具有挑战性。然而,我们认为强化学习训练出的推理模型之效能,本质上取决于基础模型与生俱来的推理潜力。要充分释放语言模型的推理潜力,不仅需要关注训练后的优化策略,更需要针对推理能力定制预训练方案。
本项研究推出的MiMo-70亿模型系列,是为推理任务而从头训练的模型体系。基于MiMo-70亿基础模型的强化学习实验表明,该模型展现出非凡的推理潜力,其表现甚至超越参数规模大得多的320亿参数模型。我们还对冷启动的监督微调(SFT)模型进行强化学习训练,最终获得的MiMo-70亿强化学习版本,在数学与代码推理任务上均展现出卓越性能,其表现可与OpenAI o1-mini相媲美。
(注:根据技术文档惯例,“32B"译为"320亿参数”,“7B"译为"70亿参数”;“cold-started SFT model"采用意译处理为"冷启动的监督微调模型”;专业术语如RL/SFT保留英文缩写并首次出现时标注全称;"born for reasoning tasks"转译为"为推理任务而…的模型体系"以符合中文科技文献表达习惯)
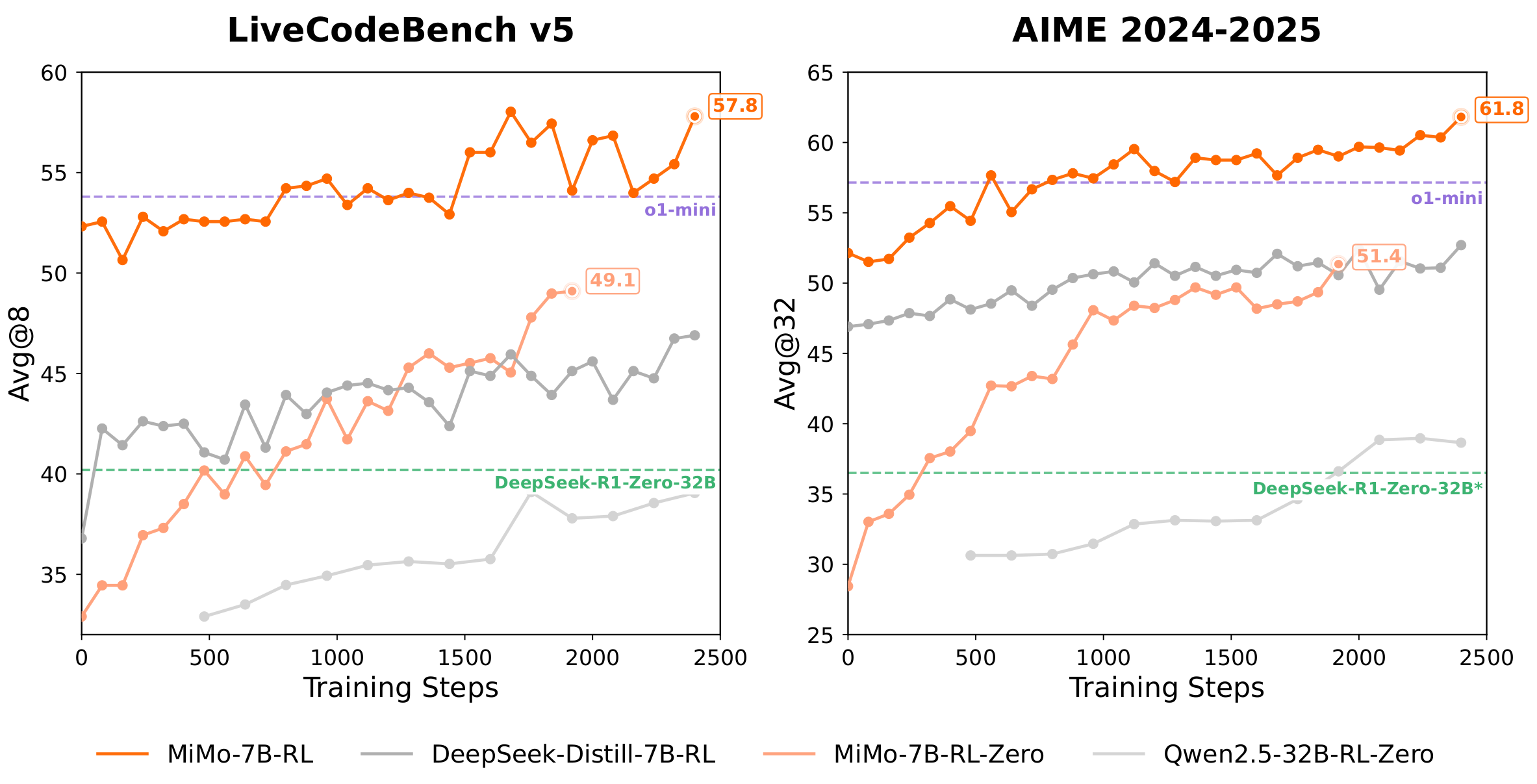
我们开源了MiMo-7B系列模型,包含基础模型的检查点、监督微调模型、从基础模型训练的强化学习模型,以及从监督微调模型训练的强化学习模型。我们相信这份报告连同这些模型将为开发具有强大推理能力的大语言模型提供宝贵洞见,从而惠及更广泛的研究社区。
🌟 亮点
-
预训练:为推理而生的基础模型
- 我们优化了数据预处理流程,提升文本提取工具包性能并应用多维数据过滤机制,从而增强预训练数据中的推理模式密度。同时采用多种策略生成海量多样化合成推理数据。
- 预训练采用三阶段数据混合策略,MiMo-7B-Base总计在约25万亿token上完成训练。
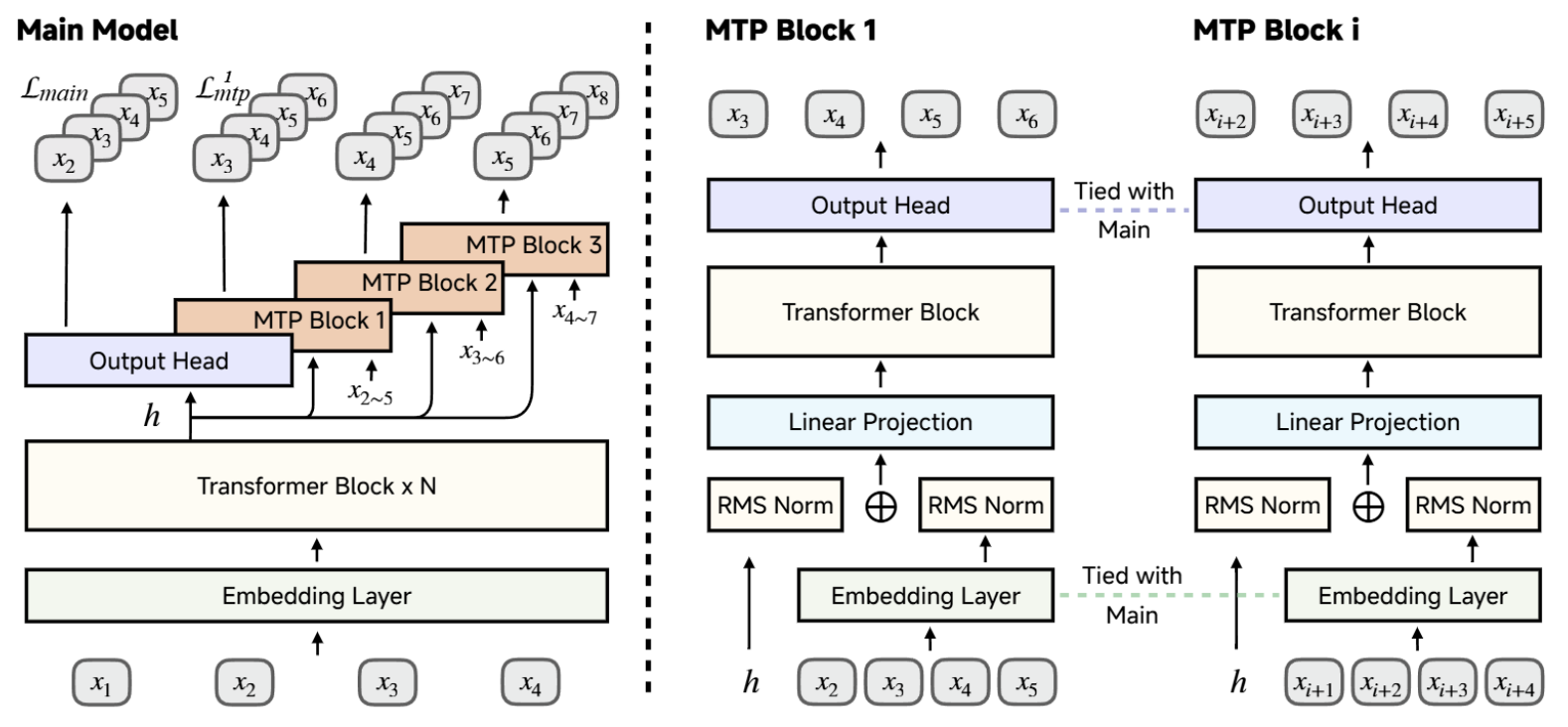
- 引入多token预测作为补充训练目标,既提升模型性能又加速推理过程。
-
后训练方案:开创性推理模型
- 精选13万道数学与编程题作为RL训练数据,所有题目均可通过规则验证器校验。每道题目经过严格清洗与难度评级以确保质量,仅采用基于规则的准确性奖励机制以避免潜在奖励作弊。
- 针对高难度编程题的稀疏奖励问题,首创测试难度驱动的代码奖励机制。通过对不同难度测试用例分配细粒度分数,实现密集奖励信号下的策略优化。
- 实施简单题目数据重采样策略,提升rollout采样效率并稳定策略更新,尤其在RL训练后期效果显著。
-
RL基础设施
- 开发无缝Rollout引擎加速RL训练与验证。通过持续rollout、异步奖励计算与提前终止的整合设计,将GPU空闲时间最小化,实现训练速度提升2.29倍,验证速度提升1.96倍。
- 在vLLM中支持MTP技术,并强化RL系统推理引擎的鲁棒性。
模型细节
MiMo-7B的MTP层在预训练和SFT阶段进行调优,RL阶段保持冻结。当使用单层MTP进行推测解码时,token接受率约为90%。
评估结果
Benchmark GPT-4o-0513 Claude-3.5-Sonnet-1022 OpenAI o1-mini QwQ-32B-Preview R1-Distill-Qwen-14B R1-Distill-Qwen-7B MiMo-7B-RL General GPQA Diamond
(Pass@1)49.9 65.0 60.0 54.5 59.1 49.1 54.4 SuperGPQA
(Pass@1)42.4 48.2 45.2 43.6 40.6 28.9 40.5 DROP
(3-shot F1)83.7 88.3 83.9 71.2 85.5 77.0 78.7 MMLU-Pro
(EM)72.6 78.0 80.3 52.0 68.8 53.5 58.6 IF-Eval
(Prompt Strict)84.3 86.5 84.8 40.4 78.3 60.5 61.0 Mathematics MATH-500
(Pass@1)74.6 78.3 90.0 90.6 93.9 92.8 95.8 AIME 2024
(Pass@1)9.3 16.0 63.6 50.0 69.7 55.5 68.2 AIME 2025
(Pass@1)11.6 7.4 50.7 32.4 48.2 38.8 55.4 Code LiveCodeBench v5
(Pass@1)32.9 38.9 53.8 41.9 53.1 37.6 57.8 LiveCodeBench v6
(Pass@1)30.9 37.2 46.8 39.1 31.9 23.9 49.3 MiMo-7B 系列
Benchmark MiMo-7B-Base MiMo-7B-RL-Zero MiMo-7B-SFT MiMo-7B-RL MiMo-7B-RL-0530 Mathematics MATH500
(Pass@1)37.4 93.6 93.0 95.8 97.2 AIME 2024
(Pass@1)32.9 56.4 58.7 68.2 80.1 AIME 2025
(Pass@1)24.3 46.3 44.3 55.4 70.2 Code LiveCodeBench v5
(Pass@1)32.9 49.1 52.3 57.8 60.9 LiveCodeBench v6
(Pass@1)29.1 42.9 45.5 49.3 52.2 [!重要]
评估采用 temperature=0.6 参数进行。
AIME24和AIME25采用32次重复的平均得分。LiveCodeBench v5(20240801-20250201)、LiveCodeBench v6(20250201-20250501)、GPQA-Diamond和IF-Eval采用8次重复的平均得分。MATH500和SuperGPQA为单次运行结果。
部署
SGLang推理
得益于SGLang团队的贡献,我们在24小时内实现了对SGLang主流的MiMo支持,MTP功能即将推出。
示例脚本
# Install the latest SGlang from main branch python3 -m uv pip install "sglang[all] @ git+https://github.com/sgl-project/sglang.git/@main#egg=sglang&subdirectory=python" # Launch SGLang Server python3 -m sglang.launch_server --model-path XiaomiMiMo/MiMo-7B-RL --host 0.0.0.0 --trust-remote-code
详细用法请参阅SGLang文档。MTP功能也将在24小时内获得支持。
vLLM推理
- [推荐] 我们官方支持使用我们分叉的vLLM版本进行MiMo-MTP推理。
示例脚本
from vllm import LLM, SamplingParams model_path = "/path/to/MiMo" llm = LLM( model=model_path, trust_remote_code=True, num_speculative_tokens=1, disable_log_stats=False ) sampling_params = SamplingParams(temperature=0.6) conversation = [ { "role": "system", "content": "" }, { "role": "user", "content": "Write an essay about the importance of higher education.", }, ] outputs = llm.chat(conversation, sampling_params=sampling_params, use_tqdm=False) for output in outputs: prompt = output.prompt generated_text = output.outputs[0].text print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}") print("=" * 80)- 或者,您可以在不加载MTP参数的情况下为MiMo注册vLLM加载器。
您可以将registry/register_mimo_in_vllm.py复制到您的目录并导入它。
import register_mimo_in_vllm from vllm import LLM, SamplingParams model_path = "/path/to/MiMo" llm = LLM( model=model_path, trust_remote_code=True, # num_speculative_tokens=1, disable_log_stats=False ) sampling_params = SamplingParams(temperature=0.6)HuggingFace 推理
示例脚本
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer model_id = "XiaomiMiMo/MiMo-7B-RL-0530" model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True) tokenizer = AutoTokenizer.from_pretrained(model_id) inputs = tokenizer(["Today is"], return_tensors='pt') output = model.generate(**inputs, max_new_tokens = 100) print(tokenizer.decode(output.tolist()[0]))
推荐环境与提示词设置
- 我们推荐使用基于vLLM 0.7.3开发的定制分支
- 建议使用空系统提示词
该模型尚未在其他推理引擎验证,欢迎基于Huggingface仓库中的模型定义进行二次开发 💻







