
transformer 输入三视图线段输出长宽高 笔记

写个代码,用transformer架构,框架pytorch,输入正交三视图的线段坐标3*4*2*2+对应视图编码,输出立方体的长宽高 以及基于投影矩阵的立方体数据(坐标最小值(0,0))生成器,
transformer-zhenjiao3dre | Kaggle
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 基于投影矩阵的立方体数据生成器
class CubeDataGenerator:
def __init__(self, min_size=1.0, max_size=10.0, batch_size=32):
self.min_size = min_size
self.max_size = max_size
self.batch_size = batch_size
def generate(self):
# 随机生成立方体尺寸
lengths = torch.rand(self.batch_size, 3) * (self.max_size - self.min_size) + self.min_size
# 根据立方体尺寸生成三个视图的线段坐标 3视图 * 4线段 * 2点 * 2坐标
line_segments = torch.zeros(self.batch_size, 3, 4, 2, 2)
for b in range(self.batch_size):
l, w, h = lengths[b]
# 正视图(从前向后看)
line_segments[b, 0, 0] = torch.tensor([[0.0, 0.0], [l, 0.0]]) # 底边
line_segments[b, 0, 1] = torch.tensor([[l, 0.0], [l, h]]) # 右边
line_segments[b, 0, 2] = torch.tensor([[l, h], [0.0, h]]) # 顶边
line_segments[b, 0, 3] = torch.tensor([[0.0, h], [0.0, 0.0]]) # 左边
# 侧视图(从左向右看)
line_segments[b, 1, 0] = torch.tensor([[0.0, 0.0], [w, 0.0]]) # 底边
line_segments[b, 1, 1] = torch.tensor([[w, 0.0], [w, h]]) # 右边
line_segments[b, 1, 2] = torch.tensor([[w, h], [0.0, h]]) # 顶边
line_segments[b, 1, 3] = torch.tensor([[0.0, h], [0.0, 0.0]]) # 左边
# 顶视图(从上向下看)
line_segments[b, 2, 0] = torch.tensor([[0.0, 0.0], [l, 0.0]]) # 底边
line_segments[b, 2, 1] = torch.tensor([[l, 0.0], [l, w]]) # 右边
line_segments[b, 2, 2] = torch.tensor([[l, w], [0.0, w]]) # 顶边
line_segments[b, 2, 3] = torch.tensor([[0.0, w], [0.0, 0.0]]) # 左边
# 生成视图编码,3个视图对应3个不同的编码
view_codes = torch.eye(3).unsqueeze(0).repeat(self.batch_size, 1, 1) # 形状为 batch_size * 3视图 * 3
return line_segments, lengths, view_codes
# Transformer 架构模型
class TransformerCubePredictor(nn.Module):
def __init__(self, d_model=64, num_heads=8, num_layers=2, input_dim=2):
super(TransformerCubePredictor, self).__init__()
self.d_model = d_model
# 线段坐标嵌入,每个线段有2个点,每个点有input_dim个坐标
self.line_segment_embed = nn.Linear(input_dim * 2, d_model)
# 视图编码嵌入
self.view_embed = nn.Linear(3, d_model)
# Transformer 编码器层
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=num_heads,
batch_first=True # 设置 batch_first=True 以避免警告信息
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
# 前馈网络
self.fc = nn.Sequential(
nn.Linear(d_model, d_model * 2),
nn.ReLU(),
nn.Linear(d_model * 2, d_model),
nn.ReLU(),
nn.Linear(d_model, 3) # 输出立方体的长宽高
)
def forward(self, line_segments, view_codes):
# 线段坐标形状: batch_size * 3视图 * 4线段 * 2点 * input_dim
batch_size, num_views, num_lines, _, input_dim = line_segments.shape
# 展平线段坐标(保留批次维度)
line_segments_flattened = line_segments.view(batch_size, num_views * num_lines, -1) # batch_size * (3视图*4线段) * (2点*input_dim)
# 嵌入线段坐标
line_embeddings = self.line_segment_embed(line_segments_flattened) # batch_size * (3*4) * d_model
# 嵌入视图编码,扩展到每个线段
view_codes_repeated = view_codes.unsqueeze(2).repeat(1, 1, num_lines, 1)
view_codes_flattened = view_codes_repeated.view(batch_size, num_views * num_lines, -1)
view_embeddings = self.view_embed(view_codes_flattened) # batch_size * (3*4) * d_model
# 合并嵌入
embeddings = line_embeddings + view_embeddings # batch_size * (3*4) * d_model
# Transformer 编码
encoded = self.transformer_encoder(embeddings) # batch_size * (3*4) * d_model
# 对所有位置进行平均池化以得到固定尺寸的表示
pooled = torch.mean(encoded, dim=1) # batch_size * d_model
# 预测立方体尺寸
predicted_sizes = self.fc(pooled)
return predicted_sizes
# 训练脚本
def train():
# 数据生成器
generator = CubeDataGenerator(min_size=1.0, max_size=10.0, batch_size=32)
# 创建模型
model = TransformerCubePredictor(input_dim=2)
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练参数
num_epochs = 100
# 训练循环
for epoch in range(num_epochs):
# 生成训练数据
line_segments, true_sizes, view_codes = generator.generate()
# 前向传播
model.train() # 设置模型为训练模式
optimizer.zero_grad() # 清空梯度
predicted_sizes = model(line_segments, view_codes)
# 计算损失
loss = criterion(predicted_sizes, true_sizes)
# 反向传播和优化
loss.backward()
optimizer.step()
# 打印训练信息
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
print("Training completed.")
# 训练脚本
def train():
# 数据生成器
generator = CubeDataGenerator(min_size=1.0, max_size=10.0, batch_size=32)
# 创建模型
model = TransformerCubePredictor(input_dim=2)
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练参数
num_epochs = 100
# 训练循环
for epoch in range(num_epochs):
# 生成训练数据
line_segments, true_sizes, view_codes = generator.generate()
# 前向传播
model.train() # 设置模型为训练模式
optimizer.zero_grad() # 清空梯度
predicted_sizes = model(line_segments, view_codes)
# 计算损失
loss = criterion(predicted_sizes, true_sizes)
# 反向传播和优化
loss.backward()
optimizer.step()
# 打印训练信息
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
print("Training completed.")
# 执行训练
if __name__ == "__main__":
train()
# 测试代码
if __name__ == "__main__":
# 创建数据生成器
generator = CubeDataGenerator(min_size=1.0, max_size=10.0, batch_size=2)
# 生成数据
line_segments, true_sizes, view_codes = generator.generate()
# 创建模型
model = TransformerCubePredictor(input_dim=2)
# 前向传播
predicted_sizes = model(line_segments, view_codes)
# 打印结果
print("True Sizes:\n", true_sizes)
print("Predicted Sizes:\n", predicted_sizes)
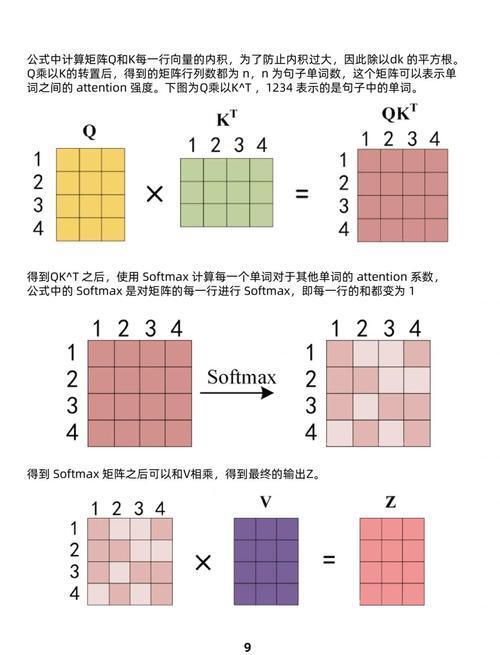
(图片来源网络,侵删)
(图片来源网络,侵删)
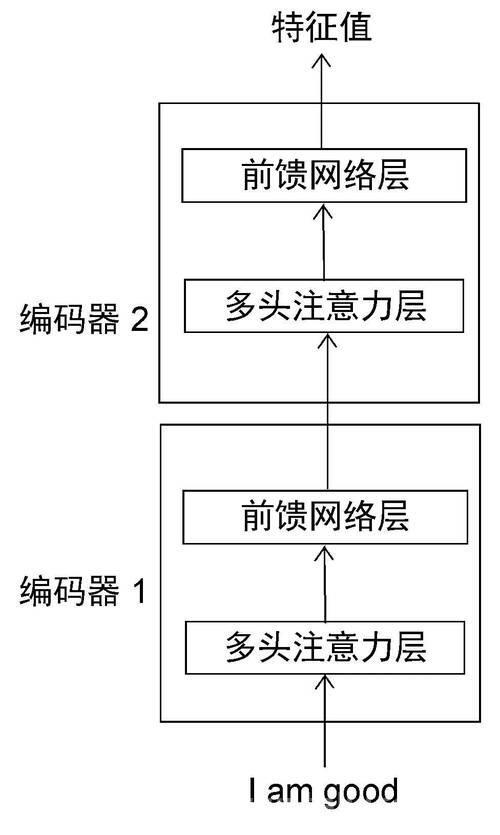
(图片来源网络,侵删)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







