
SQL Server核心知识总结

SQL Server核心知识总结
🎯 本文总结了SQL Server核心知识点,每个主题都提供实际可运行的示例代码。
一、SQL Server基础精要
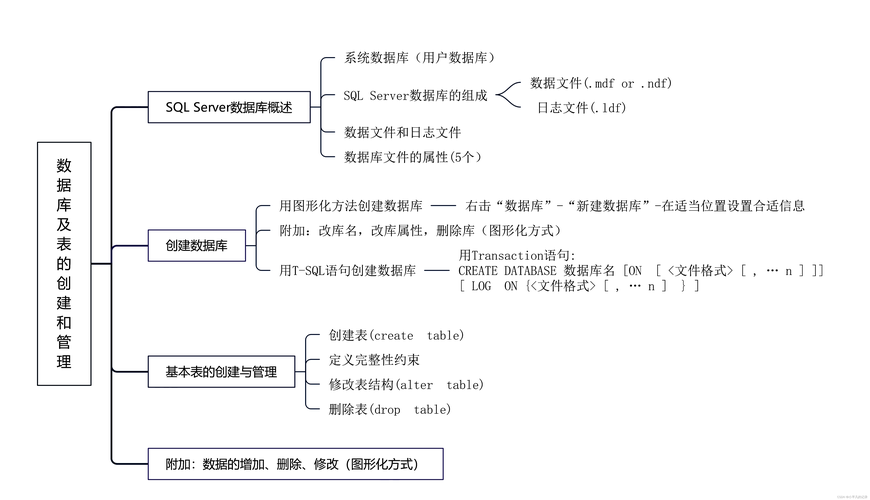
1. 数据库核心操作
-- 1. 创建数据库(核心配置)
CREATE DATABASE 学生管理系统
ON PRIMARY
(
NAME = '学生管理系统_数据',
FILENAME = 'D:\Data\学生管理系统.mdf',
SIZE = 100MB,
FILEGROWTH = 100MB
)
LOG ON
(
NAME = '学生管理系统_日志',
FILENAME = 'D:\Data\学生管理系统.ldf',
SIZE = 50MB,
FILEGROWTH = 50MB
);
GO
-- 2. 创建核心表结构
CREATE TABLE 学生表
(
学号 CHAR(10) PRIMARY KEY, -- 主键(最重要)
姓名 NVARCHAR(20) NOT NULL, -- 必填字段
性别 CHAR(2),
出生日期 DATE,
班级 NVARCHAR(20)
);
CREATE TABLE 成绩表
(
ID INT IDENTITY(1,1) PRIMARY KEY, -- 自增主键
学号 CHAR(10),
课程号 CHAR(5),
成绩 DECIMAL(5,2),
CONSTRAINT FK_成绩表_学生表
FOREIGN KEY (学号) REFERENCES 学生表(学号) -- 外键关系
);
-- 3. 基本数据操作(最常用)
-- 插入数据
INSERT INTO 学生表 (学号, 姓名, 性别, 班级)
VALUES ('2021001', '张三', '男', '计算机1班');
-- 更新数据
UPDATE 学生表
SET 班级 = '计算机2班'
WHERE 学号 = '2021001';
-- 删除数据
DELETE FROM 学生表
WHERE 学号 = '2021001';
🔑 核心要点:
-
数据库设计三要素:
- 主数据文件(.mdf):存储数据
- 日志文件(.ldf):记录事务
- 合理的初始大小和增长设置
-
表设计核心原则:
- 必须有主键(唯一标识)
- 建立合适的外键关系
- 选择合适的数据类型
- 添加必要的约束
-
最常用的SQL操作:
- INSERT:添加数据
- UPDATE:修改数据
- DELETE:删除数据
2. 数据类型和查询
让我们学习最常用的数据类型和SELECT查询:
-- 1. 最常用数据类型示例
CREATE TABLE 数据类型示例
(
-- 整数类型(最常用)
ID INT IDENTITY(1,1), -- 自增整数,常用主键
数量 SMALLINT, -- 较小范围整数
-- 精确数值(金融计算必用)
金额 DECIMAL(12,2), -- 总12位,小数2位
单价 MONEY, -- 专用于金融计算
-- 字符串(最常用)
名称 NVARCHAR(50), -- Unicode变长,最常用
编号 CHAR(10), -- 定长,如学号工号等
描述 VARCHAR(MAX), -- 大文本数据
-- 日期时间(最常用)
创建日期 DATE, -- 仅日期
更新时间 DATETIME2 -- 日期时间,推荐使用
);
-- 2. 核心查询语句
-- 基础查询(最常用)
SELECT 学号, 姓名, 成绩
FROM 学生表
WHERE 班级 = '计算机1班'
ORDER BY 成绩 DESC;
-- 多表联接(重要)
SELECT s.姓名, c.课程名, g.成绩
FROM 学生表 s
INNER JOIN 成绩表 g ON s.学号 = g.学号
INNER JOIN 课程表 c ON g.课程号 = c.课程号
WHERE g.成绩 >= 60;
-- 分组统计(常用)
SELECT 班级,
COUNT(*) AS 人数,
AVG(成绩) AS 平均分,
MAX(成绩) AS 最高分
FROM 学生表 s
JOIN 成绩表 g ON s.学号 = g.学号
GROUP BY 班级
HAVING AVG(成绩) >= 60;
-- 子查询(重要)
SELECT 姓名, 成绩
FROM 学生表 s
JOIN 成绩表 g ON s.学号 = g.学号
WHERE 成绩 > (
SELECT AVG(成绩)
FROM 成绩表
);
📝 查询要点:
-
SELECT语句核心组成(按执行顺序):
- FROM:指定数据来源
- WHERE:行级过滤
- GROUP BY:分组
- HAVING:组级过滤
- ORDER BY:排序
-
常用联接类型:
- INNER JOIN:内联接(最常用)
- LEFT JOIN:左外联接(保留左表所有行)
- RIGHT JOIN:右外联接(保留右表所有行)
-
常用聚合函数:
- COUNT():计数
- SUM():求和
- AVG():平均值
- MAX()/MIN():最大/最小值
-
性能优化要点:
- 只查询需要的列
- 合理使用索引
- 避免SELECT *
- 适当使用WHERE条件
3. 索引和性能优化
让我们学习最核心的性能优化技术:
-- 1. 创建最常用的索引类型
-- 聚集索引(主键,每表仅一个)
CREATE TABLE 订单表
(
订单号 INT PRIMARY KEY, -- 自动创建聚集索引
客户ID INT,
订单日期 DATE,
总金额 DECIMAL(12,2)
);
-- 非聚集索引(最常用的查询优化方式)
CREATE NONCLUSTERED INDEX IX_订单表_客户ID
ON 订单表(客户ID);
-- 覆盖索引(包含所有需要的列)
CREATE NONCLUSTERED INDEX IX_订单表_日期_金额
ON 订单表(订单日期)
INCLUDE (总金额);
-- 2. 查看索引使用情况
-- 查看索引的使用统计
SELECT
OBJECT_NAME(i.object_id) AS 表名,
i.name AS 索引名,
ius.user_seeks + ius.user_scans AS 使用次数,
ius.last_user_seek AS 最后查询时间
FROM sys.dm_db_index_usage_stats ius
JOIN sys.indexes i ON ius.object_id = i.object_id
AND ius.index_id = i.index_id
WHERE database_id = DB_ID();
-- 3. 性能诊断(最常用)
-- 查看执行计划
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
GO
-- 慢查询示例
SELECT * FROM 订单表
WHERE 订单日期 BETWEEN '2024-01-01' AND '2024-01-31';
-- 优化后的查询
SELECT 订单号, 订单日期, 总金额
FROM 订单表 WITH(INDEX(IX_订单表_日期_金额))
WHERE 订单日期 BETWEEN '2024-01-01' AND '2024-01-31';
🚀 性能优化核心要点:
-
索引使用原则:
- 经常查询的列建立索引
- 外键列必建索引
- 避免对频繁更新的列建索引
- 选择性高的列适合建索引
-
最重要的优化技巧:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 使用覆盖索引避免回表
- 避免索引列上使用函数
- 避免隐式类型转换
- 合理使用索引提示
-
常见性能问题:
- 索引碎片化:定期重建或重组
- 统计信息过期:更新统计信息
- 参数嗅探:使用OPTIMIZE FOR
- 死锁:合理的事务处理
-
性能监控工具:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 执行计划
- STATISTICS IO/TIME
- sys.dm_db_index_usage_stats
- 数据库引擎优化顾问
4. 事务和并发控制
让我们学习如何保证数据的一致性:
-- 1. 基本事务处理(最常用)
-- 转账示例
BEGIN TRY
BEGIN TRANSACTION;
-- 从账户A扣款
UPDATE 账户表
SET 余额 = 余额 - 1000
WHERE 账户ID = 'A';
-- 给账户B存款
UPDATE 账户表
SET 余额 = 余额 + 1000
WHERE 账户ID = 'B';
-- 记录交易日志
INSERT INTO 交易日志(交易类型, 金额, 时间)
VALUES ('转账', 1000, GETDATE());
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION;
INSERT INTO 错误日志(错误信息, 时间)
VALUES (ERROR_MESSAGE(), GETDATE());
END CATCH;
-- 2. 事务隔离级别(重要)
-- 设置隔离级别
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 处理并发访问
BEGIN TRANSACTION;
-- 使用锁提示
SELECT * FROM 订单表 WITH (UPDLOCK, ROWLOCK)
WHERE 订单号 = '001';
-- 更新订单
UPDATE 订单表
SET 状态 = '已处理'
WHERE 订单号 = '001';
COMMIT TRANSACTION;
-- 3. 死锁处理(常见问题)
-- 设置死锁优先级
SET DEADLOCK_PRIORITY HIGH;
-- 使用表锁提示避免死锁
UPDATE 订单表 WITH (ROWLOCK)
SET 状态 = '处理中'
WHERE 订单号 = '001';
-- 4. 并发控制最佳实践
-- 使用乐观并发控制
CREATE TABLE 商品表
(
商品ID INT PRIMARY KEY,
名称 NVARCHAR(50),
库存 INT,
版本号 ROWVERSION -- 用于乐观并发控制
);
-- 乐观并发更新示例
UPDATE 商品表
SET 库存 = 库存 - 1
WHERE 商品ID = 1
AND 版本号 = @原版本号; -- 确保数据未被其他事务修改
🔒 事务管理核心要点:
-
事务ACID特性:
- 原子性:要么全做要么全不做
- 一致性:保持数据完整
- 隔离性:事务间互不干扰
- 持久性:提交后永久保存
-
最常用的隔离级别:
- READ COMMITTED(默认):防止脏读
- REPEATABLE READ:防止不可重复读
- SERIALIZABLE:最高隔离级别
- READ UNCOMMITTED:性能最好但不安全
-
并发控制策略:
- 悲观锁:适用于高并发更新
- 乐观锁:适用于读多写少
- 行级锁:粒度小,并发高
- 表级锁:粒度大,阻塞多
-
实践建议:
- 事务尽可能短小
- 合理设置隔离级别
- 避免长时间持有锁
- 正确的错误处理
5. 备份和恢复
让我们学习如何保护数据安全:
-- 1. 完整备份(最基础最重要)
-- 创建完整备份
BACKUP DATABASE 学生管理系统
TO DISK = 'D:\Backup\学生管理系统_Full.bak'
WITH
COMPRESSION, -- 启用压缩
CHECKSUM, -- 验证备份完整性
DESCRIPTION = '完整备份'; -- 备份描述
-- 2. 差异备份(节省空间和时间)
BACKUP DATABASE 学生管理系统
TO DISK = 'D:\Backup\学生管理系统_Diff.bak'
WITH
DIFFERENTIAL, -- 差异备份
COMPRESSION;
-- 3. 日志备份(保证时间点恢复)
BACKUP LOG 学生管理系统
TO DISK = 'D:\Backup\学生管理系统_Log.bak'
WITH COMPRESSION;
-- 4. 数据库恢复(最常用场景)
-- 完整恢复
RESTORE DATABASE 学生管理系统
FROM DISK = 'D:\Backup\学生管理系统_Full.bak'
WITH NORECOVERY; -- 允许继续还原其他备份
-- 还原差异备份
RESTORE DATABASE 学生管理系统
FROM DISK = 'D:\Backup\学生管理系统_Diff.bak'
WITH NORECOVERY;
-- 还原日志备份到指定时间点
RESTORE LOG 学生管理系统
FROM DISK = 'D:\Backup\学生管理系统_Log.bak'
WITH
STOPAT = '2024-01-15 14:30:00', -- 指定恢复时间点
RECOVERY; -- 完成恢复,数据库可用
-- 5. 自动化备份维护(生产环境必备)
-- 清理过期备份文件
DECLARE @cmd NVARCHAR(500);
SET @cmd = 'forfiles /p "D:\Backup" /s /m *.bak /d -30 /c "cmd /c del @path"';
EXEC xp_cmdshell @cmd;
-- 验证备份有效性
RESTORE VERIFYONLY
FROM DISK = 'D:\Backup\学生管理系统_Full.bak';
💾 备份恢复核心要点:
-
三种主要备份类型:
- 完整备份:整个数据库的完整副本
- 差异备份:自上次完整备份后的变化
- 日志备份:记录详细的事务日志
-
常用备份策略(最佳实践):
- 每周一次完整备份
- 每天一次差异备份
- 每小时一次日志备份
- 定期验证备份有效性
-
关键恢复场景:
- 系统崩溃:使用最新的一致备份
- 数据误删:使用时间点恢复
- 硬件故障:完整恢复流程
- 测试环境:快速还原生产数据
-
备份管理要点:
- 异地存储重要备份
- 定期清理过期备份
- 监控备份执行状态
- 测试恢复流程
6. 安全管理
让我们学习如何保护数据库安全:
-- 1. 用户和角色管理(基础安全)
-- 创建登录名
CREATE LOGIN 教师登录
WITH PASSWORD = 'P@ssw0rd123',
CHECK_POLICY = ON; -- 启用密码策略
-- 创建数据库用户
USE 学生管理系统;
CREATE USER 教师用户 FOR LOGIN 教师登录;
-- 创建角色并分配权限
CREATE ROLE 教师角色;
GRANT SELECT, UPDATE ON 成绩表 TO 教师角色;
GRANT SELECT ON 学生表 TO 教师角色;
-- 将用户添加到角色
ALTER ROLE 教师角色 ADD MEMBER 教师用户;
-- 2. 数据加密(敏感数据保护)
-- 创建主密钥
CREATE MASTER KEY ENCRYPTION
BY PASSWORD = 'YourStr0ngP@ssw0rd';
-- 创建证书
CREATE CERTIFICATE 学生信息证书
WITH SUBJECT = '学生敏感信息加密证书';
-- 创建加密密钥
CREATE SYMMETRIC KEY 学生信息加密密钥
WITH ALGORITHM = AES_256
ENCRYPTION BY CERTIFICATE 学生信息证书;
-- 加密数据示例
CREATE TABLE 学生敏感信息
(
学号 CHAR(10) PRIMARY KEY,
姓名 NVARCHAR(20),
身份证号 VARBINARY(256), -- 加密存储
联系电话 VARBINARY(256) -- 加密存储
);
-- 插入加密数据
OPEN SYMMETRIC KEY 学生信息加密密钥
DECRYPTION BY CERTIFICATE 学生信息证书;
INSERT INTO 学生敏感信息
VALUES ('2021001', '张三',
EncryptByKey(Key_GUID('学生信息加密密钥'), '320123199901011234'),
EncryptByKey(Key_GUID('学生信息加密密钥'), '13912345678')
);
CLOSE SYMMETRIC KEY 学生信息加密密钥;
-- 3. 审计跟踪(最重要的安全措施)
-- 创建服务器审计
CREATE SERVER AUDIT 数据库审计
TO FILE (FILEPATH = 'D:\Audit\');
-- 创建数据库审计规范
CREATE DATABASE AUDIT SPECIFICATION 学生数据审计
FOR SERVER AUDIT 数据库审计
ADD (SELECT, UPDATE, DELETE ON 学生表 BY PUBLIC),
ADD (SELECT, UPDATE ON 成绩表 BY PUBLIC);
-- 启用审计
ALTER SERVER AUDIT 数据库审计 WITH (STATE = ON);
ALTER DATABASE AUDIT SPECIFICATION 学生数据审计 WITH (STATE = ON);
-- 查看审计日志
SELECT * FROM fn_get_audit_file
('D:\Audit\*', DEFAULT, DEFAULT);
-- 4. 安全最佳实践
-- 定期修改密码
ALTER LOGIN 教师登录
WITH PASSWORD = 'NewP@ssw0rd456';
-- 禁用不用的账户
ALTER LOGIN 教师登录 DISABLE;
-- 回收不需要的权限
REVOKE UPDATE ON 成绩表 FROM 教师角色;
-- 监控登录失败
SELECT * FROM sys.dm_exec_sessions
WHERE login_time > DATEADD(HOUR, -1, GETDATE())
AND login_name = '教师登录';
🔐 安全管理核心要点:
-
访问控制基础:
- 最小权限原则
- 基于角色的授权
- 定期审查权限
- 密码策略管理
-
数据加密策略:
- 敏感数据加密存储
- 传输数据加密
- 密钥定期轮换
- 证书安全管理
-
审计要点:
- 重要操作必须审计
- 定期检查审计日志
- 异常行为告警
- 审计日志安全存储
-
安全维护:
- 定期安全评估
- 及时安装补丁
- 监控可疑活动
- 制定应急预案
二、高级特性
让我们学习SQL Server最常用的高级功能:
1. 存储过程和函数
-- 1. 存储过程(最常用的封装方式)
-- 创建成绩统计存储过程
CREATE PROCEDURE sp_统计学生成绩
@班级 NVARCHAR(20),
@及格率 DECIMAL(5,2) OUTPUT
AS
BEGIN
SET NOCOUNT ON;
-- 计算及格率
SELECT @及格率 =
CONVERT(DECIMAL(5,2),
SUM(CASE WHEN 成绩 >= 60 THEN 1 ELSE 0 END) * 100.0 /
COUNT(*))
FROM 成绩表 g
JOIN 学生表 s ON g.学号 = s.学号
WHERE s.班级 = @班级;
-- 返回详细统计
SELECT
COUNT(*) AS 总人数,
AVG(成绩) AS 平均分,
MAX(成绩) AS 最高分,
MIN(成绩) AS 最低分
FROM 成绩表 g
JOIN 学生表 s ON g.学号 = s.学号
WHERE s.班级 = @班级;
END;
-- 调用存储过程
DECLARE @及格率 DECIMAL(5,2);
EXEC sp_统计学生成绩
@班级 = '计算机1班',
@及格率 = @及格率 OUTPUT;
PRINT '及格率: ' + CAST(@及格率 AS VARCHAR(10)) + '%';
-- 2. 自定义函数(常用计算封装)
-- 创建年龄计算函数
CREATE FUNCTION fn_计算年龄
(
@出生日期 DATE
)
RETURNS INT
AS
BEGIN
RETURN DATEDIFF(YEAR, @出生日期, GETDATE()) -
CASE
WHEN DATEADD(YEAR, DATEDIFF(YEAR, @出生日期, GETDATE()), @出生日期) > GETDATE()
THEN 1
ELSE 0
END;
END;
-- 创建成绩等级函数
CREATE FUNCTION fn_计算等级
(
@成绩 DECIMAL(5,2)
)
RETURNS CHAR(1)
AS
BEGIN
RETURN
CASE
WHEN @成绩 >= 90 THEN 'A'
WHEN @成绩 >= 80 THEN 'B'
WHEN @成绩 >= 70 THEN 'C'
WHEN @成绩 >= 60 THEN 'D'
ELSE 'F'
END;
END;
-- 使用函数
SELECT
姓名,
dbo.fn_计算年龄(出生日期) AS 年龄,
成绩,
dbo.fn_计算等级(成绩) AS 等级
FROM 学生表 s
JOIN 成绩表 g ON s.学号 = g.学号;
📦 存储过程和函数要点:
-
存储过程优势:
- 减少网络流量
- 重用业务逻辑
- 提高执行效率
- 增强安全性
-
函数使用场景:
- 复杂计算封装
- 数据转换处理
- 业务规则统一
- 代码重用
2. 触发器
-- 1. 数据审计触发器(最常用)
CREATE TRIGGER tr_学生表_审计
ON 学生表
AFTER INSERT, UPDATE, DELETE
AS
BEGIN
SET NOCOUNT ON;
-- 插入操作审计
INSERT INTO 审计日志(表名, 操作类型, 操作时间, 操作用户, 数据)
SELECT
'学生表',
'INSERT',
GETDATE(),
SYSTEM_USER,
(SELECT * FROM inserted FOR JSON AUTO)
FROM inserted
WHERE EXISTS (SELECT 1 FROM inserted);
-- 删除操作审计
INSERT INTO 审计日志(表名, 操作类型, 操作时间, 操作用户, 数据)
SELECT
'学生表',
'DELETE',
GETDATE(),
SYSTEM_USER,
(SELECT * FROM deleted FOR JSON AUTO)
FROM deleted
WHERE EXISTS (SELECT 1 FROM deleted);
END;
-- 2. 业务规则触发器(数据验证)
CREATE TRIGGER tr_成绩表_验证
ON 成绩表
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- 验证成绩范围
IF EXISTS (
SELECT 1 FROM inserted
WHERE 成绩 100
)
BEGIN
RAISERROR ('成绩必须在0-100之间', 16, 1);
RETURN;
END;
-- 验证通过后插入数据
INSERT INTO 成绩表(学号, 课程号, 成绩)
SELECT 学号, 课程号, 成绩
FROM inserted;
END;
🔄 触发器使用要点:
-
常用场景:
- 数据审计跟踪
- 业务规则验证
- 数据同步更新
- 自动计算汇总
-
设计原则:
- 触发器要简单
- 避免长事务
- 注意性能影响
- 合理使用事务
3. 视图
让我们继续学习视图的应用:
-- 1. 基础视图(最常用)
-- 创建学生成绩汇总视图
CREATE VIEW v_学生成绩汇总
AS
SELECT
s.学号,
s.姓名,
s.班级,
COUNT(g.课程号) AS 课程数,
AVG(g.成绩) AS 平均分,
SUM(CASE WHEN g.成绩 >= 60 THEN 1 ELSE 0 END) AS 及格课程数
FROM 学生表 s
LEFT JOIN 成绩表 g ON s.学号 = g.学号
GROUP BY s.学号, s.姓名, s.班级;
-- 2. 带检查选项的视图(数据验证)
CREATE VIEW v_优秀学生
WITH SCHEMABINDING
AS
SELECT 学号, 姓名, 班级, 成绩
FROM dbo.成绩表 g
JOIN dbo.学生表 s ON g.学号 = s.学号
WHERE 成绩 >= 90
WITH CHECK OPTION;
-- 3. 索引视图(提高查询性能)
CREATE VIEW v_课程平均分
WITH SCHEMABINDING
AS
SELECT
课程号,
COUNT_BIG(*) AS 学生数,
AVG(CONVERT(DECIMAL(5,2), 成绩)) AS 平均分
FROM dbo.成绩表
GROUP BY 课程号;
-- 在视图上创建唯一聚集索引
CREATE UNIQUE CLUSTERED INDEX IX_课程平均分
ON v_课程平均分(课程号);
-- 4. 分区视图(大表分区)
-- 创建分区表
CREATE TABLE 历史成绩表_2023
(
学号 CHAR(10),
课程号 CHAR(5),
成绩 DECIMAL(5,2),
学年 CHAR(4) CHECK (学年 = '2023')
);
CREATE TABLE 历史成绩表_2024
(
学号 CHAR(10),
课程号 CHAR(5),
成绩 DECIMAL(5,2),
学年 CHAR(4) CHECK (学年 = '2024')
);
-- 创建分区视图
CREATE VIEW v_历史成绩
AS
SELECT * FROM 历史成绩表_2023
UNION ALL
SELECT * FROM 历史成绩表_2024;
-- 5. 视图的使用示例
-- 查询优秀学生
SELECT * FROM v_优秀学生
WHERE 班级 = '计算机1班'
ORDER BY 成绩 DESC;
-- 更新视图数据
UPDATE v_学生成绩汇总
SET 班级 = '计算机2班'
WHERE 学号 = '2021001';
-- 通过视图插入数据
INSERT INTO v_优秀学生(学号, 姓名, 班级, 成绩)
VALUES ('2021010', '李四', '计算机1班', 95);
👁️ 视图使用要点:
-
视图的优势:
- 简化复杂查询
- 控制数据访问
- 提供数据独立性
- 实现数据安全
-
常用视图类型:
- 基础视图:简化查询
- 索引视图:提升性能
- 分区视图:管理大数据
- 更新视图:维护数据
-
设计原则:
- 避免过于复杂的视图
- 合理使用索引视图
- 注意更新限制
- 控制视图嵌套层数
-
性能考虑:
- 适当使用SCHEMABINDING
- 避免使用SELECT *
- 合理使用索引
- 控制视图复杂度
4. XML和JSON
让我们学习如何处理结构化数据:
-- 1. XML数据处理(常用于数据交换)
-- 创建包含XML列的表
CREATE TABLE 学生档案
(
学号 CHAR(10) PRIMARY KEY,
基本信息 XML,
成绩记录 XML
);
-- 插入XML数据
INSERT INTO 学生档案(学号, 基本信息)
VALUES (
'2021001',
'
张三
男
13912345678
zhangsan@example.com
'
);
-- 查询XML数据
SELECT
学号,
基本信息.value('(/学生/姓名)[1]', 'NVARCHAR(20)') AS 姓名,
基本信息.value('(/学生/联系方式/电话)[1]', 'VARCHAR(20)') AS 联系电话
FROM 学生档案;
-- 使用XML索引提高查询性能
CREATE PRIMARY XML INDEX PX_学生档案_基本信息
ON 学生档案(基本信息);
-- 2. JSON数据处理(更现代的选择)
-- 将查询结果转为JSON
SELECT
学号,
姓名,
班级,
成绩
FROM 学生表 s
JOIN 成绩表 g ON s.学号 = g.学号
FOR JSON PATH;
-- 创建包含JSON的表
CREATE TABLE 学生信息扩展
(
学号 CHAR(10) PRIMARY KEY,
扩展信息 NVARCHAR(MAX)
CHECK (ISJSON(扩展信息) = 1) -- 确保是有效的JSON
);
-- 插入JSON数据
INSERT INTO 学生信息扩展
VALUES (
'2021001',
'{
"兴趣爱好": ["编程", "篮球", "音乐"],
"获奖记录": [
{"时间": "2023-06", "奖项": "编程大赛一等奖"},
{"时间": "2023-12", "奖项": "优秀学生"}
],
"实习经历": {
"公司": "科技公司",
"职位": "开发实习生",
"时间": "2023-07至2023-09"
}
}'
);
-- 查询JSON数据
SELECT
学号,
JSON_VALUE(扩展信息, '$.实习经历.公司') AS 实习公司,
JSON_QUERY(扩展信息, '$.兴趣爱好') AS 兴趣爱好
FROM 学生信息扩展;
-- 3. 结构化数据转换(常用场景)
-- 行转列(XML方式)
SELECT
学号,
姓名,
(
SELECT 课程号 AS '@课程', 成绩 AS '@分数'
FROM 成绩表
WHERE 学号 = s.学号
FOR XML PATH('课程'), ROOT('成绩记录')
) AS 成绩XML
FROM 学生表 s;
-- 行转列(JSON方式)
SELECT
学号,
姓名,
(
SELECT 课程号, 成绩
FROM 成绩表
WHERE 学号 = s.学号
FOR JSON PATH
) AS 成绩JSON
FROM 学生表 s;
-- 4. 数据导入导出
-- 导出XML数据
SELECT 学号, 姓名, 班级
FROM 学生表
FOR XML PATH('学生'), ROOT('学生列表');
-- 导出JSON数据
SELECT 学号, 姓名, 班级
FROM 学生表
FOR JSON PATH, ROOT('学生列表');
-- 解析JSON数组
SELECT
学号,
兴趣
FROM 学生信息扩展
CROSS APPLY OPENJSON(扩展信息, '$.兴趣爱好')
WITH (兴趣 NVARCHAR(50) '$');
📊 结构化数据处理要点:
-
XML使用场景:
- 数据交换接口
- 配置文件存储
- 复杂数据结构
- 遗留系统集成
-
JSON优势:
- 更轻量级的格式
- 更好的可读性
- 前后端数据传输
- 现代API集成
-
性能考虑:
- 适当使用XML索引
- JSON数据类型验证
- 避免过大的文档
- 合理的查询方式
-
最佳实践:
- 选择合适的格式
- 规范的数据结构
- 有效的错误处理
- 定期数据维护
5. 全文检索
让我们学习如何实现高效的文本搜索:
-- 1. 全文检索配置(基础设置)
-- 创建全文目录
CREATE FULLTEXT CATALOG 文章目录
WITH ACCENT_SENSITIVITY = OFF
AS DEFAULT;
-- 创建包含大文本的表
CREATE TABLE 文章表
(
文章ID INT PRIMARY KEY,
标题 NVARCHAR(200),
内容 NVARCHAR(MAX),
作者 NVARCHAR(50),
发布时间 DATETIME2
);
-- 创建全文索引
CREATE FULLTEXT INDEX ON 文章表
(
标题 LANGUAGE 2052, -- 简体中文
内容 LANGUAGE 2052
)
KEY INDEX PK__文章表__ID
ON 文章目录
WITH CHANGE_TRACKING AUTO;
-- 2. 基本全文搜索(最常用)
-- 简单匹配
SELECT 文章ID, 标题, 作者
FROM 文章表
WHERE CONTAINS(内容, '数据库');
-- 多个关键词(任意匹配)
SELECT 文章ID, 标题
FROM 文章表
WHERE CONTAINS(内容, 'SQL OR 数据库');
-- 精确短语匹配
SELECT 文章ID, 标题
FROM 文章表
WHERE CONTAINS(内容, '"SQL Server 优化"');
-- 3. 高级搜索功能
-- 近似匹配
SELECT 文章ID, 标题
FROM 文章表
WHERE CONTAINS(内容, 'NEAR((数据库, 优化), 10)');
-- 通配符搜索
SELECT 文章ID, 标题
FROM 文章表
WHERE CONTAINS(内容, '"SQL*"');
-- 加权搜索
SELECT 文章ID, 标题,
RANK
FROM 文章表
INNER JOIN CONTAINSTABLE(文章表, (标题, 内容),
'数据库 OR 优化',
LANGUAGE 2052
) AS KEY_TBL
ON 文章表.文章ID = KEY_TBL.[KEY]
ORDER BY RANK DESC;
-- 4. 全文搜索最佳实践
-- 创建复合全文索引
CREATE FULLTEXT INDEX ON 文章表
(
标题 LANGUAGE 2052 STATISTICAL_SEMANTICS,
内容 LANGUAGE 2052 STATISTICAL_SEMANTICS,
作者 LANGUAGE 2052
)
KEY INDEX PK__文章表__ID
ON 文章目录
WITH CHANGE_TRACKING AUTO;
-- 使用停用词
CREATE FULLTEXT STOPLIST 自定义停用词
FROM SYSTEM STOPLIST;
ALTER FULLTEXT STOPLIST 自定义停用词
ADD '的' LANGUAGE 2052;
-- 更新全文索引
ALTER FULLTEXT INDEX ON 文章表
SET STOPLIST 自定义停用词;
-- 5. 性能优化示例
-- 重建全文索引
ALTER FULLTEXT INDEX ON 文章表
START FULL POPULATION;
-- 增量更新
ALTER FULLTEXT INDEX ON 文章表
START INCREMENTAL POPULATION;
-- 查看索引状态
SELECT
OBJECT_NAME(object_id) AS 表名,
FULLTEXTCATALOGPROPERTY('文章目录', 'ItemCount') AS 索引文档数,
FULLTEXTCATALOGPROPERTY('文章目录', 'PopulateStatus') AS 填充状态
FROM sys.fulltext_indexes
WHERE object_id = OBJECT_ID('文章表');
🔍 全文检索核心要点:
-
基础配置:
- 创建全文目录
- 配置全文索引
- 设置语言选项
- 管理停用词
-
搜索功能:
- 简单关键词搜索
- 精确短语匹配
- 近似词搜索
- 加权排序结果
-
性能优化:
- 合理使用索引
- 定期重建索引
- 增量更新策略
- 监控索引状态
-
使用建议:
- 选择合适的列
- 控制索引大小
- 优化搜索语句
- 定期维护索引
以上就是全部内容了,如果各位大佬有任何疑问,欢迎在评论区留言,你的点赞收藏我创作的最大动力!🥰🥰🥰
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







