
MySQL 之 GROUP BY 讲解:常见用法与案例剖析

在MySQL数据库中,GROUP BY 是一个非常强大的语句,用于将具有相同值的多行数据组合成一组。在电商交易系统中,GROUP BY 通常用于统计订单数据、计算销售总额、汇总用户行为等。本文将深入探讨 GROUP BY 的常见用法、常见问题及其解决方案,并结合 GROUP_CONCAT() 函数实现列合并,最后讨论一些性能优化的策略。
一、GROUP BY 的常见用法
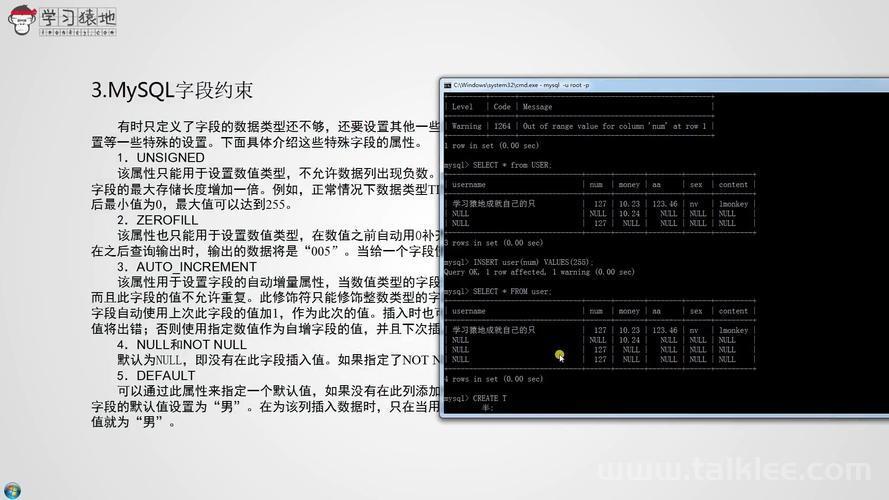
GROUP BY 语句通常与聚合函数如 COUNT()、SUM()、AVG() 等一起使用,以便对分组后的数据进行统计分析。下面以电商交易系统为例,展示 GROUP BY 的基本用法。
1. 统计每个用户的订单总数
假设我们有一个 orders 表,存储了每个订单的相关信息。我们希望统计每个用户的订单总数,可以使用如下 SQL 查询:
SELECT user_id, COUNT(*) AS order_count FROM orders GROUP BY user_id;
2. 计算每个产品的总销售额
同样的,我们可以使用 GROUP BY 来计算每个产品的总销售额:
SELECT product_id, SUM(amount) AS total_sales FROM orders GROUP BY product_id;
3. 通过 SQL 匹配指定字段的重复数据
有时我们需要查找表中具有重复数据的记录。这在数据清理和去重操作中非常有用。
3.1. 查找重复数据
要查找重复数据,我们通常使用 GROUP BY 和 HAVING 子句来找出出现次数超过一次的记录。
-
示例:
假设在电商系统中,我们要查找那些多次出现的用户邮箱地址。假设 users 表包含 user_email 列:
SELECT user_email, COUNT(*) AS email_count FROM users GROUP BY user_email HAVING COUNT(*) > 1;
这个查询将返回所有出现次数超过一次的用户邮箱地址及其出现次数。
3.2. 查找并删除重复记录
一旦找到重复记录,通常还需要删除重复的记录。可以使用子查询来实现这一操作。
-
示例:
假设我们要删除 orders 表中重复的订单记录,仅保留每个 order_id 的最新记录。首先找出重复记录的ID:
SELECT order_id, COUNT(*) AS order_count FROM orders GROUP BY order_id HAVING COUNT(*) > 1;
然后使用子查询删除重复记录,仅保留每个 order_id 的最新记录:
 (图片来源网络,侵删)
(图片来源网络,侵删)DELETE FROM orders WHERE id NOT IN ( SELECT id FROM ( SELECT MIN(id) AS id FROM orders GROUP BY order_id ) AS keep_ids );这个查询将保留每个 order_id 的最小 id 记录,并删除其他重复记录。
4. GROUP_CONCAT() 实现合并列
在某些情况下,我们可能需要将同一组中的某个字段合并到一起,例如在统计用户下的所有产品时,我们希望将产品名以逗号分隔显示。这时可以使用 GROUP_CONCAT() 函数。
 (图片来源网络,侵删)
(图片来源网络,侵删)4.1 示例:统计每个用户购买的产品
SELECT user_id, GROUP_CONCAT(product_name ORDER BY product_name ASC SEPARATOR ', ') AS products FROM orders GROUP BY user_id;
该查询会返回每个用户以及他们购买的所有产品,产品名称之间以逗号分隔。
4.2 GROUP_CONCAT() 的长度限制
GROUP_CONCAT() 的默认返回结果长度是1024字节。如果结果超出了这个长度,MySQL会截断结果。可以通过设置 group_concat_max_len 变量来增加返回长度。
SET SESSION group_concat_max_len = 2048;
5. HAVING用法
HAVING 子句用于过滤 GROUP BY 产生的分组数据。它类似于 WHERE 子句,但 WHERE 子句不能用于过滤聚合函数的结果。
- 语法:
SELECT column1, aggregate_function(column2) FROM table_name GROUP BY column1 HAVING aggregate_function(column2) condition;
- 示例:
如果我们只想找出那些总订单金额超过1000元的用户:
SELECT user_id, SUM(order_amount) AS total_amount FROM orders GROUP BY user_id HAVING SUM(order_amount) > 1000;
这个查询将返回总订单金额大于1000元的用户及其金额。
二、常见问题及解决方案
虽然 GROUP BY 十分强大,但在实际使用过程中,可能会遇到一些常见问题。以下列出几种常见问题及其解决方案。
1. GROUP BY 与 ORDER BY 的冲突
在使用 GROUP BY 时,通常希望对结果进行排序。然而,直接使用 ORDER BY 有时会引发冲突,特别是在某些复杂查询中。解决方案是在 GROUP BY 之后单独使用 ORDER BY 进行排序。
SELECT user_id, COUNT(*) AS order_count FROM orders GROUP BY user_id ORDER BY order_count DESC;
2. 非法的 GROUP BY 列
MySQL 支持在 GROUP BY 语句中使用非聚合列,但这种用法并不总是符合 SQL 标准,并且可能导致意外的结果或警告。按照 SQL 标准,SELECT 子句中列出的非聚合列必须出现在 GROUP BY 子句中,否则查询结果将是不确定的。
然而,在 MySQL 中,即使非聚合列没有出现在 GROUP BY 子句中,查询通常也会执行并且返回结果。这是因为 MySQL 允许这种用法,并且默认情况下会选择每组的第一条记录的值作为代表。这种行为可能会导致数据不准确,特别是在需要明确的分组结果时。
示例
假设我们有一个名为 sales 的表,包含以下字段:product_id, sale_date, quantity 和 price。如果我们想要计算每个产品的总销售额,但是还想显示产品的名称(product_name),并且没有在 GROUP BY 子句中包括 product_name,查询可能如下所示:
SELECT product_id, product_name, SUM(quantity * price) AS total_sales FROM sales JOIN products ON sales.product_id = products.id GROUP BY product_id;
在这个例子中,product_name 没有出现在 GROUP BY 子句中。虽然查询可以成功执行,但 MySQL 会选择每一组中的第一条记录的 product_name 值。如果同一 product_id 对应的 product_name 值不同,则结果将是不确定的。
最佳实践
为了遵循 SQL 标准并确保结果的准确性,你应该始终确保 SELECT 子句中列出的非聚合列也出现在 GROUP BY 子句中:
SELECT product_id, product_name, SUM(quantity * price) AS total_sales FROM sales JOIN products ON sales.product_id = products.id GROUP BY product_id, product_name;
通过这种方式,你可以确保每个分组的 product_name 值是相同的,并且查询结果是准确的。
总之,虽然 MySQL 支持在 GROUP BY 语句中使用未出现在 GROUP BY 子句中的非聚合列,但这并不是最佳实践,并且可能会导致不确定的结果。为了确保数据的准确性和一致性,最好遵守 SQL 标准。
3. GROUP BY 性能问题
在大数据量的表中使用 GROUP BY 时,可能会遇到性能问题。这时可以通过优化索引或使用临时表来提升性能。
ALTER TABLE orders ADD INDEX (user_id);
三. 性能优化建议
在使用 GROUP BY 时,性能优化是非常重要的。以下是一些实用的性能优化建议。
4.1 使用索引优化查询
在 GROUP BY 所涉及的列上创建索引,可以显著提升查询速度。
ALTER TABLE orders ADD INDEX (product_id);
4.2 避免在大表上直接使用 GROUP BY
对于大表,直接使用 GROUP BY 可能会导致查询速度非常慢。可以考虑先将数据存入临时表,或通过分区表来优化查询。
CREATE TEMPORARY TABLE temp_orders AS SELECT * FROM orders WHERE order_date > '2024-01-01'; SELECT user_id, SUM(amount) AS total_sales FROM temp_orders GROUP BY user_id;
结论
MySQL 中的 GROUP BY 是数据聚合分析的核心工具之一,在电商交易系统中尤为重要。通过合理使用 GROUP BY,并结合 GROUP_CONCAT() 实现列合并,可以完成复杂的数据分析需求。同时,通过优化查询和索引,可以有效提升 GROUP BY 的执行性能。希望本文的详细讲解能够帮助读者更好地理解和应用 GROUP BY,从而提高数据库查询的效率和效果。
- 示例:
- 语法:
-







