
Python爬虫实战:研究Tornado框架相关技术

1. 引言
1.1 研究背景与意义
网络爬虫作为一种自动获取互联网信息的程序,在信息检索、数据挖掘、舆情分析等领域有着广泛的应用。随着互联网数据量的爆炸式增长,对爬虫的性能和效率提出了更高的要求。传统的同步爬虫在处理大量 URL 时效率低下,而异步爬虫可以显著提高并发处理能力,减少等待时间。
1.2 国内外研究现状
国外在网络爬虫领域的研究起步较早,技术相对成熟,像 Google、Bing 等大型搜索引擎背后都有高效的爬虫系统作为支撑。国内也有许多学者和企业在这方面进行了深入研究,例如百度、搜狗等公司的爬虫系统在处理中文网页方面有着独特的优势。
1.3 研究内容与方法
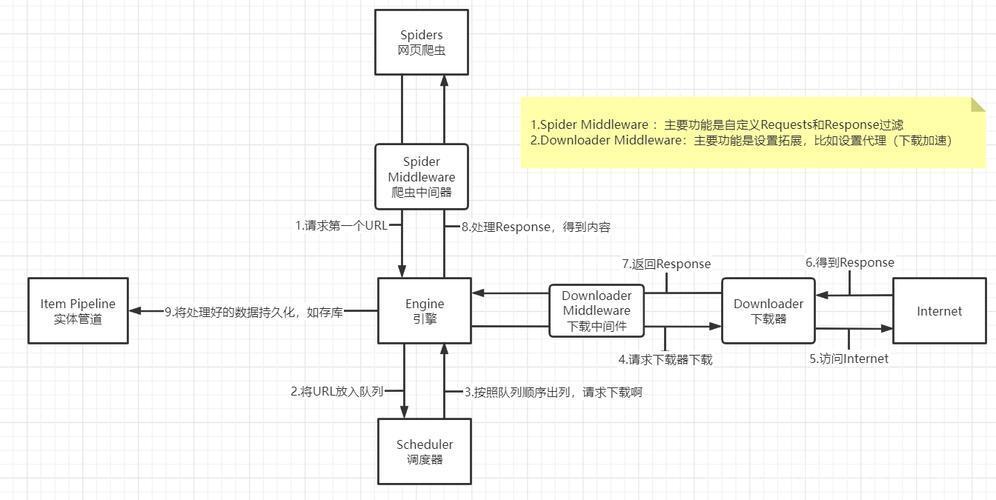
本文主要研究基于 Tornado 框架的 Python 爬虫系统的设计与实现。采用理论分析与实践相结合的方法,先对 Tornado 框架的特性和爬虫的基本原理进行分析,然后设计系统架构,最后通过代码实现并测试验证。

(图片来源网络,侵删)
(图片来源网络,侵删)

(图片来源网络,侵删)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







