
【Rust开发】Rust基础语法详细解析,助力你快速通关Rust


✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Rust开发,Python全栈,Golang开发,云原生开发,PyQt5和Tkinter桌面开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生K8S,linux,shell脚本等实操经验,网站搭建,数据库等分享。
所属的专栏:Rust语言通关之路
景天的主页:景天科技苑

文章目录
- Rust语法
- 1、变量
- 2、变量与常量的区别
- 3、隐藏(Shadowing)
- 4、Rust数据类型
- 4.1 标量类型
- 4.1.1 整形
- 4.1.2 浮点型
- 4.1.3 数字运算符
- 4.1.4 布尔型
- 4.1.5 字符类型
- 4.1.6 自适应类型
- 4.2 复合类型
- 4.2.1 数组
- 4.2.2 元祖
- 5、Rust函数
- 5.1 定义函数使用fn关键字
- 5.2 函数参数
- 5.3 函数体
- 5.4 语句与表达式
- 5.5 函数的返回值
- 6、注释
- 6.1 单行注释
- 6.2 文档注释
- 7、控制流
- 7.1 if表达式
- 7.2 循环语句
- 1)loop循环
- 2)while循环
- 3)for循环
- 8、总结
Rust语法
本文将介绍 Rust 中常用的一些概念,并通过真实的程序来展示如何运用它们。
你将会学到Rust的变量,数据类型,函数,注释方法,流程控制语句等很多的知识!
我们创建个工程,来展示Rust语法
cargo new rustvar

1、变量
在 Rust 中,使用let关键字来定义变量。
语法格式: let 变量名:类型 = 变量值
类型可以自动推导
变量默认是 不可变(immutable)的。这是鼓励你利用 Rust 安全和简单并发的优势来编写代码的一大助力。
不过,你仍然可以使用可变变量。让我们探讨一下 Rust 拥抱不可变性的原因及方法,以及何时你不想使用不可变性。
当变量不可变时,意味着一旦值被绑定上一个名称,你就不能改变这个值。
我们用个例子说明下
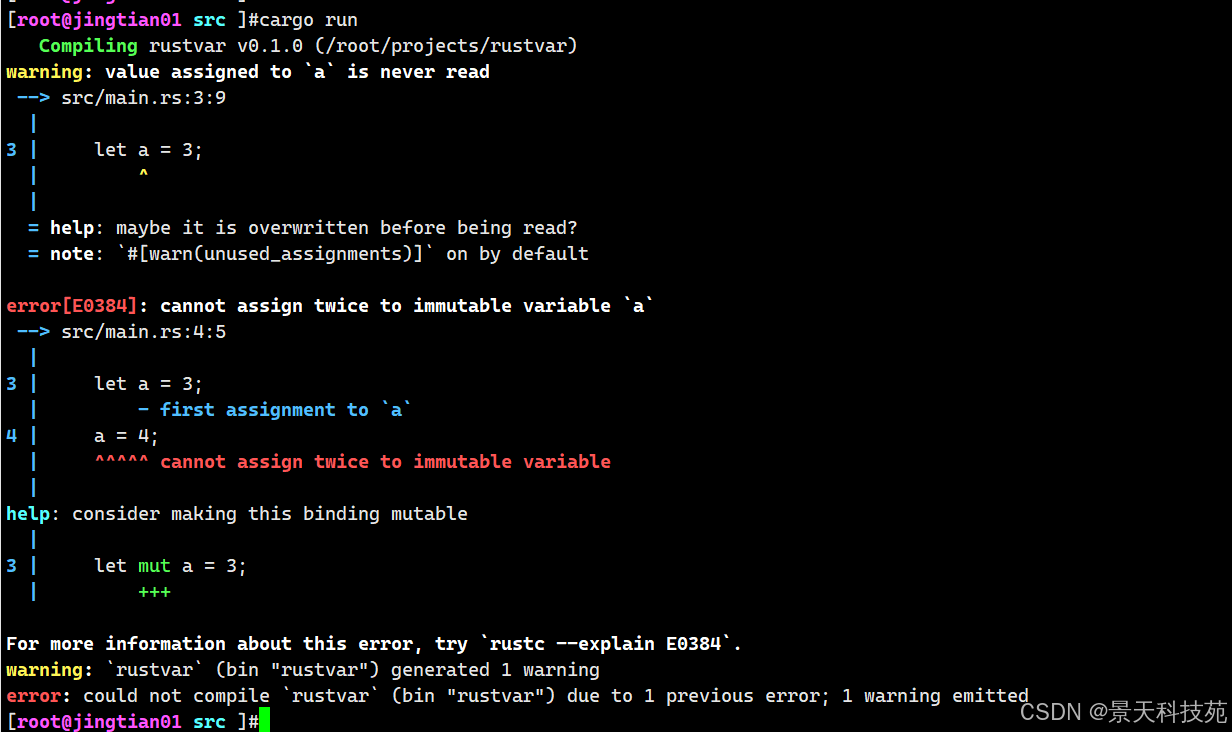
fn main() { //定义变量 let a = 3; //rust如果有多行代码,必须以分号结尾,不然编译报错 a = 4; println!("a = {}",a); println!("Hello, world!"); }我们运行下
[root@jingtian01 src ]#cargo run
这个例子展示了编译器如何帮助你找出程序中的错误。虽然编译错误令人沮丧,那也不过是说程序不能安全的完成你想
让它完成的工作;而 不能 说明你是不是一个好程序员!有经验的 Rustacean 们一样会遇到编译错误。
这些错误给出的原因是 不能对不可变变量二次赋值 ( cannot assign twice to immutable variable a ),因为我们尝试对不可变变量 a 赋第二个值。
在尝试改变预设为不可变的值的时候产生编译错误是很重要的,因为这种情况可能导致 bug:
如果代码的一部分假设一个值永远也不会改变,而另一部分代码改变了它,第一部分代码就有可能以不可预料的方式运行。
不得不承认这种 bug难以跟踪,尤其是第二部分代码只是 有时 改变其值的时候。
Rust 编译器保证,如果声明一个值不会变,它就真的不会变。这意味着当阅读和编写代码时,不需要追踪一个值如何以及哪里可能会被改变,从而使得代码易于推导。
不过可变性也是非常有用的。变量只是默认不可变,可以通过在变量名之前加 mut 来使其可变。
除了使值可以改变之外,它向读者表明了其他代码将会改变这个变量的意图。
可变变量
使用mut修饰的变量,是可变变量
fn main() { //定义变量 //let a = 3; //定义可变变量 let mut a = 3; println!("修改前的值a = {}",a); a = 4; println!("修改后的值a = {}",a); }再次运行,编译成功,并且a的值被成功修改

通过 mut ,允许把绑定到 a 的值从 3 改成 4 。在一些情况下,你会想用可变变量,因为这样的代码比起只用不可变变量的实现更容易编写。
除了避免 bug 外,还有很多地方需要权衡取舍。例如,使用大型数据结构时,适当地使用可变变量,可能比复制和返回新分配的实例更快。
对于较小的数据结构,总是创建新实例,采用更偏向函数式的风格编程,可能会使代码更易理解,为可读性而遭受性能惩罚或许值得。
变量占位符
Rust语言变量占位符是大括号{}
局部变量如果创建了,未使用编译会警告
2、变量与常量的区别
不允许改变值的变量,可能会使你想起另一个大部分编程语言都有的概念:常量(constants)。
类似于不可变变量,常量也是绑定到一个名称的不允许改变的值,不过常量与变量还是有一些区别。
首先,不允许对常量使用 mut :常量不光默认不能变,它总是不能变。
声明常量使用 const 关键字而不是 let ,并且 必须 注明值的类型。
常量可以在任何作用域声明,包括全局作用域,这在一个值需要被很多部分的代码用到时很有用。
最后一个区别是常量只能用于常量表达式,而不能作为函数调用的结果,或任何其他只在运行时计算的值。
这是一个常量声明的例子,它的名称是 MAX_POINTS ,值是 100,000。(Rust 的常量使用下划线分隔的大写字母的命名规范):
const MAX_OPTIONS:u32 = 1000;
在声明它的作用域之中,常量在整个程序生命周期中都有效,这使得常量可以作为多处代码使用的全局范围的值,例如一个游戏中所有玩家可以获取的最高分或者光速。
将用于整个程序的硬编码的值声明为常量对后来的维护者了解值的意义很有帮助。同时将硬编码的值汇总于一处,也能
为将来修改提供方便。
3、隐藏(Shadowing)
我们可以定义一个与之前变量重名的新变量,而新变量会 隐藏 之前的变量。
Rustacean 们称之为第一个变量被第二个 隐藏 了,这意味着使用这个变量时会看到第二个值。
可以用相同变量名称来隐藏它自己,
以及重复使用 let 关键字来多次隐藏,如下所示:
fn main() { let x = 5; let x = x + 1; let x = x * 2; println!("The value of x is: {}", x); }这个程序首先将 x 绑定到值 5 上。接着通过 let x = 隐藏 x ,获取原始值并加 1 这样 x 的值就变成 6 了。
第三个 let 语句也隐藏了 x ,获取之前的值并乘以 2 , x 最终的值是 12 。运行这个程序,它会有如下输出:

这与将变量声明为 mut 是有区别的。因为除非再次使用 let 关键字,不小心尝试对变量重新赋值会导致编译时错误。
我们可以用这个值进行一些计算,不过计算完之后变量仍然是不变的。
mut 与隐藏的另一个区别是,当再次使用 let 时,实际上创建了一个新变量,我们可以改变值的类型,从而复用这个名字。
例如,假设程序请求用户输入空格来提供文本间隔,然而我们真正需要的是将输入存储成数字(多少个空格):
let spaces = " ";
let spaces = spaces.len();
这里允许第一个 spaces 变量是字符串类型,而第二个 spaces 变量,它是一个恰巧与第一个变量同名的崭新变量,是数字类型。
隐藏使我们不必使用不同的名字,如 spaces_str 和 spaces_num ;相反,我们可以复用 spaces 这个更简单的名字。
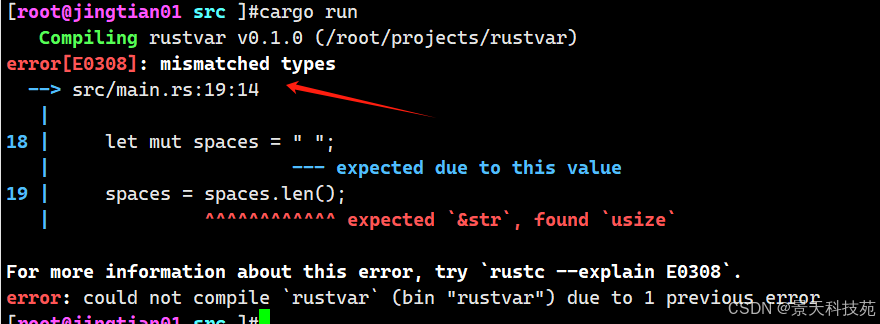
然而,如果尝试使用 mut ,如下所示:
let mut spaces = " "; spaces = spaces.len();
会导致一个编译错误,因为改变一个变量的类型是不被允许的:
4、Rust数据类型
在 Rust 中,任何值都属于一种明确的 类型(type),这告诉了 Rust 它被指定为何种数据,以便明确其处理方式。
本部分我们将看到一系列内建于语言中的类型。我们将其分为两类:标量(scalar)和复合(compound)。
Rust 是 静态类型(statically typed)语言,也就是说在编译时就必须知道所有变量的类型,这一点将贯穿整个章节。
通过值的形式及其使用方式,编译器通常可以推断出我们想要用的类型。
4.1 标量类型
标量(scalar)类型代表一个单独的值。Rust 有四种基本的标量类型:整型、浮点型、布尔类型、字符类型。
你可能在其他语言中见过它们,不过让我们深入了解它们在 Rust 中是如何工作的。
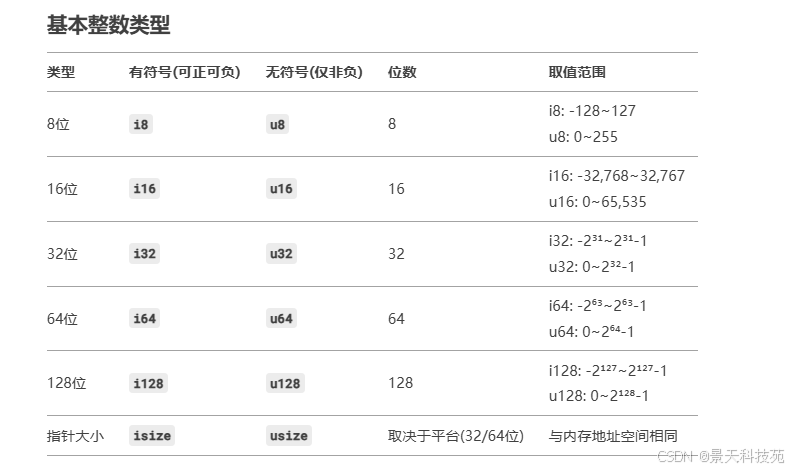
4.1.1 整形
整数 是一个没有小数部分的数字。我们在前面使用过 u32 类型。该类型声明表明,u32 关联的值应该是一个占据 32 比特位的无符号整数(有符号整型类型以 i 开头而不是 u )。
下方表格展示了 Rust 内建的整数类型。每一种变体都有符号和无符号列(例如,i8)可以用来声明对应的整数值。
Rust 默认的整数类型是 i32
Rust 中的整型

4.1.2 浮点型
Rust 同样有两个主要的 浮点数(floating-point numbers)类型, f32 和 f64 ,它们是带小数点的数字,分别占 32 位和64 位比特。
默认类型是 f64 ,因为在现代 CPU 中它与 f32 速度几乎一样,不过精度更高。
这是一个展示浮点数的实例:
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }浮点数采用 IEEE-754 标准表示。 f32 是单精度浮点数, f64 是双精度浮点数。
4.1.3 数字运算符
Rust 支持所有数字类型常见的基本数学运算操作:加法(+)、减法(-)、乘法(*)、除法(/)以及取余(%)。
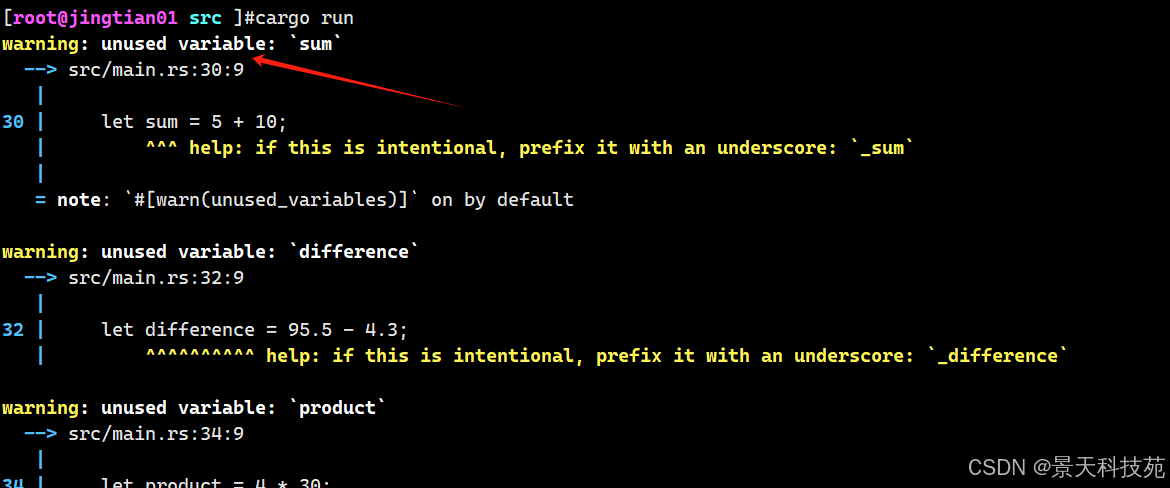
下面的代码展示了如何在一个let 语句中使用它们:
//数字运算符 // addition let sum = 5 + 10; println!("sum={}",sum); // subtraction let difference = 95.5 - 4.3; println!("difference={}",difference); // multiplication let product = 4 * 30; println!("product={}",product); // division 除 let quotient = 56.7 / 32.2; println!("quotient={}",quotient); // remainder 取余 let remainder = 43 % 5; println!("remainder={}",remainder);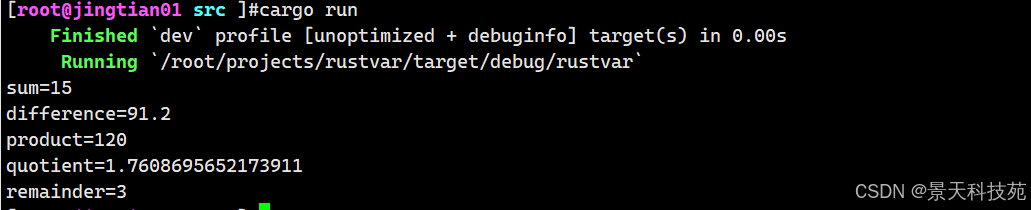
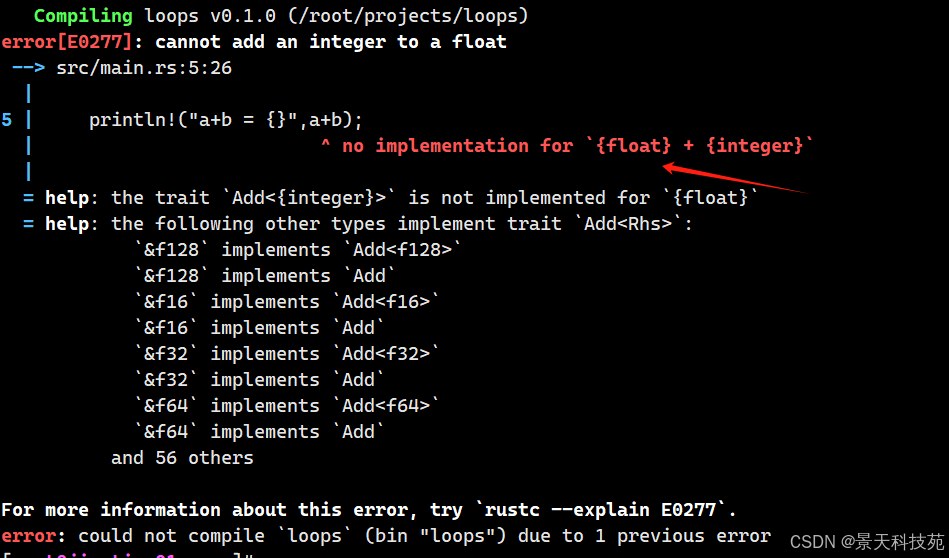
注意,Rust中,不能进行自动类型转换。不同类型的数据不能进行运算,比如i32不能与float64类型的进行加减乘除运算,否则编译报错
fn main() { //数值计算 let a = 3.9; let b = 5; println!("a+b = {}",a+b); }编译报错
4.1.4 布尔型
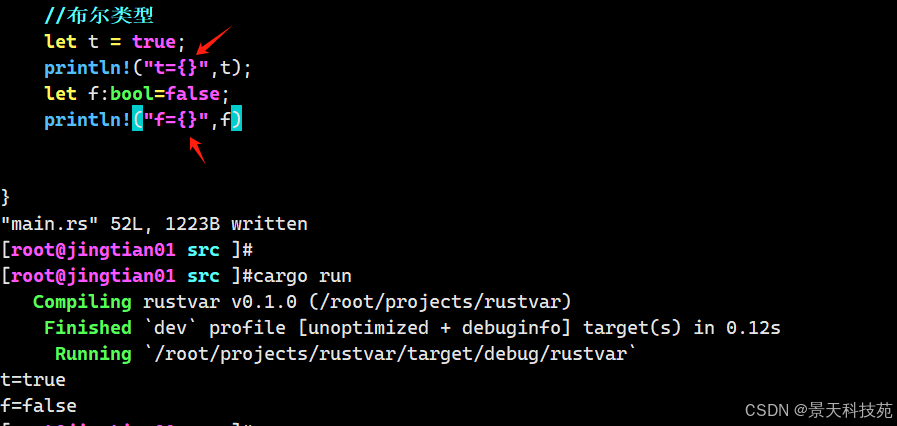
正如其他大部分编程语言一样,Rust 中的布尔类型有两个可能的值: true 和 false 。Rust 中的布尔类型使用 bool 表示。例如:
//布尔类型 let t = true; println!("t={}",t); let f:bool=false; println!("f={}",f)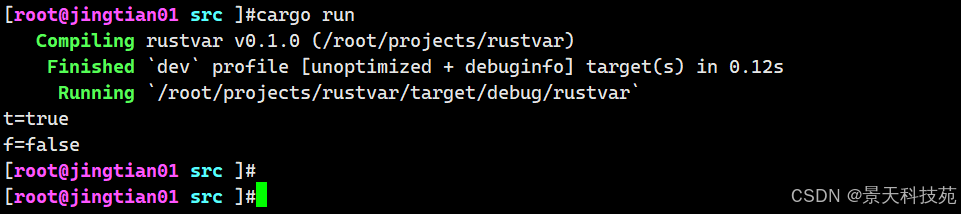
4.1.5 字符类型
目前为止只使用到了数字,不过 Rust 也支持字符 使用char关键字表示。
Rust中,字符型char是32位的。
Rust 的 char 类型是大部分语言中基本字母字符类型,如下代码展示了如何使用它。
注意 char 由单引号指定,不同于字符串使用双引号:
//字符型 let c = 'z'; println!("c={}",c); let z = '1'; println!("z={}",z);
Rust 的 char 类型代表了一个 Unicode 标量值(Unicode Scalar Value),这意味着它可以比 ASCII 表示更多内容。
拼音字母(Accented letters),中文/日文/韩文等象形文字,emoji(絵文字)以及零长度的空白字符对于 Rust char 类型都是有效的。
Unicode 标量值包含从 U+0000 到 U+D7FF 和 U+E000 到 U+10FFFF 在内的值。
不过,“字符” 并不是一个 Unicode 中的概念,所以人直觉上的 “字符” 可能与 Rust 中的 char 并不符合。后面我们讲的 “字符串” 部分将详细讨论这个主题。
4.1.6 自适应类型
自适应类型,主要和程序运行的平台相关,根据不同的平台得到不同的结果
常见的自适应类型的变量有isize和usize
isize 和 usize 类型依赖运行程序的计算机架构:64 位架构上它们是 64 位的, 32 位架构上它们是 32 位的。
isize 或 usize 主要作为某些集合的索引
Rust 的默认类型通常就很好,数字类型默认是 i32
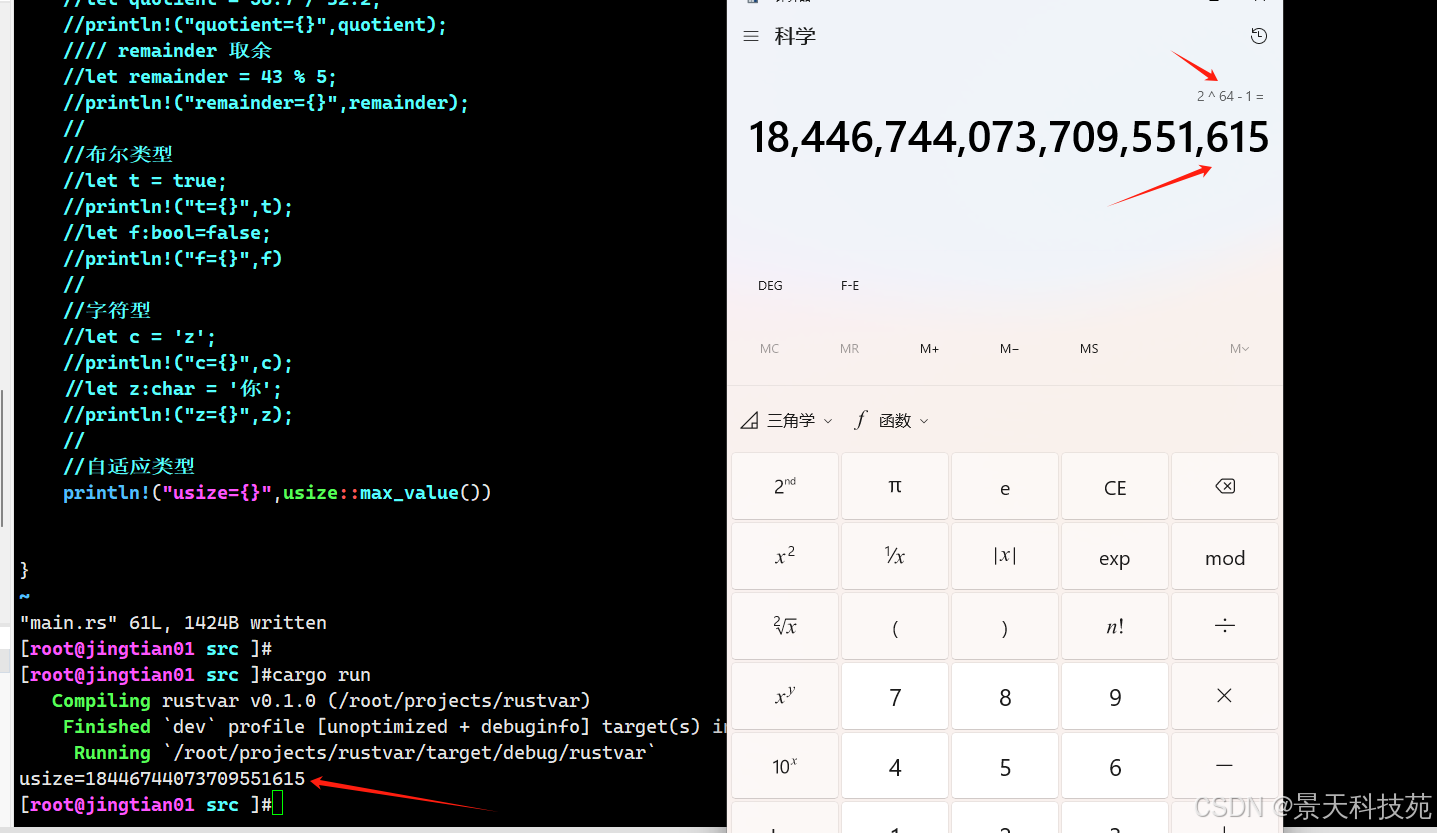
查看下最大值
//自适应类型 println!("usize={}",usize::max_value())可以看到我们得系统是64位的
4.2 复合类型
复合类型(Compound types)可以将多个其他类型的值组合成一个类型。Rust 有两个原生的复合类型:数组(array),元组(tuple),枚举(enum)和结构体(struct)。
4.2.1 数组
数组(array)。数组中的每个元素的类型必须相同。
Rust 中的数组与一些其他语言中的数组不同,因为 Rust 中的数组是固定长度的:一旦声明,它们的长度不能增长或缩小。
Rust 中数组的值位于中括号中的逗号分隔的列表中
数组的定义方式是:[Type; size]
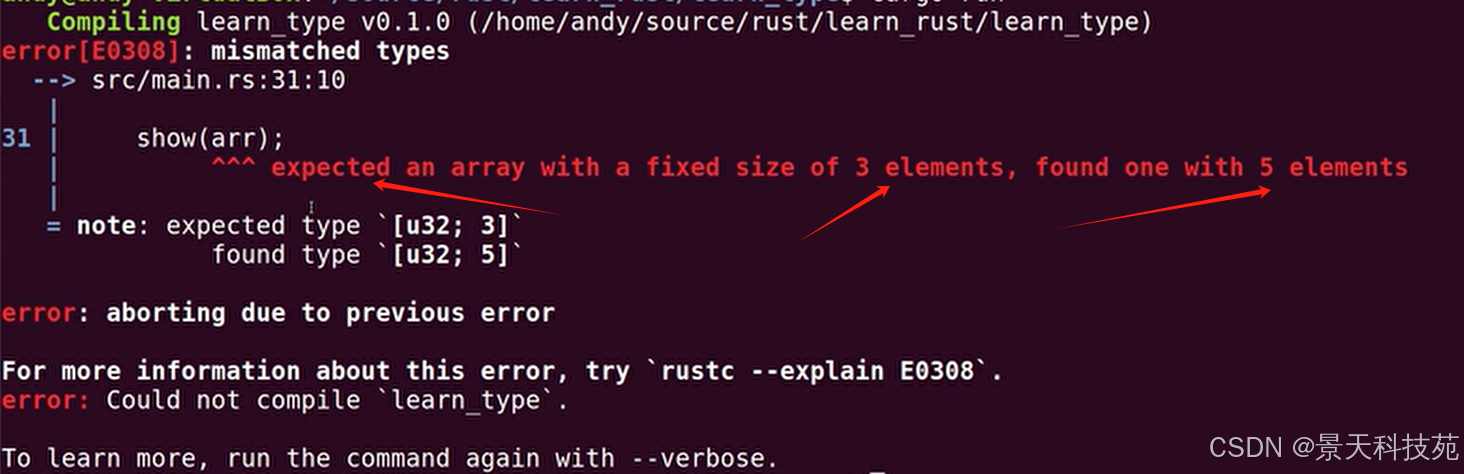
//数组 let arr: [u32;5]= [1,2,3,4,5]; println!("arr[0]={}",arr[0]);
注意,数组中的size也是数组类型的一部分,函数传参时,这个size要与函数定义时数组的size大小保持一致,不然传参会失败
4.2.2 元祖
元组是一个将多个其他类型的值组合进一个复合类型的主要方式。
我们使用一个括号中的逗号分隔的值列表来创建一个元组。元组中的每一个位置都有一个类型,而且这些不同值的类型也不必是相同的。
定义元祖方式:既可以自动推导,也可以定义好类型
let tup = (500, 6.4, 1); let tup:(i32, f64, u32, char) = (-3, 9.8, 77, '好')
tup 变量绑定了整个元组,因为元组被认为是一个单独的复合元素。为了从元组中获取单个的值,可以使用模式匹配(pattern matching)来解构(destructure)元组,像这样:
//元祖 let tup:(i32, f64, u32, char) = (-3, 9.8, 77, '好'); //打印元祖,需要解构 let (x,y,z,a) = tup; println!("x={},y={}, z={}, a={}",x,y,z,a);
程序首先创建了一个元组并绑定到 tup 变量上。接着使用了 let 和一个模式将 tup 分成了三个不同的变量, x 、 y 、 z和a 。
这叫做 解构(destructuring),因为它将一个元组拆成了四个部分。最后,程序打印出了 x 、 y 、 z和a的值。
除了使用模式匹配解构之外,也可以使用点号( . )后跟值的索引来直接访问它们。例如:
//下标获取元祖元素 let x = tup.0; let y = tup.1; println!("x={},y={}",x,y);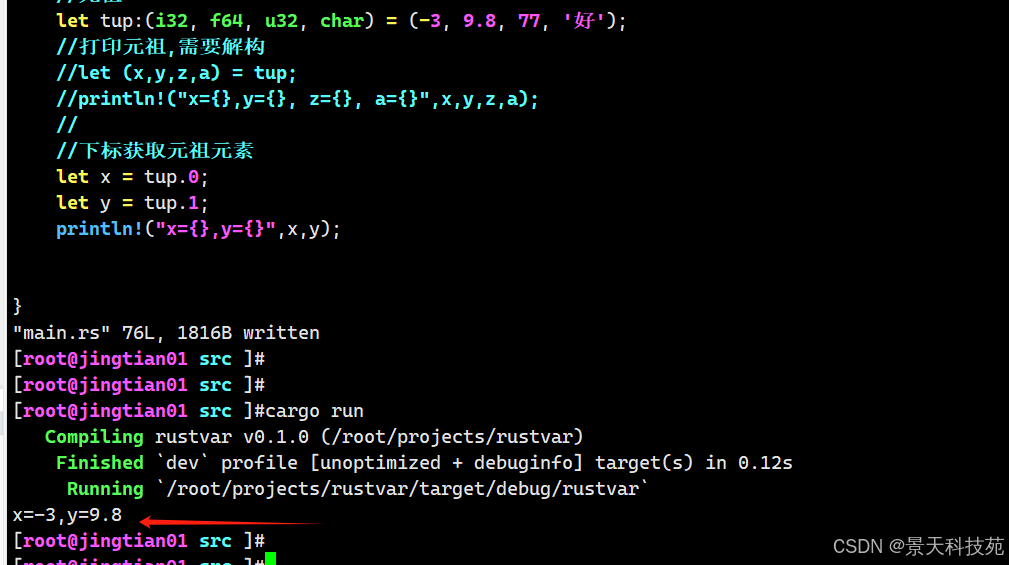
这个程序创建了一个元组 tup ,并接着使用索引为每个元素创建新变量。跟大多数编程语言一样,元组的第一个索引值是 0。
5、Rust函数
函数在 Rust 代码中应用广泛。你已经见过一个语言中最重要的函数: main 函数,它是很多程序的入口点。你也见过了fn 关键字,它用来声明新函数。
Rust 代码使用 snake case 蛇形命名法 作为函数和变量名称的规范风格。在 snake case 中,所有字母都是小写并使用下划线分隔单词。
这里是一个包含函数定义的程序的例子:
5.1 定义函数使用fn关键字
我们在main函数外面定义一个函数吗,然后在main函数里面调用
fn main() { println!("Hello, world!"); //调用外部函数 another(); } //定义函数 fn another(){ //Rust语言四个空格缩进 println!("Another function is working!") }运行程序
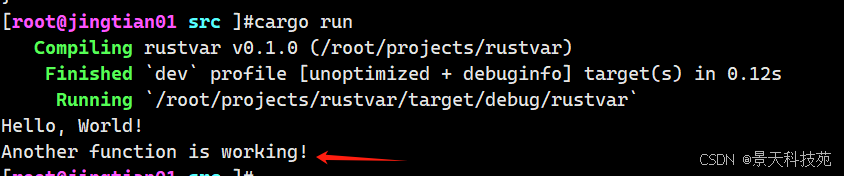
代码在 main 函数中按照它们出现的顺序被执行。首先,打印 “Hello, world!” 信息,接着 another被调用并打印它的信息。
Rust 中的函数定义以 fn 开始并在函数名后跟一对括号。大括号告诉编译器哪里是函数体的开始和结尾。
可以使用定义过的函数名后跟括号来调用任意函数。因为 another 已经在程序中定义过了,它可以在 main 函
数中被调用。注意,源码中 another在 main 函数 之后 被定义;也可以在其之前定义。
Rust 不关心函数定义于何处,只要它们被定义了。
5.2 函数参数
函数也可以被定义为拥有 参数(parameters),它们是作为函数签名一部分的特殊变量。当函数拥有参数时,可以为这些参数提供具体的值。
技术上讲,这些具体值被称为参数(arguments),不过通常的习惯是倾向于在函数定义中的变量和调用函数时传递的具体值都可以用 “parameter” 和 “argument” 而不加区别。
定义函数的时候,参数必须指定类型,不能自动推导。例如: fn fun1(a:TypeName, b:TypeName){}
但是调用函数传参的时候,可以自动推导
fn main() { another(2, 4); } //有参函数,可以指定形参的类型 fn another(x: i32, y: i32){ //Rust语言四个空格缩进 println!("x={}",x); println!("y={}",y); }运行
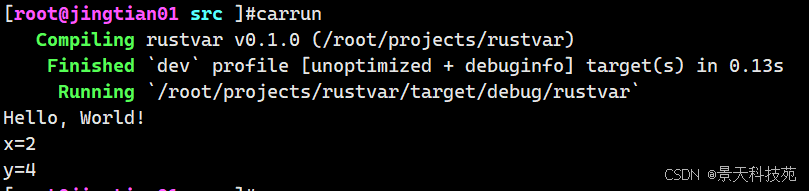
这个例子创建了一个有两个参数的函数,都是 i32 类型的。函数打印出了这两个参数的值。
注意函数参数并不一定都是相同类型的,这个例子中它们只是碰巧相同罢了。
5.3 函数体
函数体由一系列的语句和一个可选的表达式构成。目前为止,我们只涉及到了没有结尾表达式的函数,不过我们见过表达式作为了语句的一部分。
因为 Rust 是一个基于表达式(expression-based)的语言,这是一个需要理解的(不同于其他语言)重要区别。
其他语言并没有这样的区别,所以让我们看看语句与表达式有什么区别以及它们是如何影响函数体的。
5.4 语句与表达式
我们已经用过语句与表达式了。语句(Statements)是执行一些操作但不返回值的指令。表达式(Expressions)计算并产生一个值。
让我们看一些例子:
使用 let 关键字创建变量并绑定一个值是一个语句。如下 let y = 6; 是一个语句:
fn main() { let y = 6; }上述代码包含一个语句的 main 函数定义
函数定义也是语句,上面整个例子本身就是一个语句。
语句并不返回值。因此,不能把 let 语句赋值给另一个变量,比如下面的例子尝试做的,这会产生一个错误:
fn main() { let x = (let y = 6); }当运行这个程序,会得到如下错误:
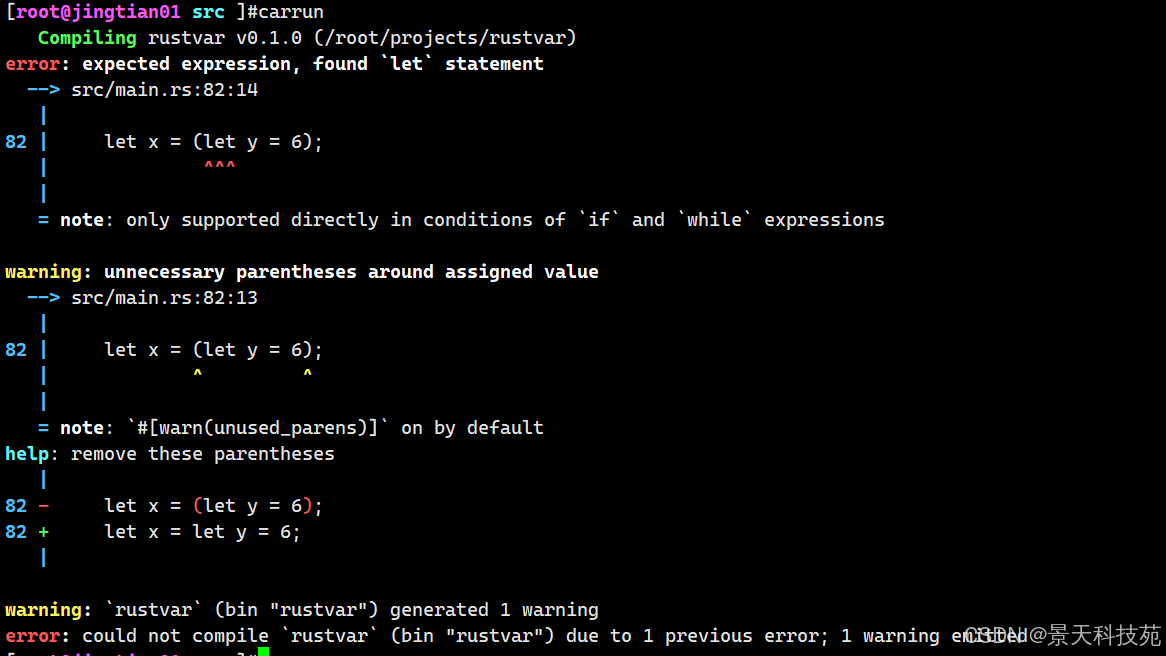
let y = 6 语句并不返回值,所以并没有 x 可以绑定的值。这与其他语言不同,例如 C 和 Ruby,它们的赋值语句返回所赋的值。
在这些语言中,可以这么写 x = y = 6 这样 x 和 y 的值都是 6 ;这在 Rust 中可不行。
表达式计算出一些值,而且它们组成了其余大部分你将会编写的 Rust 代码。
考虑一个简单的数学运算,比如 5 + 6 ,这是一个表达式并计算出值 11 。表达式可以是语句的一部分:语句 let y = 6; , 6 是一个表达式,
它计算出的值是 6 。函数调用是一个表达式。宏调用是一个表达式。
我们用来创建新作用域的大括号(代码块), {} ,也是一个表达式
例如:
fn main() { let x = 5; let y = { let x = 3; x + 1 }; println!("The value of y is: {}", y); }这个表达式:
{ let x = 3; x + 1 }是一个代码块,它的值是 4 。这个值作为 let 语句的一部分被绑定到 y 上。注意结尾没有分号的那一行,与大部分我们见过的代码行不同。
表达式并不包含结尾的分号。如果在表达式的结尾加上分号,他就变成了语句,这也就使其不返回一个值。在接下来的探索中记住函数和表达式都返回值就行了。
总结:语句以分号结尾,没有返回值。表达式最后一行末尾不加分号,有返回值。
5.5 函数的返回值
函数可以向调用它的代码返回值。我们并不对返回值命名,不过会在一个箭头( -> )后声明它的类型。
在 Rust 中,函数的返回值等同于函数体最后一个表达式的值。这是一个有返回值的函数的例子:
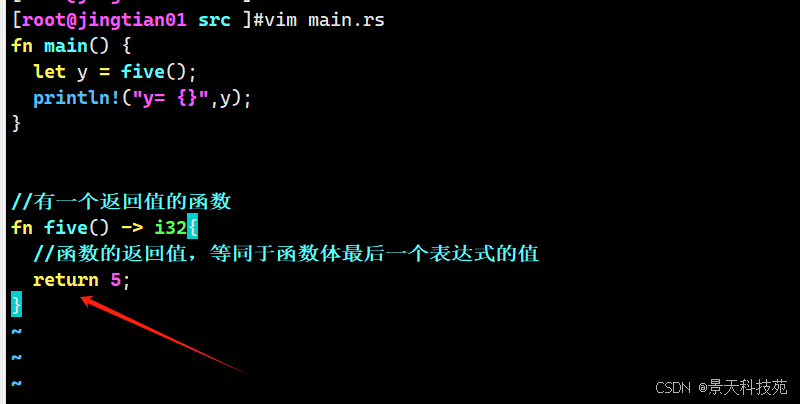
fn main() { let y = five(); println!("y= {}",y); } //有一个返回值的函数 fn five() -> i32{ //函数的返回值,等同于函数体最后一个表达式的值 5 }运行

在函数 five 中并没有函数调用、宏、甚至也没有 let 语句————只有数字 5 自身。
这在 Rust 中是一个完全有效的函数。注意函数的返回值类型也被指定了,就是 -> i32 。
函数 five 没有参数并定义了返回值类型,不过函数体只有单单一个 5 也没有分号,因为这是我们想要返回值的表达式。
如果函数体中的5后面加了分号,就表示语句,就没有返回值,则该函数就没有返回值,与定义的返回i32类型的值相矛盾,编译就会报错
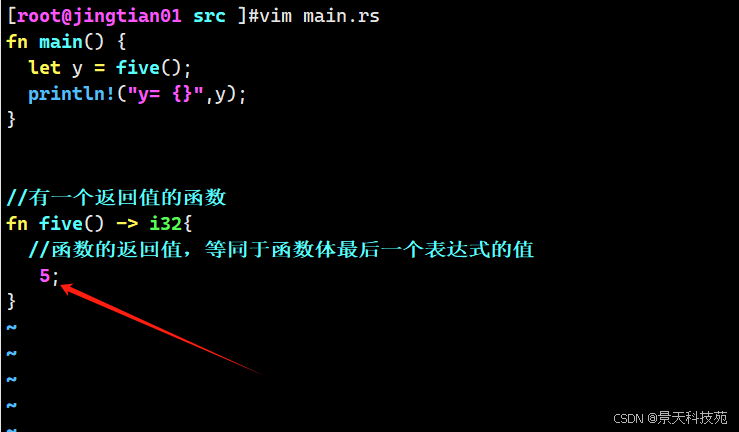
编译报错
如果,想要用语句作为返回值,可以加上return关键字

多个返回值的函数
Rust函数可以返回多个值。在Rust中,函数可以通过元组(tuple)返回多个值。例如:
fn main() { //接收多个返回值 let (name,age) = get_name_and_age(); println!("name= {}, age={}",name,age); } //多个返回值的函数 fn get_name_and_age() -> (String, u32) { let name = String::from("Alice"); let age = 30; (name, age) }
6、注释
所有编程语言都力求使其代码易于理解,不过有时需要提供额外的解释。
在这种情况下,程序员在源码中留下记录,或者 注释(comments),编译器会忽略它们不过其他阅读代码的人可能会用得上。
6.1 单行注释
在 Rust 中,注释必须以两道斜杠//开始,并持续到本行的结尾。对于超过一行的注释,需要在每一行都加上 // ,
6.2 文档注释
Rust 的文档注释是一种特殊的注释格式,用于生成 HTML 文档(通过 rustdoc 工具)。Rust 的文档系统非常强大,支持 Markdown 格式,并且能够测试文档中的代码示例。
1) 单行文档注释
/// 这是行文档注释 /// 通常用于函数、模块或类型的文档 /// 支持 **Markdown** 格式 fn my_function() {}2)块文档注释
/** * 这是块文档注释 * 可以跨越多行 * 同样支持 **Markdown** 格式 */ struct MyStruct;
3)模块文档注释
//! 这是模块级文档注释 //! 通常写在模块文件的顶部 //! 用于描述整个模块的功能
7、控制流
通过条件是不是为真来决定是否执行某些代码,或者根据条件是否为真来重复运行一段代码是大部分编程语言的基本组成部分。
Rust 代码中最常见的用来控制执行流的结构是 if 表达式和循环。
7.1 if表达式
if 表达式允许根据条件执行不同的代码分支。我们提供一个条件并表示 如果符合这个条件,运行这段代码。如果条件不满足,不运行这段代码。
fn main() { let number = 3; if number
所有的 if 表达式都以 if 关键字开头,其后跟一个条件。在这个例子中,条件检查变量 number 是否有一个小于 5 的
值。在条件为真时希望执行的代码块位于紧跟条件之后的大括号中。 if 表达式中与条件关联的代码块有时被叫做arms。
也可以包含一个可选的 else 表达式来提供一个在条件为假时应当执行的代码块,这里我们就这么做了。
如果不提供 else 表达式并且条件为假时,程序会直接忽略 if 代码块并继续执行下面的代码。
另外值得注意的是代码中的条件 必须 是 bool 值。如果想看看条件不是 bool 值时会发生什么,请看如下代码:
fn main() { let number = 3; if number { println!("number was three"); } }如果条件不是bool,编译会报错
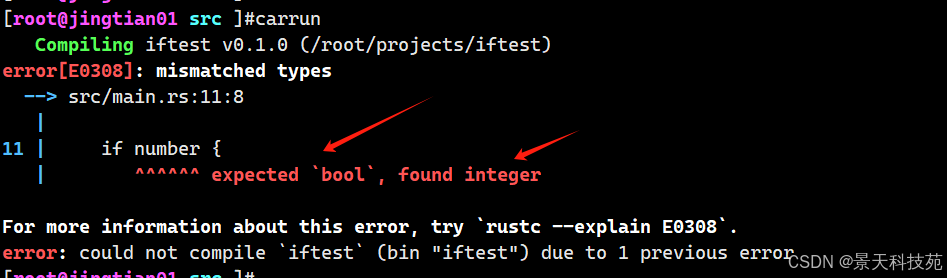
这个错误表明 Rust 期望一个 bool 不过却得到了一个整型。不像 Ruby 或 JavaScript 这样的语言,Rust 并不会尝试自动地将非布尔值转换为布尔值。
必须总是显式地使用布尔值作为 if 的条件。例如,如果想要 if 代码块只在一个数字不等于 0 时执行,可以把 if 表达式修改成下面这样:
fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } }使用 else if 实现多重条件
可以将 else if 表达式与 if 和 else 组合来实现多重条件。例如:
fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
当执行这个程序,它按顺序检查每个 if 表达式并执行第一个条件为真的代码块。注意即使 6 可以被 2 整除,也不会出
现 number is divisible by 2 的输出,更不会出现 else 块中的 number is not divisible by 4, 3, or 2 。原因是 Rust 只会
执行第一个条件为真的代码块,并且一旦它找到一个以后,甚至就不会检查剩下的条件了。
使用过多的 else if 表达式会使代码显得杂乱无章,所以如果有多于一个 else if ,最好重构代码。为此后面我们会介绍
Rust 中一个叫做 match 的强大的分支结构(branching construct)。
在 let 语句中使用 if
因为 if 是一个表达式,我们可以在 let 语句的右侧使用if,例如:
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {}", number); }
注意,条件表达式中的数字末尾不能加分号,如果非要加分号,可以使用return
还记得代码块的值是其最后一个表达式的值,以及数字本身也是一个表达式吗。在这个例子中,整个 if 表达式的值依赖哪个代码块被执行。
这意味着 if 的每个分支的可能的返回值都必须是相同类型;在上面的示例中, if 分支和 else 分支的结果都是 i32 整型。如果它们的类型不匹配,如下面这个例子,则会出现一个错误:
fn main() { let condition = true; let number = if condition { 5 } else { "six" }; println!("The value of number is: {}", number); }if和else返回的值类型不同,编译会报错
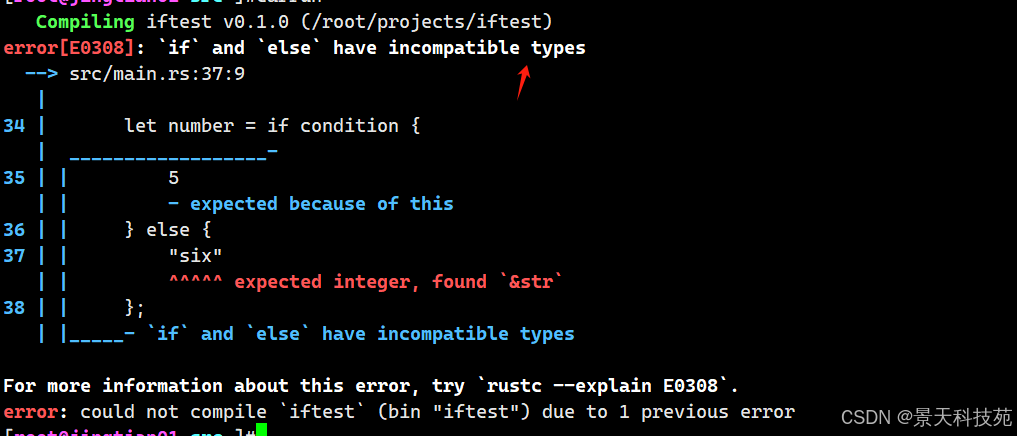
if 代码块的表达式返回一个整型,而 else 代码块返回一个字符串。这并不可行,因为变量必须只有一个类型。Rust
需要在编译时就确切的知道 number 变量的类型,这样它就可以在编译时证明其他使用 number 变量的地方它的类型是有
效的。Rust 并不能够让 number 的类型只能在运行时确定的情况下工作;这样会使编译器变得更复杂而且只能为代码提
供更少的保障,因为它不得不记录所有变量的多种可能的类型。
7.2 循环语句
对于多次执行同一段代码是很常用的,Rust 为此提供了多种 循环(loops)。
一个循环执行循环体中的代码直到结尾并紧接着回到开头继续执行。为了实验一下循环,让我们创建一个叫做 loops 的新项目。
Rust 有三种循环类型: loop 、 while 和 for 。让我们每一个都试试。
1)loop循环
使用 loop 重复执行代码
loop 关键字告诉 Rust 一遍又一遍地执行一段代码直到你明确要求停止。
语法:
loop{
循环体
}
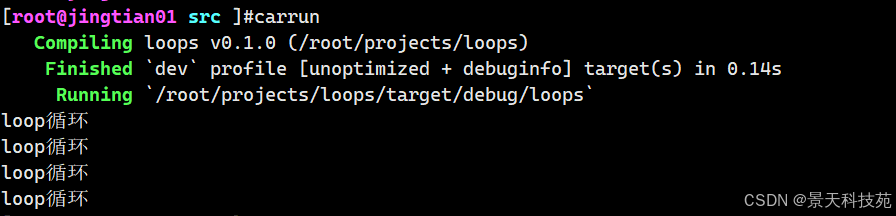
use std::thread::sleep; use std::time::Duration; fn main() { //loop循环 loop { println!("loop循环"); sleep(Duration::from_secs(1)); } }每秒执行一次
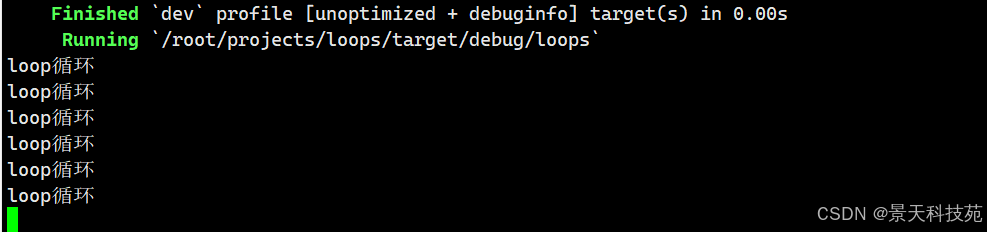
当执行这个程序,我们会看到 loop循环被连续每秒一次的打印直到我们手动停止程序
幸运的是,Rust 提供了另一个更可靠的方式来退出循环。可以使用 break 关键字来告诉程序何时停止执行循环。
use std::thread::sleep; use std::time::Duration; fn main() { //loop循环 let mut i = 1; loop { println!("loop循环"); sleep(Duration::from_secs(1)); i += 1; if i ==5 { break; } } }设置退出条件,当i=5时,退出循环
为什么 Rust 没有 i++?
Rust 设计团队决定不包含 i++ 和 ++i 运算符,主要出于以下考虑:
清晰性:i += 1 比 i++ 更明确地表达了意图
减少混淆:避免 i++ 和 ++i 的前置/后置区别带来的困惑
一致性:Rust 倾向于使用更明确的操作符
减少错误:消除了与这些操作符相关的潜在错误来源
loop循环也可以给变量赋值
fn main() { //loop循环 let mut i = 1; let y = loop { println!("loop循环"); i += 1; if i ==5 { break i*2; //break后面,就是返回的值 } }; println!("y = {}",y) }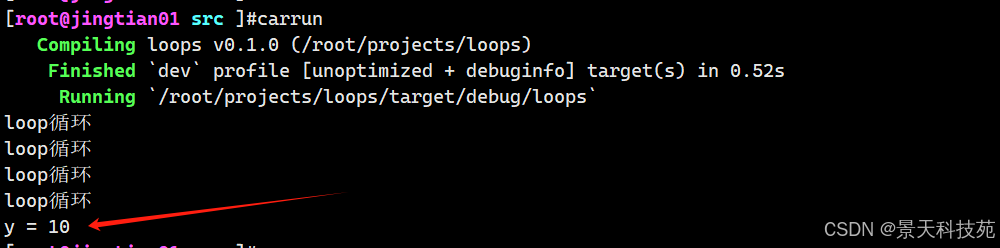
2)while循环
while循环在程序中计算循环的条件也很常见。当条件为真,执行循环。当条件不再为真,调用 break 停止循环。
这个循环类型可以通过组合 loop 、 if 、 else 和 break 来实现;如果你喜欢的话,现在就可以在程序中试试。
然而,这个模式太常见了以至于 Rust 为此提供了一个内建的语言结构,它被称为 while 循环。
语法:
while 条件 {
循环体
}
这个条件,必须是bool类型的结果
fn main() { //while循环 let mut i = 3; while i != 0{ println!("i={}",i); i -= 1; }; println!("循环结束") }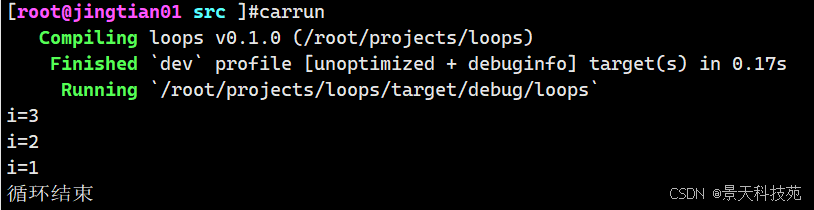
这个结构消除了很多需要嵌套使用 loop 、 if 、 else 和 break 的代码,这样显得更加清楚。当条件为真就执行,否则退出循环。
3)for循环
可以使用for循环,遍历数组中的元素。或者一定范围的数据
语法: for i in 迭代器/范围 {}
遍历范围
// 遍历 0 到 4 (不包括 5) for i in 0..5 { println!("{}", i); }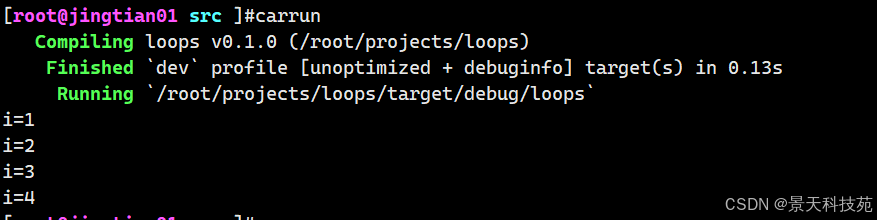
// 遍历 0 到 5 (包括 5) for i in 0..=5 { println!("{}", i); }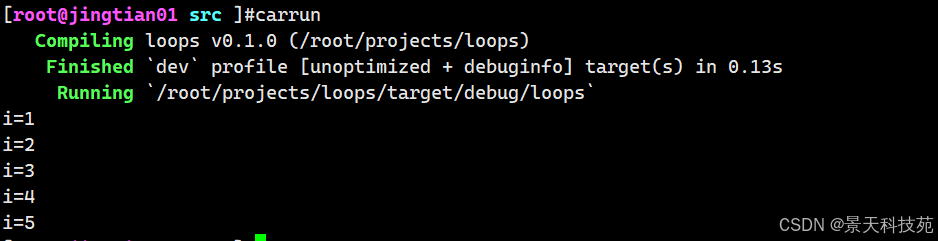
遍历迭代器
fn main() { // for循环 let a = [1,2,3,42,1,2133]; for i in a.iter(){ println!("数组中的元素有:{}",i) } }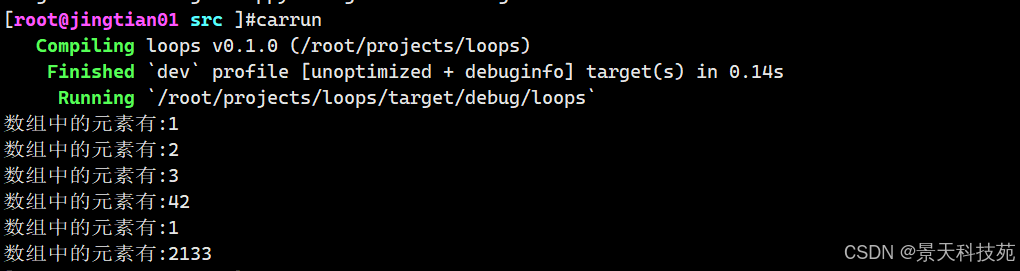
也可以直接遍历数组
fn main() { //遍历集合 let a = [1,2,3,42,1,2133]; for i in a{ println!("集合中的元素有:{}",i) } }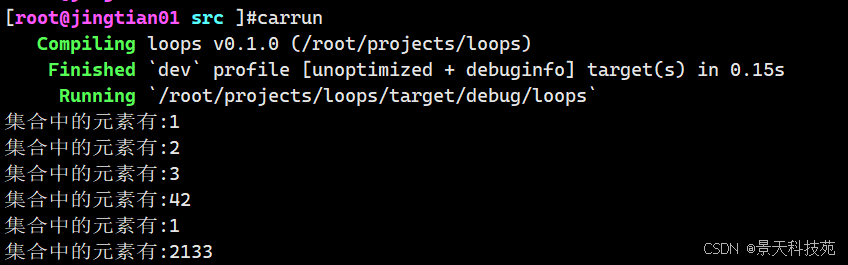
使用递归计算斐波那契数
fn main() { //生成斐波那契数 let a = feibo2(120); println!("a = {}", a) } //斐波那契数列函数 fn feibo(n: u32) -> u128 { let (mut a, mut b) = (0u128, 1u128); for _ in 0..n { let temp = a; a = b; b = temp + b; } a } //方法二,采用递归计算 fn feibo2(n: u32) -> u128 { if n == 1 || n == 2 { return 1; } else { //第n个数是第n-1个数与第n-2个数的和 return feibo(n - 2) + feibo(n - 1); } }秒出结果,比go快多了

8、总结
通过本文的学习,相信大家已经对Rust的语法有了深入的了解,赶快去实践下吧。



