
spheresharding-jdbc5.5.2 springboot3 集成 分库分表+读写分离库

1. 依赖环境
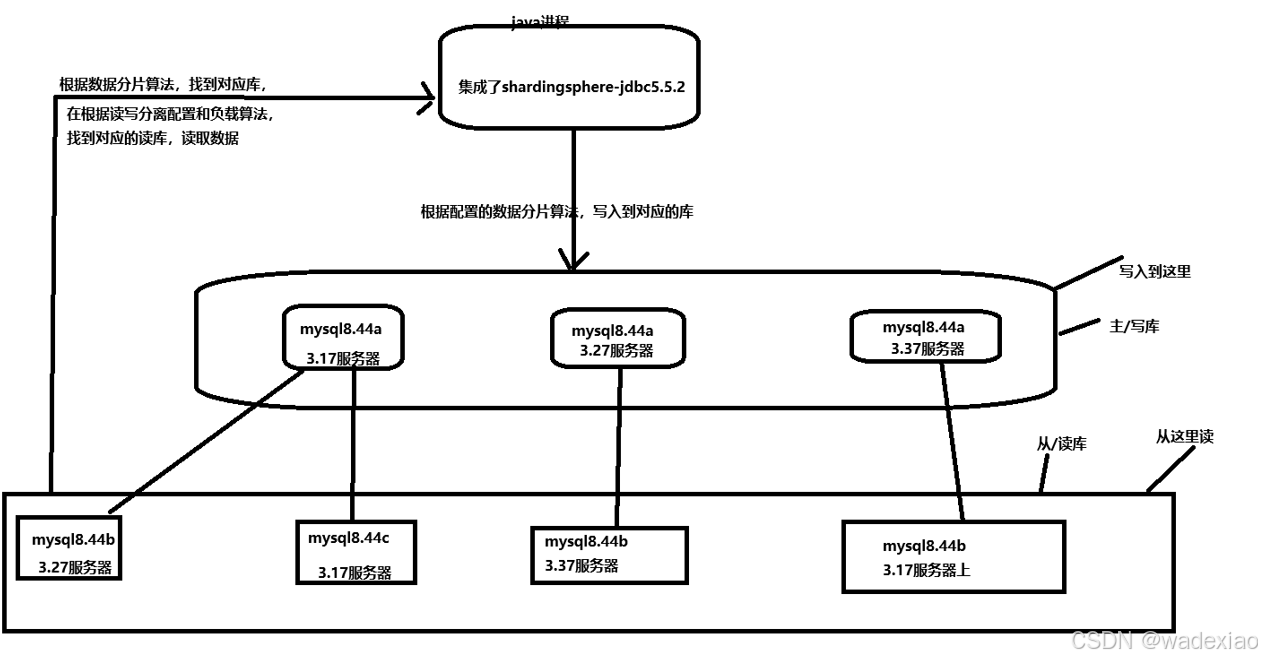
关于如何搭建参考之前的文章centos7 mysql8.44 主从/读写数据库搭建 (二进制包安装方式)
1.1 创建数据库和表
在三个主/写库中操作就行了,从库会自动同步
1.1.1 需要 分库分表的 的表和广播表
CREATE DATABASE a_db_order; CREATE TABLE `t_order0` ( `id` bigint NOT NULL, `order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `user_id` bigint NULL DEFAULT NULL, `amount` decimal(10, 2) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; CREATE TABLE `t_order1` ( `id` bigint NOT NULL, `order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `user_id` bigint NULL DEFAULT NULL, `amount` decimal(10, 2) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; CREATE TABLE `t_order_item0` ( `id` bigint NOT NULL, `order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `user_id` bigint NULL DEFAULT NULL, `price` decimal(10, 2) NULL DEFAULT NULL, `count` int NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; CREATE TABLE `t_order_item1` ( `id` bigint NOT NULL, `order_no` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `user_id` bigint NULL DEFAULT NULL, `price` decimal(10, 2) NULL DEFAULT NULL, `count` int NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; CREATE TABLE `t_dict` ( `id` bigint NOT NULL, `dict_type` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = DYNAMIC;
1.1.2 单表(数据量很小,不需要分库和分表)
CREATE TABLE `t_user` ( `id` int UNSIGNED NOT NULL AUTO_INCREMENT, `name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL, `age` int NOT NULL, `job` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL, `city` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL, `description` varchar(1024) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = DYNAMIC;
2. 创建项目,导入依赖
springboot: 3.4.2
jdk:17
shardingsphere-jdbc: 5.5.2
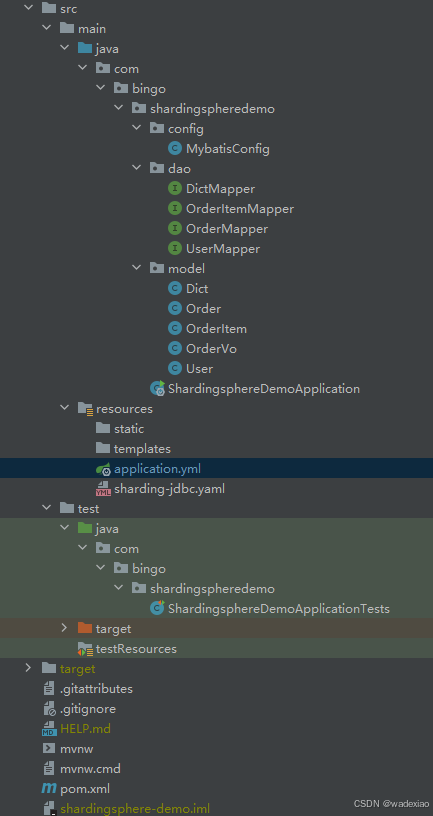
2.1 具体pom文件入下
4.0.0
org.springframework.boot
spring-boot-starter-parent
3.4.2
com.bingo
shardingsphere-demo
0.0.1-SNAPSHOT
shardingsphere-demo
shardingsphere-demo
17
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
true
mysql
mysql-connector-java
8.0.33
com.baomidou
mybatis-plus-spring-boot3-starter
3.5.10.1
org.apache.shardingsphere
shardingsphere-jdbc
5.5.2
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.apache.maven.plugins
maven-compiler-plugin
org.springframework.boot
spring-boot-maven-plugin
3. springboot 配置文件编写
3.1 application.yml 文件编写
spring:
application:
name: shardingsphere-demo
# datasource:
# driver-class-name: com.mysql.cj.jdbc.Driver
# url: jdbc:mysql://192.168.3.17:33067/test?serverTimezone=Asia/Shanghai
# username: root
# password: ******
# 配置 DataSource Driver
datasource:
driver-class-name: org.apache.shardingsphere.driver.ShardingSphereDriver
# 指定 YAML 配置文件 sharding-jdbc.yaml
url: jdbc:shardingsphere:classpath:sharding-jdbc.yaml
3.2 sharding-jdbc.yaml 文件编写
# 主要是配置,官网文档地址https://shardingsphere.apache.org/document/5.5.2/cn/user-manual/shardingsphere-jdbc/yaml-config/mode/
mode:
type: Standalone
dataSources:
ds_0: # 数据源名称317a_master
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.17:33067/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
ds_1: # 327a_master
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.27:33067/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
ds_2: #337a_master
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.37:33067/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
ds_3: # 数据源名称317b_slave-of-337a
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.17:33068/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
ds_4: # 数据源名称317c_slave-of-317a
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.17:33069/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
ds_5: # 数据源名称327b_slave-of-337a
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.27:33068/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
ds_6: # 数据源名称337b_slave-of-327a
dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 数据源完整类名
driverClassName: com.mysql.cj.jdbc.Driver # 数据库驱动类名,以数据库连接池自身配置为准
jdbcUrl: jdbc:mysql://192.168.3.37:33068/a_db_order?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true # 数据库 URL 连接,以数据库连接池自身配置为
username: root # 数据库用户名,以数据库连接池自身配置为准
password: ****** # 数据库密码,以数据库连接池自身配置为准
rules:
#读写分离
- !READWRITE_SPLITTING
dataSourceGroups:
readwrite_ds_0: # 这个名字可以自己定义,数据分片的时候会用到,注意下,这一个配置卡我一天多
writeDataSourceName: ds_0 #写库数据源的名称,dataSources 下定义的数据源
readDataSourceNames:
- ds_5 #读库数据源的名称,ds_0 的读/从库,dataSources 下定义的数据源
- ds_4 #读库数据源的名称,ds_0 的读/从库,dataSources 下定义的数据源
transactionalReadQueryStrategy: PRIMARY
loadBalancerName: random
readwrite_ds_1: #第二个读写库
writeDataSourceName: ds_1
readDataSourceNames:
- ds_6
transactionalReadQueryStrategy: PRIMARY
loadBalancerName: random
readwrite_ds_2: #第三个读写库
writeDataSourceName: ds_2
readDataSourceNames:
- ds_3
transactionalReadQueryStrategy: PRIMARY
loadBalancerName: random # 算法名称,对应loadBalancers 下的random
# 负载均衡算法,配置的轮巡 自带有三种,可参考官网
# https://shardingsphere.apache.org/document/5.5.2/cn/user-manual/common-config/builtin-algorithm/load-balance/
loadBalancers:
random:
type: ROUND_ROBIN
# 数据分片,数据究竟写入/读取 哪个库,哪个表,按什么算法来确定
- !SHARDING
tables:
t_order: # 表名,数据库里是t_order0 ,t_order1 这里写 t_order
# 由数据源名 + 表名组成(参考 Inline 语法规则)
#这里的readwrite_ds_0/1/2 就是上边读写分离定义的 数据源
# 也可以写成readwrite_ds_0.t_order0,readwrite_ds_0.t_order1,readwrite_ds_1.t_order0.....
actualDataNodes: readwrite_ds_${0..2}.t_order${0..1}
databaseStrategy: # 数据库分片策略
# 有三种 standard,complex hint,官网还是比较详细的,就是太分散
# https://shardingsphere.apache.org/document/5.5.2/cn/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding/
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline # 这是一个算法名称,在下面shardingAlgorithms 下定义的
tableStrategy: # 数据库表分片策略
standard:
shardingColumn: order_no
shardingAlgorithmName: t_order_inline #这里是个名字,下边有定义
keyGenerateStrategy:
column: id #分布式id字段是哪个
keyGeneratorName: snowflake #这里是个名字,下边有定义
t_order_item:
actualDataNodes: readwrite_ds_${0..2}.t_order_item${0..1}
databaseStrategy:
standard:
shardingColumn: user_id # 分片字段
shardingAlgorithmName: database_inline #这里是个名字,下边有定义
tableStrategy:
standard:
shardingColumn: order_no # 分片字段
shardingAlgorithmName: t_order_item_inline #这里是个名字,下边有定义
keyGenerateStrategy:
column: id #分布式id字段是哪个
keyGeneratorName: snowflake #这里是个名字,下边有定义
# 这是什么意思? 订单表拆分成订单主表,订单子表,都通过order_no 分片就需要绑定到一块,查询完整订单的时候好查询
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy: #没有默认的分库策略
none:
defaultTableStrategy: # 没有默认的分表策略
none:
#分片算法
shardingAlgorithms:
database_inline: # 自定义的算法名称,上边有用到
# 类型有多钟可参考官网 https://shardingsphere.apache.org/document/5.5.2/cn/user-manual/common-config/builtin-algorithm/sharding/
type: INLINE
props:
# 根据用户id 对3(因为有3个主/写数据库)取余数,type 为INLINE 的表达式写发可以找官网
algorithm-expression: readwrite_ds_${user_id % 3}
t_order_inline: # 自定义的算法名称,上边有用到
type: CLASS_BASED
props:
strategy: STANDARD
# 下边类是自己写的就是自定义分片算法,这个是shardingsphere 自带的
# 就是对分片字段(在使用t_order_inline的算法那里有定义) hash 在通过sharding-count的数量取余分片
algorithmClassName: org.apache.shardingsphere.sharding.algorithm.sharding.mod.HashModShardingAlgorithm
sharding-count: 2
t_order_item_inline: # 自定义的算法名称,上边有用到
type: CLASS_BASED
props:
strategy: STANDARD
# 下边类是自己写的就是自定义分片算法,这个是shardingsphere 自带的
# 就是对 分片字段(在使用t_order_item_inline的算法那里有定义) hash 在通过sharding-count的数量取余分片
algorithmClassName: org.apache.shardingsphere.sharding.algorithm.sharding.mod.HashModShardingAlgorithm
sharding-count: 2
keyGenerators: # # 分布式序列/id 算法配置
snowflake:
type: SNOWFLAKE
props:
worker-id: 123 # 工作节点 ID
max-tolerate-time-difference-milliseconds: 100
- !SINGLE
tables:
# MySQL 风格
- readwrite_ds_0.t_user # 加载指定单表 readwrite_ds_0为读写分离数据源
defaultDataSource: readwrite_ds_0
- !BROADCAST
tables: # 广播表规则列表,广播表就是在每一个分库上都有一份
- t_dict
props:
sql-show: true # 日志显示sql
max-tolerate-time-difference-milliseconds: 10000
4. 代码编写
4.1 订单表Order相关
@TableName("t_order")
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Order {
// 这里写成none 因为分布式id 有shardingsphere 生成了
// 不要写成 long id; 这玩意卡我一天
@TableId(type = IdType.NONE)
private Long id =-1L;
private String orderNo;
private long userId;
private BigDecimal amount;
}
@Mapper
public interface OrderMapper extends BaseMapper {
// 这里要写逻辑表名, 并不是实际的表名
// 分库的联表查询
@Select({"SELECT o.order_no, SUM(i.price * i.count) AS amount FROM t_order o JOIN t_order_item i ON o.order_no = i.order_no GROUP BY o.order_no"})
List getOrderAmount();
}
@Data
public class OrderVo {
// 订单号
private String orderNo;
//订单价钱
private BigDecimal amount;
}
4.2 订单子表OrderItem相关
@TableName("t_order_item")
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderItem {
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//没测,感兴趣可以自己测下,配置这个到底是mysbatis-plus 还是 shardingsphere-jdbc 生成的
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal price;
private Integer count;
}
@Mapper
public interface OrderItemMapper extends BaseMapper {
}
4.3 广播表Dict 相关
@TableName("t_dict")
@Data
public class Dict {
//可以使用MyBatisPlus的雪花算法
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String dictType;
}
@Mapper
public interface DictMapper extends BaseMapper {
}
4.4 单表-用户表相关
@TableName("t_user")
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private int age;
private String job;
private String city;
private String description;
}
@Mapper
public interface UserMapper extends BaseMapper {
}
4.5 编写单元测试
@SpringBootTest(classes = ShardingsphereDemoApplication.class)
class ShardingsphereDemoApplicationTests {
@Resource
private OrderMapper orderMapper;
@Resource
private OrderItemMapper orderItemMapper;
@Resource
private DictMapper dictMapper;
/**
* 插入单库单表的user 数据
*/
@Test
void testShardingsphereMysql() {
for (int i = 0; i
4.6 测试验证
4.6.1 执行testShardingsphereMysql 单元测试
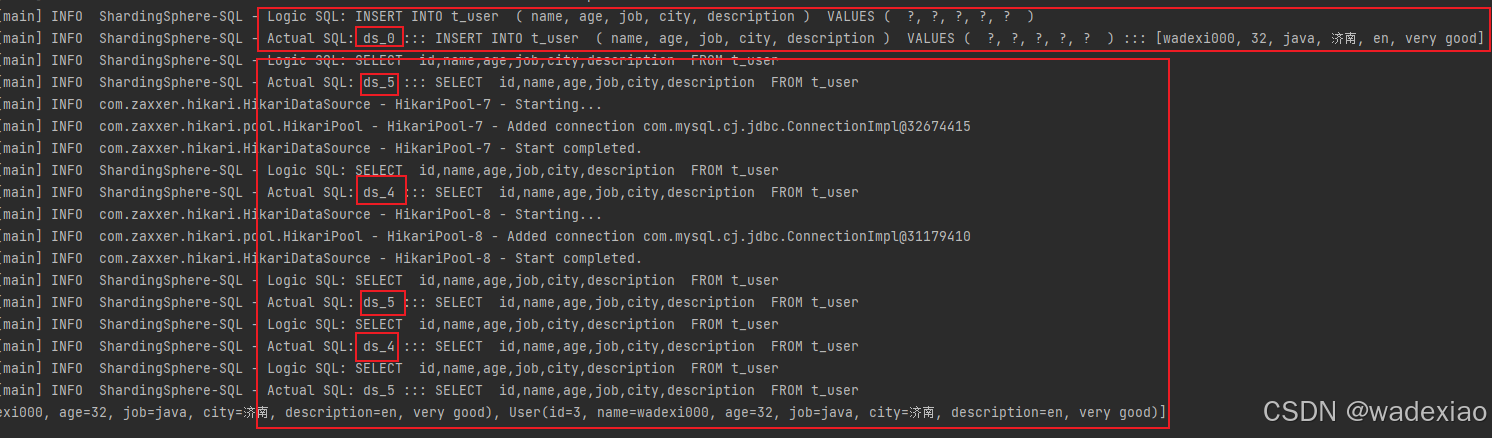
上边日志可以看出,插入用户数据只在ds_0 这一个主库上,没有分库,因为我们配置了单表
查询在ds_0 的从库ds_4,ds_5上 查询的
4.6.2 执行testShardingsphereMysql2 单元测试
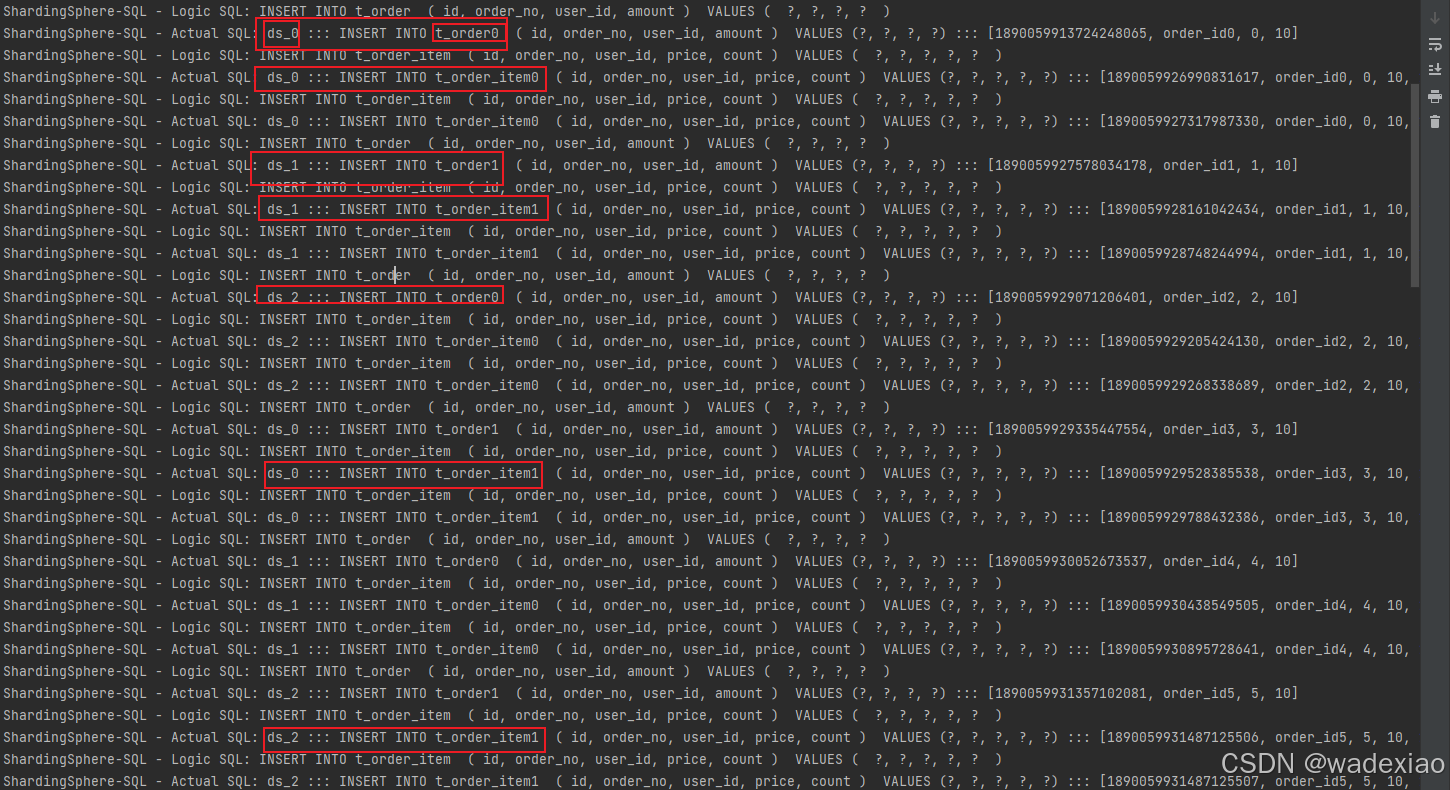
上边日志可以看出订单数据 根据配置的分库分表算法 分别写入 ds_0/1/2 三个写/主库 的不同分表中了

上边日志可以看出,查询单边订单数据 SELECT id,order_no,user_id,amount FROM t_order
实际上 是从 ds_3,ds_4,ds_5,ds_6 从/读库 上边 union 得到的数据

伤害日志可以看出,联表查询SELECT o.order_no, SUM(i.price * i.count AS amount FROM t_order o JOIN t_order_item i ON o.order_no = i.order_no GROUP BY o.order_no
也是从不同的分库分表中 查询出来的
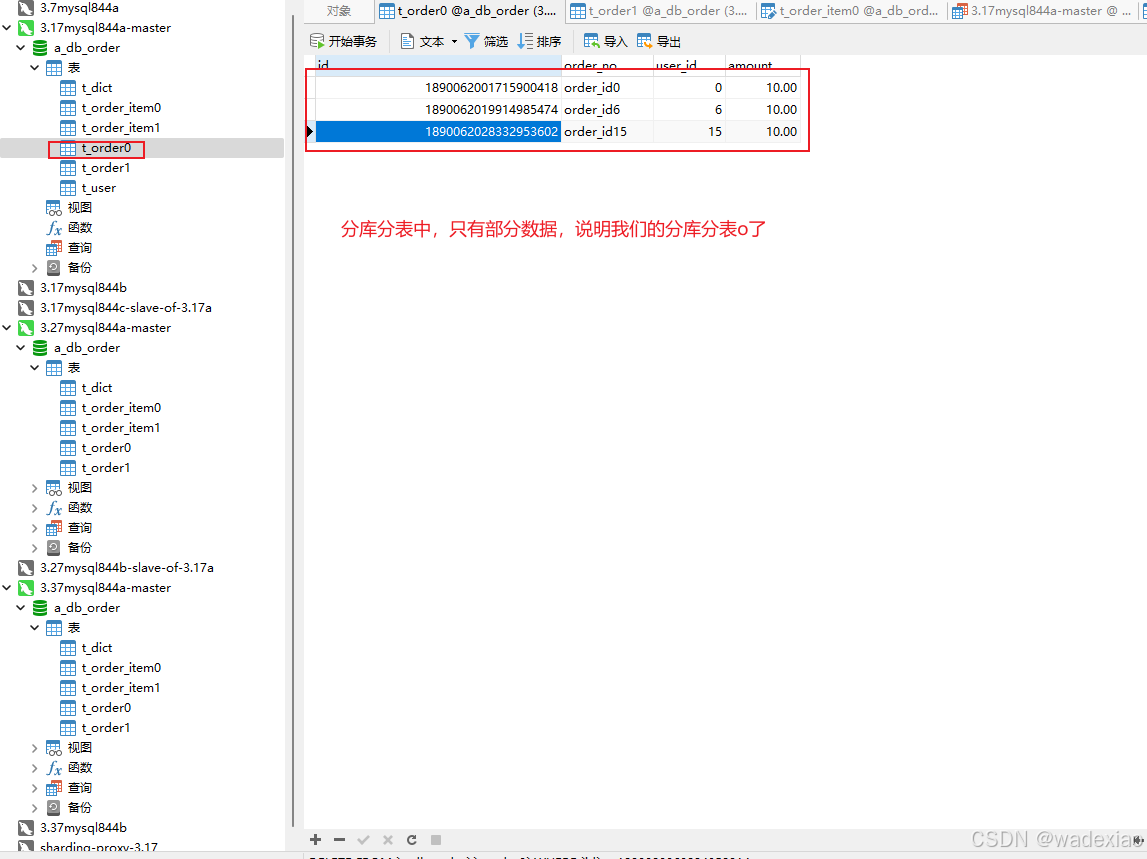
4.6.3 执行testShardingsphereMysql3 单元测试

上边日志可以看,广播表,在每一个 写/主库上都写了一遍
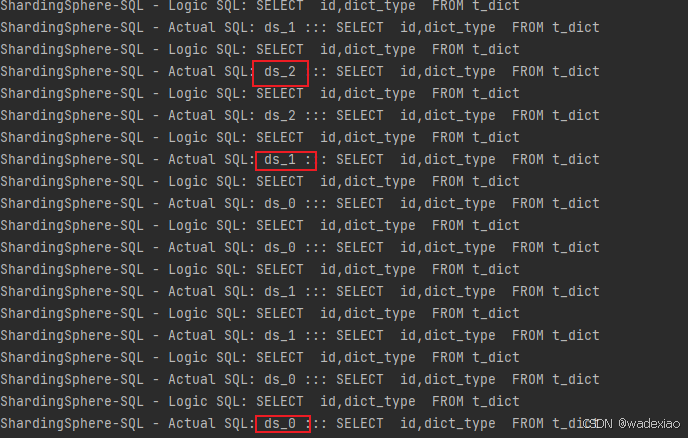
上边日志可以看出广播表多次读取还是从主库上读的
5. 广播表遗留问题
在 ShardingSphere 中,读写分离(Read-Write Splitting)是一种常用的数据库访问模式,用以提升读取操作的性能和扩展性。然而,对于广播表,由于其数据的一致性需求,通常不适用读写分离策略。这是因为读写分离通常涉及到将读操作和写操作路由到不同的数据库节点,而广播表的所有数据需要在所有节点上都是相同的。
有说5.2 后可以这样配置,没生效,官网也没有注意看到
rules:
- !READWRITE_SPLITTING
dataSources:
ds_0:
writeDataSourceName: master_ds
readDataSourceNames:
- slave_ds_0
- slave_ds_1
loadBalancerName: round_robin
loadBalancers:
round_robin:
type: ROUND_ROBIN
props:
# 允许广播表的查询路由到从库
broadcastTableReadWriteSplitting: true
有懂的朋友给评论下
源码
源码地址
参考链接
shardingsphere5.5.2 官网文档
ShardingSphere5分库分表(详细)
特别感谢-SpringBoot 3.x.x整合ShardingSphere-JDBC 5.5.0 实现读写分离,数据分片,数据脱敏功能







