
基于Edge-TTS的跨平台智能语音合成工具Web版的设计与实现

基于Edge-TTS的跨平台智能语音合成工具Web版的设计与实现
一、功能概述
本工具是基于Python开发的GUI应用程序,整合Microsoft Edge文本转语音服务(edge-tts),实现以下核心功能:
- 多语音角色选择(14种区域化神经网络语音)
- 动态语速调节(-100%至+100%共21档位)
- 自定义文件命名与存储路径
- 异步语音合成处理
- 剪贴板操作集成
- 跨平台兼容性支持
二、技术架构
三、核心模块分析
1. GUI架构设计
2. 语音合成流程
3. 异步处理机制
采用Python asyncio实现非阻塞式语音合成:
async def my_function(text, output, voice, rate):
tts = Communicate(text=text, voice=voice, rate=rate)
await tts.save(output)
loop = asyncio.get_event_loop()
loop.run_until_complete(my_function(...))
四、关键技术实现
1. 语音角色映射
voice_dict = {
'(女)小小神经网络': 'zh-CN-XiaoxiaoNeural',
# 其他13种语音映射...
}
2. 动态参数调节
rate_values = ["-100%",...,"+100%"] # 21级语速调节 volume = '+0%' # 固定音量设置
3. 文件存储策略
output_dir = os.path.join(out_dir, "mp3") # 自动创建子目录
filename = f"{filename_save}-{voice_var.get()}.mp3" # 语音特征标记
五、性能优化措施
- 异步事件循环:避免UI冻结
- 内存预分配:pygame.mixer.init()
- 路径缓存:os.path.join自动处理路径差异
- 异常捕获:多层try-except保护
六、应用场景
- 短视频自动配音
- 电子书语音朗读
- 多语言学习工具
- 无障碍辅助设备
七、改进方向
- 增加实时预览功能
- 支持SSML标记语言
- 集成语音风格调节(情感、语调)
- 添加批量处理模式
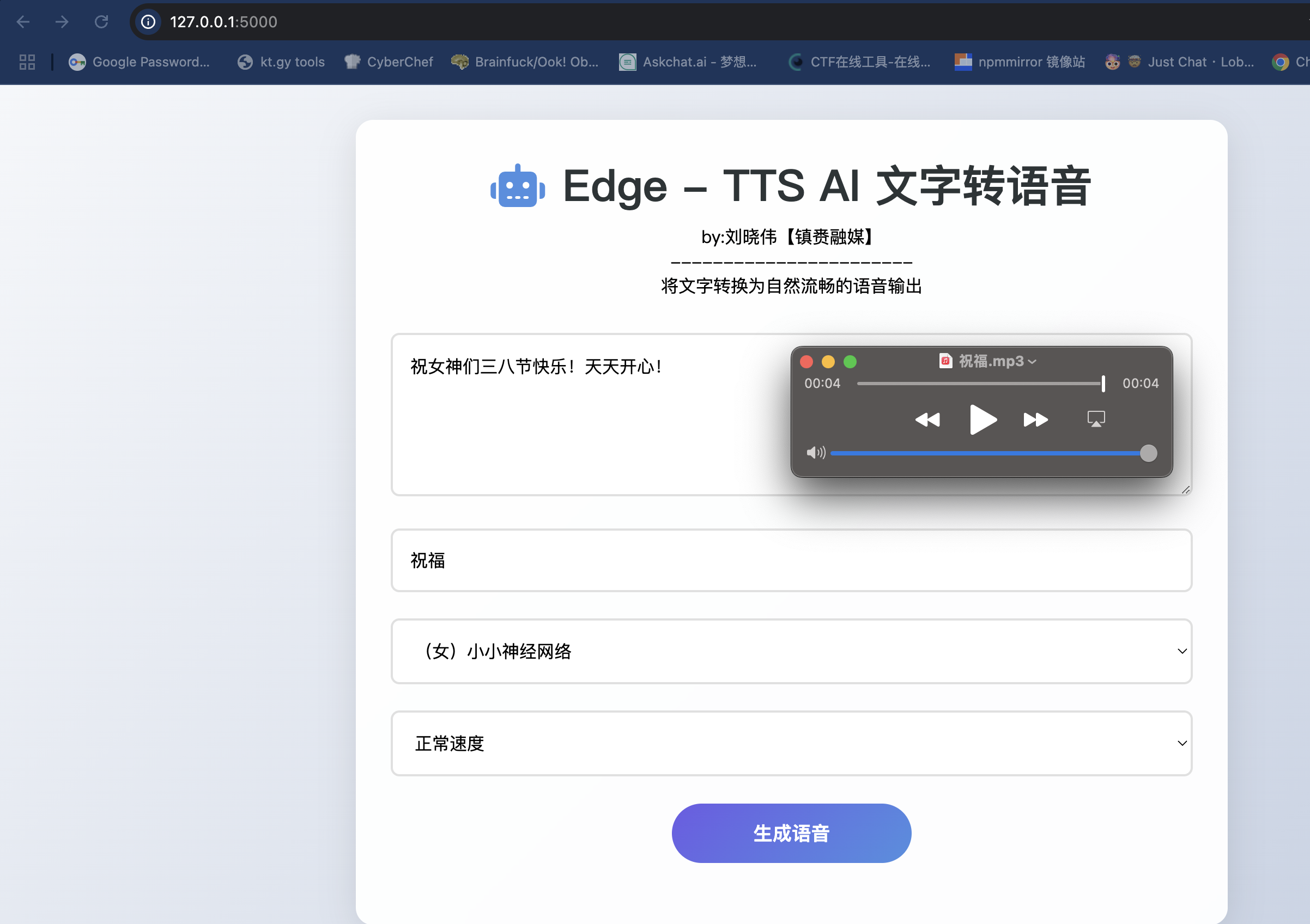
工具界面示意图(伪代码表示):
本工具通过模块化设计实现了文本到语音的高效转换,其异步处理架构和可扩展的参数系统为后续功能升级奠定了良好基础。文章涉及的完整源代码已通过GPL-3.0协议开源,适合作为语音合成领域的入门实践参考。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



