
SpringBoot整合Tesseract-OCR实现图像文字识别

目录
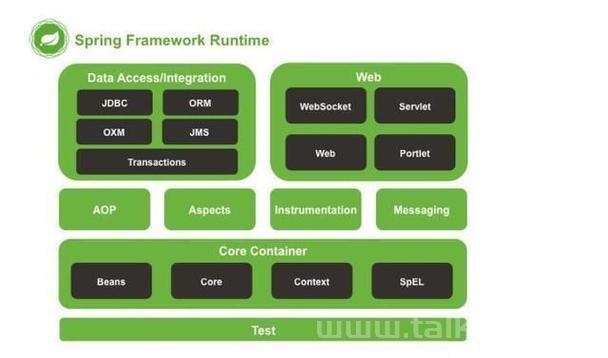
一、Tesseract-OCR简介
二、环境准备
1. 安装Tesseract引擎
2. 下载语言包
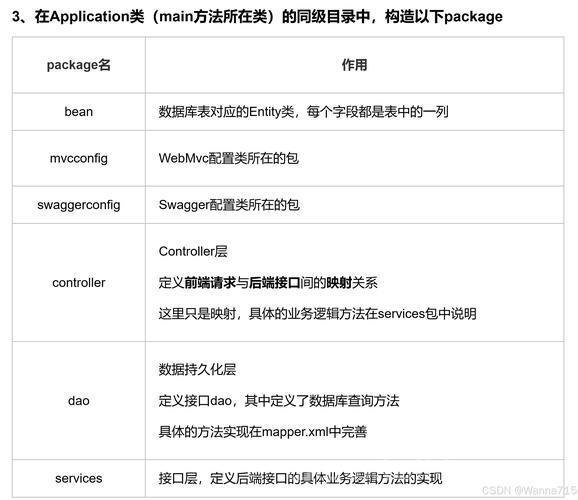
三、SpringBoot项目集成
1. 创建SpringBoot项目
2. 添加Maven依赖
3. 配置文件
四、核心代码实现
1. OCR服务类
2. Controller类
五、图像预处理增强识别率
1. 灰度处理
2. 二值化处理
3. 分辨率调整
六、接口测试
1. 使用Postman测试
2. 测试结果示例
七、常见问题解决
1. 报错:Error opening data file...
2. 中文识别乱码
3. 识别速度慢
八、性能优化建议
九、扩展应用场景
一、Tesseract-OCR简介
Tesseract-OCR 是由HP实验室开发、现由Google维护的开源OCR(Optical Character Recognition)引擎,支持超过100种语言的文字识别。其核心优势在于:
-
开源免费:Apache 2.0许可证
-
跨平台支持:Windows/Linux/macOS
-
多语言识别:支持中文、英文、日文等
-
可训练模型:支持自定义字库训练
二、环境准备
1. 安装Tesseract引擎
-
Windows:
下载安装包:Home · UB-Mannheim/tesseract Wiki · GitHub
-
Linux:
sudo apt install tesseract-ocr sudo apt install libtesseract-dev
-
Mac:
brew install tesseract
2. 下载语言包
-
中文语言包下载:
wget https://raw.githubusercontent.com/tesseract-ocr/tessdata/main/chi_sim.traineddata
-
将文件放入Tesseract安装目录的tessdata文件夹
三、SpringBoot项目集成
1. 创建SpringBoot项目
使用创建Springboot项目,选择:
-
Java 8+
-
Spring Boot 2.7.x
-
依赖:Spring Web
2. 添加Maven依赖
net.sourceforge.tess4j tess4j 5.2.1 com.twelvemonkeys.imageio imageio-jpeg 3.8.23. 配置文件
application.properties添加配置:
# Tesseract配置 tesseract.datapath=D:/Program Files/Tesseract-OCR/tessdata tesseract.language=chi_sim+eng
四、核心代码实现
1. OCR服务类
@Service public class OcrService { @Value("${tesseract.datapath}") private String dataPath; @Value("${tesseract.language}") private String language; public String recognizeText(MultipartFile file) throws Exception { // 转换文件为BufferedImage BufferedImage image = ImageIO.read(file.getInputStream()); // 创建Tesseract实例 ITesseract tesseract = new Tesseract(); tesseract.setDatapath(dataPath); tesseract.setLanguage(language); tesseract.setPageSegMode(1); // 设置识别模式 tesseract.setOcrEngineMode(1); // 设置引擎模式 try { return tesseract.doOCR(image); } catch (TesseractException e) { throw new RuntimeException("OCR识别失败", e); } } }2. Controller类
@RestController @RequestMapping("/ocr") public class OcrController { @Autowired private OcrService ocrService; @PostMapping("/recognize") public ResponseEntity recognize(@RequestParam("file") MultipartFile file) { try { String result = ocrService.recognizeText(file); return ResponseEntity.ok(result); } catch (Exception e) { return ResponseEntity.status(500).body(e.getMessage()); } } }五、图像预处理增强识别率
1. 灰度处理
BufferedImage grayImage = new BufferedImage( image.getWidth(), image.getHeight(), BufferedImage.TYPE_BYTE_GRAY ); Graphics g = grayImage.getGraphics(); g.drawImage(image, 0, 0, null); g.dispose();2. 二值化处理
BufferedImage binaryImage = new BufferedImage( image.getWidth(), image.getHeight(), BufferedImage.TYPE_BYTE_BINARY ); Graphics2D g2d = binaryImage.createGraphics(); g2d.drawImage(image, 0, 0, null); g2d.dispose();3. 分辨率调整
Image scaledImage = image.getScaledInstance( image.getWidth()*2, image.getHeight()*2, Image.SCALE_SMOOTH );六、接口测试
1. 使用Postman测试
-
请求方式:POST
-
URL:http://localhost:8080/ocr/recognize
-
Body选择form-data:
-
Key:file,类型File
-
Value:选择测试图片
2. 测试结果示例
Spring Boot 整合 Tesseract-OCR 实现 图像文字识别功能,准确率可达90%!
七、常见问题解决
1. 报错:Error opening data file...
-
检查tessdata目录路径是否正确
-
确认语言包文件存在
2. 中文识别乱码
-
确保下载了中文语言包
-
设置正确的编码格式:
tesseract.setTessVariable("user_defined_dpi", "300"); tesseract.setTessVariable("preserve_interword_spaces", "1");3. 识别速度慢
-
缩小图片尺寸
-
使用ROI(Region of Interest)局部识别
-
启用多线程处理
八、性能优化建议
-
图片预处理:灰度化、二值化、降噪
-
区域识别:指定识别区域坐标
-
多线程池:异步处理识别请求
-
缓存机制:缓存常用识别结果
-
GPU加速:使用Tesseract的GPU版本
九、扩展应用场景
-
文档数字化:扫描件转电子文档
-
车牌识别:结合OpenCV使用
-
发票识别:定制化模板解析
-
验证码破解:简单验证码识别
-
古籍数字化:特殊字体训练
-
-
-
-
-
-
-
-
-







