
【前端】【React】React性能优化系统总结

第一章 React性能优化基础认知
1.1 React性能问题的来源
1.1.1 不必要的渲染
在 React 应用中,不必要的渲染是性能问题的常见来源之一😫。当组件的状态(state)或属性(props)发生变化时,React 会默认重新渲染该组件及其子组件。但有时候,这些变化并不需要重新渲染组件,然而 React 却执行了渲染操作,这就造成了性能的浪费。
比如,父组件的某个状态更新了,但子组件并不依赖这个状态,可子组件还是会跟着重新渲染。这种不必要的渲染会增加 CPU 的计算负担,导致应用响应变慢。就好像你明明不需要打扫客厅,却还是花费时间和精力去打扫了一遍🧹。
1.1.2 组件渲染的高复杂度
组件渲染的高复杂度也会引发性能问题🤯。如果一个组件的渲染逻辑非常复杂,包含大量的计算、嵌套循环或者深度嵌套的 JSX 结构,那么每次渲染这个组件都会消耗大量的时间和资源。
例如,在组件的 render 方法中进行大量的数学计算,或者在 JSX 中嵌套了多层的组件,这些都会让渲染过程变得缓慢。这就好比你要在一个堆满杂物的房间里找东西,东西越多,找起来就越费劲🔍。
1.1.3 事件处理的低效
事件处理的低效同样会影响 React 应用的性能😒。当事件处理函数的执行时间过长,或者事件处理函数被频繁调用时,就会导致应用的响应速度变慢。
比如,在事件处理函数中进行大量的网络请求或者复杂的计算,会阻塞主线程,使得页面无法及时响应用户的操作。这就好像你在接电话的时候,一直在处理其他事情,导致电话那头的人等了很久都没有得到回应📞。
1.2 性能指标和衡量方法
1.2.1 FPS(帧率)
FPS(Frames Per Second)即帧率,是衡量 React 应用性能的重要指标之一🎯。它表示每秒显示的帧数,帧率越高,画面就越流畅;帧率越低,画面就会出现卡顿现象。
在浏览器中,理想的帧率是 60 FPS,也就是每帧的渲染时间不超过 16.67 毫秒(1000 毫秒 / 60)。如果帧率低于 60 FPS,用户就可能会感觉到页面的卡顿。我们可以使用浏览器的开发者工具来查看页面的帧率,通过观察帧率的变化,我们可以判断应用的性能是否良好。就好像我们通过观察汽车的速度表来判断汽车的行驶状态一样🚗。
1.2.2 渲染时间
渲染时间也是一个重要的性能指标⏱️。它指的是从组件开始渲染到渲染完成所花费的时间。渲染时间越短,说明组件的渲染效率越高;渲染时间越长,说明组件的渲染效率越低。
我们可以使用 performance.now() 方法来测量组件的渲染时间。在组件开始渲染前记录一个时间戳,在组件渲染完成后再记录一个时间戳,两个时间戳的差值就是组件的渲染时间。通过分析不同组件的渲染时间,我们可以找出渲染效率较低的组件,进而进行优化。这就好像我们通过测量运动员跑 100 米的时间来评估他们的跑步速度一样🏃♂️。
1.2.3 React DevTools性能分析
React DevTools 是 React 官方提供的一款浏览器扩展工具,它可以帮助我们对 React 应用进行性能分析🧐。通过 React DevTools 的性能分析功能,我们可以直观地看到组件的渲染情况,包括哪些组件被渲染了、渲染的次数以及每次渲染所花费的时间。
我们可以在 Chrome 或 Firefox 浏览器中安装 React DevTools 扩展,然后在浏览器的开发者工具中打开 React DevTools。在性能分析面板中,我们可以录制一段时间内的组件渲染情况,然后查看详细的分析报告。根据报告中的数据,我们可以找出性能瓶颈所在,从而有针对性地进行优化。这就好像我们使用医生的检查设备来找出身体的健康问题一样💊。
第二章 代码层面的优化
2.1 减少渲染次数
2.1.1 使用 shouldComponentUpdate 生命周期方法
在 React 组件的生命周期里,shouldComponentUpdate 是一个相当重要的方法😎。当组件接收到新的 props 或者 state 时,React 默认会重新渲染组件。但有时候,我们并不希望组件在某些情况下进行不必要的渲染,这时 shouldComponentUpdate 就派上用场啦。
shouldComponentUpdate 是一个返回布尔值的函数,它接收两个参数:nextProps 和 nextState,分别代表即将更新的 props 和 state。如果这个函数返回 true,组件就会进行重新渲染;如果返回 false,组件就不会重新渲染。
下面是一个简单的示例:
class MyComponent extends React.Component {
shouldComponentUpdate(nextProps, nextState) {
// 这里可以根据具体情况判断是否需要重新渲染
if (this.props.someProp === nextProps.someProp && this.state.someState === nextState.someState) {
return false; // 不需要重新渲染
}
return true; // 需要重新渲染
}
render() {
return {this.props.someProp};
}
}
通过这种方式,我们可以手动控制组件的渲染,避免不必要的性能开销👏。
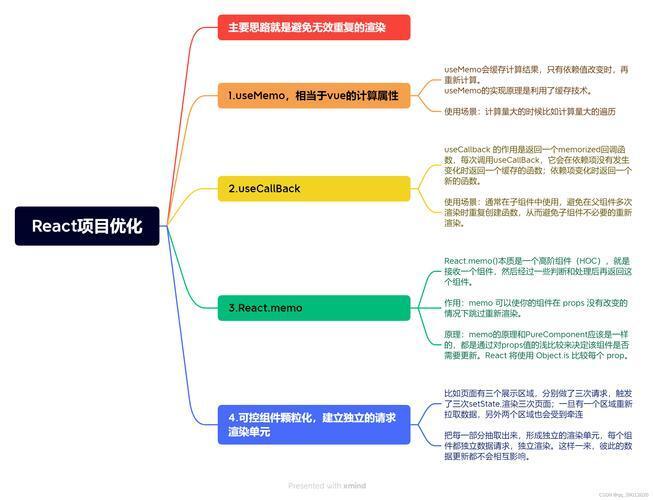
2.1.2 React.PureComponent 的使用
React.PureComponent 是 React 提供的一个特殊的组件类,它是 React.Component 的子类🤓。与普通的 Component 不同,PureComponent 会自动对 props 和 state 进行浅比较。如果 props 和 state 没有发生变化,它就不会重新渲染组件。

下面是一个使用 React.PureComponent 的示例:
import React from 'react';
class MyPureComponent extends React.PureComponent {
render() {
return {this.props.someProp};
}
}
使用 React.PureComponent 可以让我们更方便地减少组件的渲染次数,提高性能。但需要注意的是,它进行的是浅比较,如果 props 或 state 是复杂对象,可能会出现一些意外情况😜。
2.1.3 React.memo 的使用
React.memo 是一个高阶组件,它用于函数式组件,类似于 React.PureComponent 对类组件的作用🧐。React.memo 会对组件的 props 进行浅比较,如果 props 没有变化,就会复用之前的渲染结果,避免重新渲染。
下面是一个使用 React.memo 的示例:
import React from 'react';
const MyFunctionalComponent = (props) => {
return {props.someProp};
};
const MemoizedComponent = React.memo(MyFunctionalComponent);
通过使用 React.memo,我们可以在函数式组件中也实现减少渲染次数的效果👍。
2.2 优化渲染逻辑
2.2.1 拆分大型组件
在开发过程中,我们可能会遇到一些非常大的组件,这些组件包含了大量的代码和逻辑,这会让代码变得难以维护和理解,同时也可能会影响性能😫。因此,我们可以将大型组件拆分成多个小的组件。
拆分大型组件有很多好处:
- 提高代码的可维护性:每个小的组件功能单一,代码量少,更容易理解和修改。
- 提高代码的复用性:小的组件可以在不同的地方复用。
- 提高性能:可以根据需要单独渲染小的组件,避免不必要的渲染。
例如,一个包含头部、内容和底部的页面组件,可以拆分成 Header、Content 和 Footer 三个小的组件:
import React from 'react'; const Header = () => { return 这是头部; }; const Content = () => { return 这是内容; }; const Footer = () => { return 这是底部; }; const Page = () => { return ( ); };2.2.2 懒加载组件
在一些大型应用中,可能会有很多组件,但并不是所有的组件在一开始都需要加载。这时,我们可以使用懒加载的方式,只有在需要的时候才加载组件,这样可以提高应用的初始加载速度🚀。
在 React 中,可以使用 React.lazy 和 Suspense 来实现组件的懒加载。React.lazy 用于动态导入组件,Suspense 用于在组件加载过程中显示一个加载提示。
下面是一个简单的示例:
import React, { lazy, Suspense } from 'react'; // 懒加载组件 const LazyComponent = lazy(() => import('./LazyComponent')); const App = () => { return ( ); };在这个示例中,LazyComponent 会在需要的时候才被加载,在加载过程中会显示“加载中…”的提示。
2.2.3 避免在渲染方法中进行复杂计算
在 React 组件的 render 方法中,应该尽量避免进行复杂的计算。因为 render 方法会在组件每次渲染时都被调用,如果在 render 方法中进行复杂计算,会导致性能下降😣。
我们可以将复杂的计算提前进行,或者使用 useMemo 钩子来缓存计算结果。
下面是一个使用 useMemo 的示例:
import React, { useMemo } from 'react'; const MyComponent = (props) => { const { numbers } = props; // 使用 useMemo 缓存计算结果 const sum = useMemo(() => { return numbers.reduce((acc, num) => acc + num, 0); }, [numbers]); return 总和: {sum}; };在这个示例中,sum 的计算结果会被缓存,只有当 numbers 发生变化时才会重新计算,避免了不必要的计算开销👏。
2.3 事件处理优化
2.3.1 事件绑定的优化
在 React 中,事件绑定是一个常见的操作。但如果不正确地进行事件绑定,可能会导致性能问题。例如,在 render 方法中每次都创建一个新的事件处理函数,会导致组件每次渲染时都创建新的函数实例,增加内存开销。
我们可以使用以下几种方式来优化事件绑定:
- 在构造函数中绑定事件处理函数:在类组件的构造函数中使用 this.handleClick = this.handleClick.bind(this) 来绑定事件处理函数,这样可以避免在 render 方法中重复创建函数实例。
- 使用箭头函数作为类的属性:在类组件中,可以将事件处理函数定义为箭头函数,这样函数会自动绑定 this。
- 在函数式组件中使用 useCallback 钩子:useCallback 可以缓存事件处理函数,避免每次渲染时都创建新的函数实例。
下面是一个使用 useCallback 的示例:
import React, { useCallback } from 'react'; const MyFunctionalComponent = () => { const handleClick = useCallback(() => { console.log('点击事件触发'); }, []); return 点击我; };2.3.2 节流和防抖的应用
在处理一些高频事件(如滚动、输入框输入等)时,可能会导致性能问题。这时,我们可以使用节流和防抖的技术来优化事件处理。
- 节流(Throttle):节流是指在一定时间内,只执行一次函数。例如,在滚动事件中,我们可以设置每隔 200 毫秒执行一次滚动处理函数,避免频繁执行导致性能下降。
- 防抖(Debounce):防抖是指在一定时间内,只有最后一次调用函数才会被执行。例如,在输入框输入事件中,我们可以设置在用户停止输入 300 毫秒后才执行搜索操作,避免不必要的请求。
在 React 中,可以使用第三方库(如 lodash)来实现节流和防抖。
下面是一个使用 lodash 实现防抖的示例:
import React, { useRef } from 'react'; import debounce from 'lodash/debounce'; const SearchInput = () => { const inputRef = useRef(null); const handleInputChange = debounce((event) => { console.log('输入内容:', event.target.value); }, 300); return ( ); };通过节流和防抖的应用,可以有效地优化高频事件的处理,提高性能👏。
第三章 状态管理优化
3.1 合理使用状态
3.1.1 局部状态和全局状态的区分
在应用开发中,状态就像是应用的“数据心脏”,它存储着应用运行时的数据。而状态又分为局部状态和全局状态,我们需要清晰地对它们进行区分。
- 局部状态:
- 局部状态通常是组件内部使用的状态,它只与当前组件相关,不涉及其他组件的交互。比如一个表单组件中的输入框值,这个值只在该表单组件内部有意义,它就是局部状态。
- 局部状态的好处是管理简单,组件可以独立维护自己的状态,不会对其他组件产生影响。就像一个独立的小王国,自给自足😎。
- 在 React 中,我们可以使用 useState 钩子来创建局部状态,例如:
import React, { useState } from 'react'; const FormComponent = () => { const [inputValue, setInputValue] = useState(''); return ( setInputValue(e.target.value)} /> ); }; export default FormComponent;- 全局状态:
- 全局状态是应用中多个组件都需要共享的状态。比如用户的登录状态、主题设置等,这些状态在多个页面和组件中都可能会用到。
- 全局状态的管理相对复杂,因为多个组件可能会对其进行读写操作。但它可以让不同组件之间的数据保持同步,提高应用的一致性。就像一个国家的中央政府,管理着全国的重要信息📋。
- 在 React 中,我们可以使用 Redux、MobX 等状态管理库来管理全局状态。
3.1.2 避免不必要的状态更新
状态更新是一件需要谨慎对待的事情,不必要的状态更新会导致组件的重新渲染,从而影响应用的性能。以下是一些避免不必要状态更新的方法:
- 使用 shouldComponentUpdate 或 React.memo:
- 在类组件中,我们可以使用 shouldComponentUpdate 生命周期方法来控制组件是否需要重新渲染。例如:
class MyComponent extends React.Component { shouldComponentUpdate(nextProps, nextState) { // 只有当某些特定属性或状态发生变化时才重新渲染 return this.props.someProp!== nextProps.someProp; } render() { return {this.props.someProp}; } }- 在函数组件中,我们可以使用 `React.memo` 来实现类似的功能。例如:
const MyComponent = React.memo((props) => { return {props.someProp}; });- 避免在 render 方法中创建新的对象或函数:
- 在 render 方法中创建新的对象或函数会导致每次渲染时这些对象或函数的引用发生变化,从而触发不必要的重新渲染。我们可以将这些对象或函数的创建移到组件外部。例如:
// 错误示例 const MyComponent = (props) => { const handleClick = () => { // 处理点击事件 }; return Click me; }; // 正确示例 const handleClick = () => { // 处理点击事件 }; const MyComponent = (props) => { return Click me; };3.2 状态管理库的优化
3.2.1 Redux的性能优化
3.2.1.1 减少action的触发
在 Redux 中,action 是触发状态更新的唯一方式。过多的 action 触发会导致不必要的状态更新和性能损耗。我们可以通过以下方法减少 action 的触发:
- 合并 action:将多个相关的状态更新合并到一个 action 中。例如,当用户同时更新用户名和头像时,我们可以创建一个 UPDATE_USER_INFO action 来同时更新这两个状态,而不是分别触发 UPDATE_USERNAME 和 UPDATE_AVATAR 两个 action。
- 条件触发 action:在触发 action 之前,先检查是否真的需要更新状态。例如:
const mapDispatchToProps = (dispatch) => { return { updateUserInfo: (newInfo) => { // 检查新信息是否与旧信息不同 if (newInfo!== currentUserInfo) { dispatch({ type: 'UPDATE_USER_INFO', payload: newInfo }); } } }; };3.2.1.2 优化reducer的逻辑
reducer 是 Redux 中处理 action 并返回新状态的函数。优化 reducer 的逻辑可以提高状态更新的效率。以下是一些优化方法:
- 减少嵌套层级:尽量避免在 reducer 中使用过多的嵌套条件判断,这样可以提高代码的可读性和执行效率。
- 使用纯函数:reducer 必须是纯函数,即相同的输入总是返回相同的输出,并且不修改原始状态。例如:
const initialState = { user: { name: '', age: 0 } }; const userReducer = (state = initialState, action) => { switch (action.type) { case 'UPDATE_USER_NAME': return { ...state, user: { ...state.user, name: action.payload } }; default: return state; } };3.2.1.3 使用Reselect进行缓存计算
Reselect 是一个用于创建记忆化(缓存)selector 的库,它可以避免在每次状态更新时都进行重复的计算。例如:
import { createSelector } from'reselect'; const getUsers = (state) => state.users; const getSearchTerm = (state) => state.searchTerm; const getFilteredUsers = createSelector( [getUsers, getSearchTerm], (users, searchTerm) => { return users.filter(user => user.name.includes(searchTerm)); } );在这个例子中,getFilteredUsers 是一个记忆化的 selector,只有当 users 或 searchTerm 发生变化时,才会重新进行过滤计算。
3.2.2 MobX的性能优化
3.2.2.2 精确的响应式跟踪
MobX 的核心是响应式编程,它可以自动跟踪状态的变化并更新相关的组件。为了提高性能,我们需要确保 MobX 只跟踪必要的状态变化。
- 使用 makeObservable 明确指定可观察状态和动作:在定义 MobX 状态时,使用 makeObservable 来明确指定哪些状态是可观察的,哪些方法是动作。例如:
import { makeObservable, observable, action } from'mobx'; class UserStore { constructor() { makeObservable(this, { name: observable, age: observable, updateName: action }); } name = ''; age = 0; updateName(newName) { this.name = newName; } }- 使用 autorun 和 reaction 精确控制副作用:autorun 和 reaction 是 MobX 中用于处理副作用的函数,我们可以使用它们来精确控制哪些状态变化会触发副作用。例如:
import { autorun } from'mobx'; const userStore = new UserStore(); autorun(() => { // 只有当 userStore.name 发生变化时才会执行 console.log(`User name is now: ${userStore.name}`); });3.2.2.2 批量更新状态
在 MobX 中,频繁的状态更新会导致组件的多次重新渲染,影响性能。我们可以使用 transaction 或 runInAction 来批量更新状态,减少重新渲染的次数。例如:
import { runInAction } from'mobx'; const userStore = new UserStore(); runInAction(() => { userStore.name = 'John'; userStore.age = 30; });在这个例子中,runInAction 会将 name 和 age 的更新合并为一次操作,从而减少组件的重新渲染次数。
第四章 虚拟DOM和Diff算法优化
4.1 理解虚拟DOM和Diff算法
4.1.1 虚拟DOM的原理
1. 什么是虚拟DOM
虚拟DOM(Virtual DOM)是一种轻量级的 JavaScript 对象,它是真实 DOM 的抽象表示😃。想象一下,真实的 DOM 就像是一座庞大而复杂的城堡,操作它的成本很高;而虚拟 DOM 则像是这座城堡的模型,我们可以在模型上随意进行修改,成本要低得多。
2. 工作流程
- 创建虚拟DOM:当我们编写一个前端应用时,框架会根据我们的代码(如 React 中的 JSX 或 Vue 中的模板)创建对应的虚拟 DOM 树🌳。例如,在 React 中:
const element =
Hello, World!
;这里的 element 就是一个虚拟 DOM 节点。
-
状态变更:当应用的状态发生变化时(比如用户点击按钮,数据更新等),框架会重新创建一个新的虚拟 DOM 树。
-
对比差异:将新的虚拟 DOM 树和旧的虚拟 DOM 树进行对比,找出它们之间的差异。这个过程就像是对比两个城堡模型,看看哪些地方不一样🧐。
-
更新真实DOM:根据对比的差异,只对真实 DOM 中需要更新的部分进行更新,而不是重新渲染整个 DOM 树。这样可以大大提高性能。
4.1.2 Diff算法的工作机制
1. 什么是Diff算法
Diff 算法是一种用于比较两个虚拟 DOM 树差异的算法。它的目的是找出两个树之间最小的更新操作,从而尽可能减少对真实 DOM 的操作。
2. 核心策略
- 同层比较:Diff 算法只会对同一层级的节点进行比较,不会跨层级比较。例如,有两个虚拟 DOM 树,它只会比较同一层的节点是否相同,而不会去比较不同层的节点。就像我们比较两个城堡模型,只会比较同一层楼的房间是否一样🏠。
- 节点类型比较:如果两个节点的类型不同(比如一个是 节点,一个是
节点),则直接替换整个节点。
- 列表比较:当处理列表时,Diff 算法会根据节点的 key 值来判断节点是否相同。如果没有 key 值,它会按照顺序进行比较,这样可能会导致不必要的 DOM 操作。
3. 示例
假设有以下两个虚拟 DOM 树:
// 旧的虚拟 DOM 树 const oldTree = (Old Text
); // 新的虚拟 DOM 树 const newTree = (New Text
);Diff 算法会发现
节点和
节点类型不同,然后直接将
节点替换为
节点。
4.2 优化Diff算法的性能
4.2.1 提供唯一的key值
1. 为什么需要key值
在处理列表时,如果没有提供 key 值,Diff 算法会按照顺序比较节点。当列表中的元素顺序发生变化时,会导致不必要的 DOM 操作。而提供唯一的 key 值可以帮助 Diff 算法准确地识别每个节点,从而提高性能。
2. 示例
// 没有 key 值的列表 const listWithoutKey = [1, 2, 3].map((item) =>
- {item} ); // 有 key 值的列表 const listWithKey = [1, 2, 3].map((item) =>
- {item} );
- 节点都有一个唯一的 key 值,这样当列表顺序发生变化时,Diff 算法可以更准确地处理。
4.2.2 减少DOM结构的深度和复杂度
1. 为什么要减少深度和复杂度
DOM 结构的深度和复杂度会影响 Diff 算法的性能。如果 DOM 树很深或者很复杂,Diff 算法在比较时需要遍历更多的节点,从而增加了计算量。
2. 优化方法
- 扁平化结构:尽量避免创建过深的 DOM 树。例如,将嵌套过多的 标签简化。
Content
Content
- 减少不必要的节点:移除那些没有实际作用的节点,只保留必要的节点。这样可以让 Diff 算法更快地完成比较,提高性能🚀。
第五章 网络请求优化
在当今数字化的时代,网络请求的效率直接影响着应用程序的性能和用户体验。本章将详细介绍如何优化网络请求,让你的应用程序在网络通信中更加高效。
5.1 减少不必要的请求
5.1.1 数据缓存
数据缓存就像是一个“魔法仓库”🧰,它可以把我们之前请求过的数据存储起来,当再次需要这些数据时,就不用重新向服务器发送请求啦,直接从这个“仓库”里拿就行,这样能大大节省时间和网络资源。
-
客户端缓存:
- 浏览器缓存:现代浏览器都有强大的缓存机制。例如,当我们访问一个网页时,浏览器会把网页中的图片、CSS 文件、JavaScript 文件等静态资源缓存下来。下次再访问这个网页时,如果这些资源没有更新,浏览器就会直接从本地缓存中加载,而不是重新从服务器下载。可以通过设置 HTTP 头信息(如 Cache-Control、Expires 等)来控制浏览器的缓存策略。
- 应用程序缓存:在开发应用程序时,我们也可以自己实现缓存逻辑。比如,在 JavaScript 中,可以使用 localStorage 或 sessionStorage 来存储一些临时数据。localStorage 可以长期存储数据,除非手动删除;而 sessionStorage 则在会话结束时自动清除数据。
-
服务器端缓存:
- 数据库缓存:数据库也可以设置缓存,例如 MySQL 中的查询缓存。当执行相同的查询语句时,数据库可以直接从缓存中返回结果,而不需要重新执行查询操作,提高了查询效率。
- 应用服务器缓存:像 Redis 这样的内存数据库,常被用作应用服务器的缓存。它可以快速地存储和读取数据,减少对数据库的访问压力。例如,在一个电商应用中,可以把热门商品的信息缓存到 Redis 中,当用户访问商品列表时,直接从 Redis 中获取数据,而不是每次都查询数据库。
5.1.2 合并请求
想象一下,你要去超市买东西🛒,如果一次只买一件商品,那你得跑很多趟,既浪费时间又消耗体力。合并请求就相当于把你要买的东西列个清单,一次性去超市把所有东西都买回来,这样可以减少往返的次数。
- 文件合并:在网页开发中,通常会有多个 CSS 文件和 JavaScript 文件。可以把这些文件合并成一个文件,这样浏览器只需要发送一个请求来加载所有的样式和脚本,而不是分别发送多个请求。例如,使用工具(如 Grunt、Gulp 等)可以很方便地实现文件合并。
- 数据合并:在向服务器请求数据时,如果有多个相关的数据请求,可以把它们合并成一个请求。比如,在一个社交应用中,用户进入个人主页时,可能需要同时获取用户的基本信息、好友列表和最新动态。可以通过设计合理的 API,让服务器一次性返回这些数据,而不是分别发送三个请求。
5.2 优化请求性能
5.2.2 选择合适的请求库
请求库就像是我们在网络请求中的“交通工具”🚗,不同的请求库有不同的特点和适用场景,选择合适的“交通工具”可以让我们的网络请求更加高效。
- 原生 XMLHttpRequest:这是最基础的网络请求方式,就像是一辆“老爷车”🚙,虽然功能比较原始,但它是所有其他请求库的基础。在一些简单的场景下,或者需要对请求进行精细控制时,可以使用它。例如,在处理一些特殊的 HTTP 头信息时,原生 XMLHttpRequest 可以提供更多的灵活性。
- fetch API:fetch 是现代浏览器提供的一种新的网络请求方式,它就像是一辆“经济型轿车”🚘,使用起来比较简洁,语法更加现代化。fetch 返回一个 Promise 对象,可以方便地进行异步操作。例如:
fetch('https://api.example.com/data') .then(response => response.json()) .then(data => console.log(data)) .catch(error => console.error('Error:', error));- Axios:Axios 是一个基于 Promise 的 HTTP 客户端,它就像是一辆“豪华轿车”🚎,功能强大且使用方便。Axios 支持拦截器、取消请求、自动转换 JSON 数据等功能,在开发大型项目时非常实用。例如:
axios.get('https://api.example.com/data') .then(response => console.log(response.data)) .catch(error => console.error('Error:', error));5.2.2 压缩和优化请求数据
压缩和优化请求数据就像是给行李“瘦身”🧳,让它在运输过程中更加轻松。通过减少数据的大小,可以加快数据的传输速度,降低网络延迟。
- 数据压缩:在服务器端,可以对返回的数据进行压缩。常见的压缩算法有 Gzip 和 Brotli。例如,在 Node.js 中,可以使用 zlib 模块来实现 Gzip 压缩:
const http = require('http'); const zlib = require('zlib'); http.createServer((req, res) => { const data = 'This is some sample data to be compressed.'; zlib.gzip(data, (err, buffer) => { if (err) { res.statusCode = 500; res.end(); } else { res.setHeader('Content-Encoding', 'gzip'); res.end(buffer); } }); }).listen(3000);- 数据优化:在设计数据结构时,要尽量减少不必要的数据传输。例如,在返回用户信息时,只返回客户端需要的字段,而不是返回所有的用户信息。另外,可以使用更简洁的数据格式,如 JSON 比 XML 更加轻量级。
通过以上这些方法,可以有效地优化网络请求,提高应用程序的性能和用户体验😃。
第六章 构建和部署优化
在软件开发过程中,构建和部署是非常重要的环节,优化这两个环节可以显著提升应用的性能和用户体验。下面我们就来详细了解构建和部署优化的相关内容。
6.1 代码分割和打包优化
6.1.1 使用Webpack进行代码分割
Webpack是一个强大的模块打包工具,代码分割是它的一个重要特性,通过代码分割可以将代码拆分成多个较小的文件,从而实现按需加载,减少初始加载时间。以下是使用Webpack进行代码分割的几种常见方式:
1. 入口起点分割
可以通过配置多个入口起点来分割代码。例如在webpack.config.js中:
const path = require('path'); module.exports = { entry: { main: './src/main.js', vendor: './src/vendor.js' }, output: { filename: '[name].bundle.js', path: path.resolve(__dirname, 'dist') } };这样Webpack会分别打包main.js和vendor.js,生成两个不同的打包文件main.bundle.js和vendor.bundle.js。这种方式适合将第三方库和自己的业务代码分开打包。
2. 动态导入
使用ES6的动态导入语法import()可以实现动态代码分割。例如在业务代码中:
button.addEventListener('click', async () => { const { func } = await import('./module.js'); func(); });当点击按钮时,才会动态加载module.js文件,这样可以避免在初始加载时加载不必要的代码。
3. SplitChunksPlugin
Webpack内置的SplitChunksPlugin可以帮助我们更智能地分割代码。在webpack.config.js中可以这样配置:
module.exports = { // ...其他配置 optimization: { splitChunks: { chunks: 'all' } } };SplitChunksPlugin会自动将公共模块和第三方库提取出来,生成单独的文件,提高代码的复用性和加载效率。
6.1.2 按需加载模块
按需加载模块是一种优化策略,它允许我们在需要的时候才加载特定的模块,而不是在应用启动时就加载所有模块。除了上面提到的动态导入,还有一些其他的按需加载方式。
1. 路由按需加载
在单页面应用(SPA)中,我们可以根据路由来按需加载页面组件。以Vue.js为例:
const routes = [ { path: '/home', component: () => import('./views/Home.vue') }, { path: '/about', component: () => import('./views/About.vue') } ];当用户访问/home或/about路由时,才会加载对应的组件,这样可以减少初始加载的代码量。
2. 懒加载组件
在一些大型项目中,有些组件可能不是在页面一开始就需要显示的,这时可以使用懒加载组件。例如在React中:
const LazyComponent = React.lazy(() => import('./LazyComponent')); function App() { return (); }当需要渲染LazyComponent时,才会去加载该组件,fallback属性用于在加载过程中显示加载提示。
6.2 生产环境优化
6.2.1 去除开发环境代码
在开发过程中,我们可能会添加一些用于调试和开发的代码,这些代码在生产环境中是不需要的,应该将其去除。可以通过环境变量来实现。
1. 使用process.env.NODE_ENV
在代码中可以根据process.env.NODE_ENV的值来判断当前环境。例如:
if (process.env.NODE_ENV === 'development') { console.log('This is a development log'); }在生产环境中,这段代码不会执行。在Webpack中可以通过DefinePlugin来定义环境变量:
const webpack = require('webpack'); module.exports = { // ...其他配置 plugins: [ new webpack.DefinePlugin({ 'process.env.NODE_ENV': JSON.stringify('production') }) ] };6.2.2 开启代码压缩和混淆
代码压缩和混淆可以减少代码的体积,提高加载速度,同时也可以增加代码的安全性。
1. 使用TerserPlugin
Webpack内置的TerserPlugin可以用于代码压缩和混淆。在webpack.config.js中配置如下:
const TerserPlugin = require('terser-webpack-plugin'); module.exports = { // ...其他配置 optimization: { minimizer: [ new TerserPlugin({ terserOptions: { compress: { drop_console: true // 去除console语句 } } }) ] } };TerserPlugin会对代码进行压缩和混淆,去除不必要的空格、注释等,同时还可以去除console语句。
6.2.3 使用CDN加速静态资源
CDN(内容分发网络)可以将静态资源分发到离用户最近的节点,从而提高资源的加载速度。
1. 配置CDN链接
在HTML文件中,将静态资源的链接替换为CDN链接。例如使用Bootstrap的CDN:
Document这样用户在访问页面时,会从离自己最近的CDN节点加载Bootstrap的CSS和JS文件,提高加载速度。
🎉 通过以上这些构建和部署优化的方法,可以显著提升应用的性能和用户体验,让你的应用更加出色!
第七章 性能优化案例分析
7.1 小型项目的性能优化
7.1.1 具体问题分析
在小型项目中,我们可能会遇到各种各样影响性能的问题,下面为你详细列举一些常见问题:
- 代码层面
- 冗余代码:在项目开发过程中,可能由于开发人员的疏忽或者代码复用不合理,导致代码中存在大量重复的部分。比如在多个函数中使用了相同的逻辑代码,却没有进行封装,这会增加代码的体积,降低执行效率。
- 低效算法:使用了复杂度较高的算法来解决问题。例如,在需要查找某个元素时,使用了时间复杂度为 O ( n ) O(n) O(n) 的线性查找算法,而实际上可以使用时间复杂度为 O ( l o g n ) O(log n) O(logn) 的二分查找算法(前提是数据有序),这会大大影响程序的执行速度。
- 资源加载方面
- 图片资源过大:项目中使用的图片没有经过合理压缩,导致页面加载时需要花费大量时间来下载图片。比如一张简单的图标图片,可能原本只需要几十 KB,但由于没有进行优化,达到了几百 KB 甚至更大。
- CSS 和 JavaScript 文件过多:将不同功能的代码分散在多个小文件中,会增加浏览器的请求次数。每个请求都需要建立连接、传输数据等,过多的请求会导致页面加载缓慢。
7.1.2 优化策略实施
针对上述问题,我们可以采取以下优化策略:
- 代码优化
- 去除冗余代码:仔细审查代码,将重复的代码提取出来封装成函数或者类。例如,将多个函数中相同的验证逻辑封装成一个验证函数,在需要的地方调用这个函数即可。这样不仅减少了代码量,还提高了代码的可维护性。
- 优化算法:根据具体问题选择合适的算法。如果是对数据进行排序,可以根据数据的规模和特点选择合适的排序算法,如快速排序、归并排序等。
- 资源加载优化
- 图片压缩:使用专业的图片压缩工具,如 TinyPNG 等,对项目中的图片进行压缩。在保证图片质量的前提下,尽可能减小图片的体积。同时,根据不同的使用场景,选择合适的图片格式,如 JPEG 适合用于照片,PNG 适合用于图标和透明背景的图片。
- 合并文件:将多个 CSS 和 JavaScript 文件合并成一个文件。可以使用构建工具,如 Webpack 等,将多个文件打包成一个文件,减少浏览器的请求次数。
7.1.3 优化前后性能对比
为了直观地看到优化效果,我们可以通过一些性能指标来进行对比:
- 页面加载时间:使用浏览器的开发者工具,如 Chrome 的开发者工具中的 Performance 面板,记录优化前后页面的加载时间。优化前,由于存在冗余代码和过多的资源请求,页面加载时间可能较长,例如达到了 5 秒甚至更长。经过优化后,去除了冗余代码,合并了文件,图片也进行了压缩,页面加载时间可能会缩短到 2 秒左右。
- 内存占用:使用浏览器的开发者工具中的 Memory 面板,观察优化前后页面的内存占用情况。优化前,由于代码的低效和资源的不合理使用,内存占用可能较高,例如达到了 200MB。优化后,内存占用可能会降低到 100MB 左右。
通过这些对比,我们可以清晰地看到性能优化带来的显著效果😃。
7.2 大型项目的性能优化
7.2.1 架构层面的优化
在大型项目中,架构层面的优化至关重要,它可以从整体上提升项目的性能:
- 分层架构设计
- 将项目划分为不同的层次,如表现层、业务逻辑层、数据访问层等。每个层次负责不同的功能,职责明确。这样可以提高代码的可维护性和可扩展性,同时也便于进行性能优化。例如,在数据访问层可以对数据库访问进行优化,减少数据库的查询次数。
- 分布式架构
- 对于一些高并发的大型项目,可以采用分布式架构。将项目拆分成多个服务,分别部署在不同的服务器上,通过网络进行通信。这样可以提高系统的并发处理能力,减轻单个服务器的压力。例如,电商平台的商品服务、订单服务、用户服务等可以分别部署在不同的服务器上。
7.2.2 多团队协作的性能优化
大型项目通常由多个团队共同开发,多团队协作的性能优化也非常重要:
- 统一规范
- 制定统一的代码规范、接口规范和性能指标规范。各个团队按照统一的规范进行开发,这样可以避免因为代码风格不一致、接口不兼容等问题导致的性能问题。例如,统一规定代码的命名规范、注释规范等。
- 沟通与协调
- 建立有效的沟通机制,各个团队之间及时沟通项目进展和遇到的问题。在涉及到跨团队的功能开发时,提前进行协调,确保各个部分的性能都能得到保证。例如,前端团队和后端团队在开发接口时,要明确接口的性能要求和数据格式。
7.2.3 长期性能监控和维护
大型项目的性能优化是一个长期的过程,需要进行持续的监控和维护:
- 性能监控工具
- 使用专业的性能监控工具,如 New Relic、Prometheus 等,对项目的性能进行实时监控。这些工具可以监控服务器的性能指标,如 CPU 使用率、内存使用率、网络带宽等,以及应用程序的性能指标,如响应时间、吞吐量等。
- 定期优化
- 根据性能监控的结果,定期对项目进行优化。随着项目的不断发展和用户量的增加,可能会出现新的性能问题,定期优化可以及时解决这些问题,保证项目的性能始终处于良好状态。例如,每季度对项目进行一次全面的性能评估和优化。
通过以上这些措施,可以有效地提升大型项目的性能,确保项目的稳定运行👍。
- 根据性能监控的结果,定期对项目进行优化。随着项目的不断发展和用户量的增加,可能会出现新的性能问题,定期优化可以及时解决这些问题,保证项目的性能始终处于良好状态。例如,每季度对项目进行一次全面的性能评估和优化。
- 性能监控工具
- 建立有效的沟通机制,各个团队之间及时沟通项目进展和遇到的问题。在涉及到跨团队的功能开发时,提前进行协调,确保各个部分的性能都能得到保证。例如,前端团队和后端团队在开发接口时,要明确接口的性能要求和数据格式。
- 统一规范
- 对于一些高并发的大型项目,可以采用分布式架构。将项目拆分成多个服务,分别部署在不同的服务器上,通过网络进行通信。这样可以提高系统的并发处理能力,减轻单个服务器的压力。例如,电商平台的商品服务、订单服务、用户服务等可以分别部署在不同的服务器上。
- 分层架构设计
- 代码优化
- 代码层面
- 数据优化:在设计数据结构时,要尽量减少不必要的数据传输。例如,在返回用户信息时,只返回客户端需要的字段,而不是返回所有的用户信息。另外,可以使用更简洁的数据格式,如 JSON 比 XML 更加轻量级。
- 数据压缩:在服务器端,可以对返回的数据进行压缩。常见的压缩算法有 Gzip 和 Brotli。例如,在 Node.js 中,可以使用 zlib 模块来实现 Gzip 压缩:
- Axios:Axios 是一个基于 Promise 的 HTTP 客户端,它就像是一辆“豪华轿车”🚎,功能强大且使用方便。Axios 支持拦截器、取消请求、自动转换 JSON 数据等功能,在开发大型项目时非常实用。例如:
-
- 减少不必要的节点:移除那些没有实际作用的节点,只保留必要的节点。这样可以让 Diff 算法更快地完成比较,提高性能🚀。
- 扁平化结构:尽量避免创建过深的 DOM 树。例如,将嵌套过多的 标签简化。
在上面的例子中,listWithKey 中的每个
-
- 创建虚拟DOM:当我们编写一个前端应用时,框架会根据我们的代码(如 React 中的 JSX 或 Vue 中的模板)创建对应的虚拟 DOM 树🌳。例如,在 React 中:
- 使用 autorun 和 reaction 精确控制副作用:autorun 和 reaction 是 MobX 中用于处理副作用的函数,我们可以使用它们来精确控制哪些状态变化会触发副作用。例如:
- 使用 makeObservable 明确指定可观察状态和动作:在定义 MobX 状态时,使用 makeObservable 来明确指定哪些状态是可观察的,哪些方法是动作。例如:
- 在 render 方法中创建新的对象或函数会导致每次渲染时这些对象或函数的引用发生变化,从而触发不必要的重新渲染。我们可以将这些对象或函数的创建移到组件外部。例如:
- 避免在 render 方法中创建新的对象或函数:
- 在类组件中,我们可以使用 shouldComponentUpdate 生命周期方法来控制组件是否需要重新渲染。例如:
- 使用 shouldComponentUpdate 或 React.memo:
- 全局状态:
- 局部状态:







