
利用Nginx+VLLM在本地部署多个大模型服务

背景
随着deepseek等开源大模型的爆火,本地化部署大模型服务变成了切实需求。基于vllm框架部署的本地大模型服务操作简单,部署后可以很方便地利用OpenAI compatible接口访问该服务。然而,vllm serve模式每次运行仅支持部署一个大模型,想运行多个大模型服务时,除了将多个服务运行在不同的端口上,是否可以利用一个公共的端口转发多个不同大模型服务的流量以节约端口占用?这点在容器内运行大模型服务时很有意义:多个服务占据容器内的多个端口,而容器以一个公共端口映射至宿主机,提供对所有大模型服务的访问,从而不占用宿主机过多的端口资源。很自然地想到, Nginx 的服务转发能力天然地适配这个需求。
思路
在容器中利用vllm serve命令将多个大模型运行在不同的容器端口上,同时在容器内部署Nginx服务,将容器映射到宿主机的唯一端口作为大模型服务的公共入口,在Nginx中配置该公共端口具备服务转发能力,这样,在IP、端口相同的情况下可以根据URI将访问流量转发至相应的大模型服务中去。
环境依赖
- 一个可以运行vllm服务的docker容器,如何安装vllm请参考官网教程。该容器要求有一个端口映射到宿主机,例如8000:8000,同时,在容器内提前安装好Nginx:
sudo apt install nginx
- 推荐使用 tmux 工具,方便在一个shell窗口中开启多个session,在不同的session中运行相应的大模型服务,可以随时进入指定session中查看服务运行情况,且方便终止服务。当然,也可以直接在shell中以后台的形式运行。
sudo apt install tmux
操作步骤(以同时部署Deepseek和Qwen大模型服务为例)
- 进入容器内,使用 tmux 开启多个session并在其中运行多个大模型服务
# 创建新session并进入 tmux new -s vllm_DeepSeek-R1-Distill-Qwen-14B #将Deepseek模型运行在0,1号两块GPU上,设置10K上下文,且设置服务端口为8001,并使能推理思维链 CUDA_VISIBLE_DEVICES=0,1 vllm serve your-path-to-deepseek/DeepSeek-R1-Distill-Qwen-14B --port 8001 --served-model-name DeepSeek-R1-Distill-Qwen-14B --dtype auto --api-key example-token_deepseek-r1-distill-qwen-14b --tensor-parallel-size 2 --max-model-len 10240 --enable-reasoning --reasoning-parser deepseek_r1 # 先按ctrl+b,松开后再按d退出当前session # 创建新session并进入 tmux new -s vllm_QwQ-32B-AWQ # 将Qwen模型运行在2号GPU上,设置10K上下文,且设置服务端口为8002 CUDA_VISIBLE_DEVICES=2 vllm serve your-path-to-qwen/Qwen2.5-14B-Instruct-AWQ --port 8002 --served-model-name Qwen2.5-14B-Instruct-AWQ --dtype auto --api-key token_example-qwen2.5-14b-instruct-awq --tensor-parallel-size 1 --max-model-len 10240 # 先按ctrl+b,松开后再按d退出当前session
- 新建大模型服务转发的Nginx配置,示例如下
# 新建配置文件 vim /etc/nginx/sites-available/vllm_proxy # 假设大模型服务公共端口号为8000,在vllm_proxy中键入 server { listen 8000; server_name vllm_forwarding; location /deepseek-r1-distill-qwen-14b { proxy_pass http://127.0.0.1:8001/v1; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } location /qwen2.5-14b-instruct-awq { proxy_pass http://127.0.0.1:8002/v1; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } # 将该配置软链接到Nginx使能配置目录 ln -s /etc/nginx/sites-available/vllm_proxy /etc/nginx/sites-enabled/vllm_proxy # 检测Nginx配置是否有误,正确则输出 # nginx: the configuration file /etc/nginx/nginx.conf syntax is ok # nginx: configuration file /etc/nginx/nginx.conf test is successful nginx -t # 重新载入nginx配置 service nginx reload service nginx restart service nginx status # 提示 nginx 服务正常运行即可- 现在就可以利用 http://host_ip:8000/deepseek-r1-distill-qwen-14b 或 http://host_ip:8000/qwen2.5-14b-instruct-awq 来分别访问本地容器部署的Deepseek和Qwen大模型服务了,可以使用OpenAI compatible python接口实验服务效果:
from openai import OpenAI qwen_client = OpenAI(base_url="http://localhost:8000/qwen2.5-14b-instruct-awq ", api_key="token_example-qwen2.5-14b-instruct-awq") qwen_completion = qwq_client.chat.completions.create(model="Qwen2.5-14B-Instruct-AWQ", messages=[{'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': '你是谁?'}]) print(qwen_completion.choices[0].message.content) # 回答:我是阿里云开发的一款超大规模语言模型,我叫通义千问。 (图片来源网络,侵删)
(图片来源网络,侵删)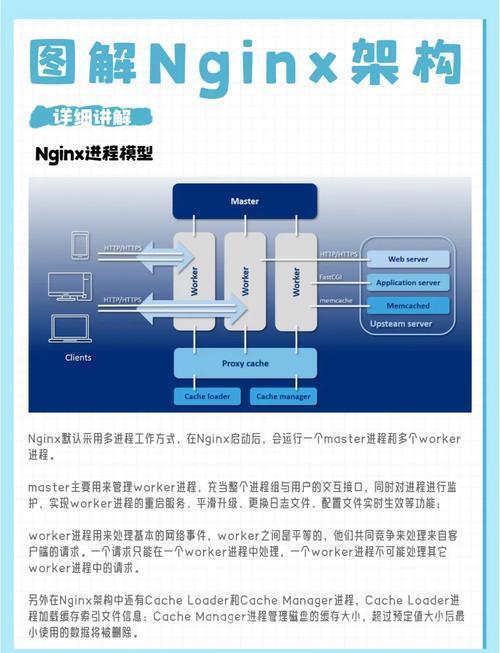 (图片来源网络,侵删)
(图片来源网络,侵删) (图片来源网络,侵删)
(图片来源网络,侵删)
- 推荐使用 tmux 工具,方便在一个shell窗口中开启多个session,在不同的session中运行相应的大模型服务,可以随时进入指定session中查看服务运行情况,且方便终止服务。当然,也可以直接在shell中以后台的形式运行。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







