
MySQL中count(1)和count(*)的区别及细节

一、核心结论
按照性能排序:count(*) = count(1) > count(主键字段) > count(字段)(无索引时)
关键原因:
- count(*) 和 count(1) 在 InnoDB 中执行逻辑几乎一致,性能无差异。
- count(字段) 效率最差,因可能触发全表扫描。
二、四种COUNT的简单说明
COUNT是聚合函数,统计满足条件且指定参数不为NULL的行数。
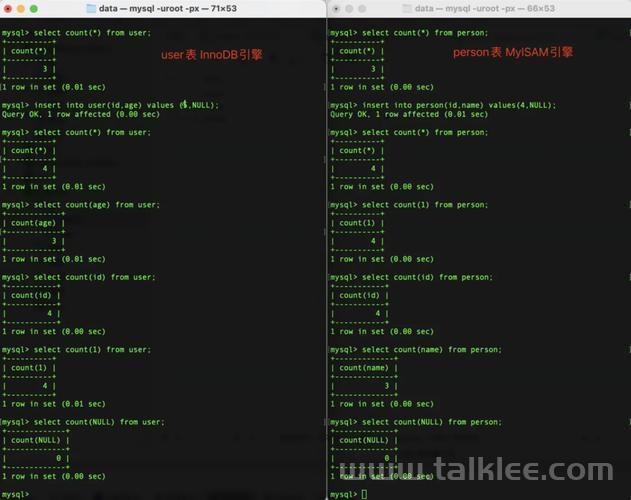
-- 创建测试表 CREATE TABLE user_info ( id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(50), email VARCHAR(100), age INT, status TINYINT, INDEX idx_email (email), INDEX idx_status (status) ); -- 插入测试数据 INSERT INTO user_info (username, email, age, status) VALUES ('alice', 'alice@test.com', 25, 1), ('bob', NULL, 30, 1), ('charlie', 'charlie@test.com', NULL, 0), ('david', 'david@test.com', 28, NULL), ('eve', NULL, 22, 1);COUNT(*) - MySQL内部转换为COUNT(0)
SELECT COUNT(*) FROM user_info; -- 结果: 5
关键技术细节:
- MySQL内部将COUNT(*)转换为COUNT(0)处理
- 0是常量,永远不为NULL
- 不需要读取任何字段值,只需要知道行存在即可
- 优化器会选择最小的可用索引进行扫描
COUNT(1) - 为每行创建值为1的虚拟字段
SELECT COUNT(1) FROM user_info; -- 结果: 5
底层执行机制:
- 为每一行创建一个字段值为1的虚拟序列
- 然后统计这些1的数量
- 由于1永远不为NULL,所以统计所有行
- 与COUNT(*)在InnoDB中处理方式完全相同
COUNT(主键字段) - 读取主键值判断
SELECT COUNT(id) FROM user_info; -- 结果: 5
执行过程:
- 需要读取每行的主键字段值
- 判断主键是否为NULL(实际上主键永远不为NULL)
- 比COUNT(*)多了"读取字段值"这一步
COUNT(普通字段) - 读取字段值并判断NULL
SELECT COUNT(email) FROM user_info; -- 结果: 3 (bob和eve的email为NULL) SELECT COUNT(age) FROM user_info; -- 结果: 4 (charlie的age为NULL) SELECT COUNT(status) FROM user_info; -- 结果: 4 (david的status为NULL)
执行机制:
- 必须读取每行的指定字段值
- 逐个判断字段值是否为NULL
- 只统计非NULL的行数
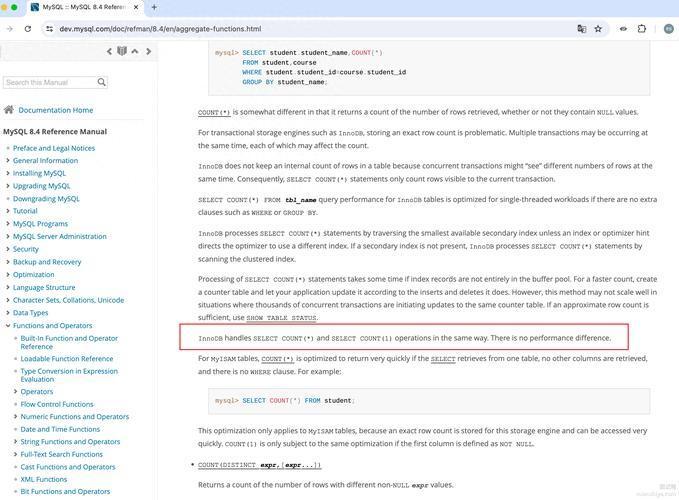
MySQL 5.7官方手册原文:
"InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference."
"InnoDB 以相同的方式处理 SELECT COUNT (*) 和 SELECT COUNT (1) 操作。它们在性能上没有差异。"
这意味着:
- COUNT(*)和COUNT(1)在存储引擎层面处理逻辑完全相同
- 性能差异可以忽略不计
- 都会选择最优的索引进行扫描
三、各种count的执行原理详解
1. count(主键字段) 执行过程
SELECT count(id) FROM t_order; -- id为主键
执行步骤:
- Server层维护一个count变量
- InnoDB循环读取记录(优先选择二级索引,因为占用空间更小)
- 读取每条记录的id值
- 判断id是否为NULL
- 不为NULL则count+1
- 返回最终count值
为什么优先选择二级索引?
- 二级索引只存储索引字段和主键值,数据量更小
- 遍历二级索引的I/O成本比聚簇索引低
- MySQL优化器会自动选择最优路径
2. count(1) 执行过程
SELECT count(1) FROM t_order;
执行步骤:
- Server层维护count变量
- InnoDB循环读取记录(优先二级索引)
- 不需要读取任何字段值(因为参数是常数1)
- 直接判断1是否为NULL(永远不为NULL)
- count+1
- 返回结果
为什么比count(主键)快一点?
 (图片来源网络,侵删)
(图片来源网络,侵删)- 少了"读取字段值"这一步骤
- 不需要访问具体的字段数据
3. count(*) 执行过程
SELECT count(*) FROM t_order;
重要说明:
- count(*)不是读取所有字段!
- MySQL内部会将*转换为0来处理
- 等价于count(0),执行过程与count(1)基本相同
MySQL官方说明:
 (图片来源网络,侵删)
(图片来源网络,侵删)InnoDB以相同的方式处理SELECT COUNT(*)和SELECT COUNT(1)操作,没有性能差异。
4. count(字段) 执行过程
SELECT count(name) FROM t_order; -- name为普通字段
为什么效率最差?
 (图片来源网络,侵删)
(图片来源网络,侵删)- 必须进行全表扫描
- 如果字段没有索引,只能扫描整个表
- 需要读取每条记录的具体字段值
- 需要判断每个字段值是否为NULL
- 增加了额外的判断步骤
- 无法利用索引优化
- I/O开销最大
- 需要访问实际的数据页
- 无法利用较小的索引结构
三、索引对count性能的影响
有二级索引的情况
-- 假设name字段有索引 CREATE INDEX idx_name ON t_order(name); SELECT count(name) FROM t_order;
- MySQL会选择key_len最小的二级索引进行扫描
- 避免了全表扫描,性能大幅提升
无二级索引的情况
- 只能使用主键索引(聚簇索引)
- 性能相对较差,但仍比全表扫描好
四、实际应用建议
1. 性能优化建议
-- ✅ 推荐:统计总记录数 SELECT count(*) FROM t_order; SELECT count(1) FROM t_order; -- ❌ 不推荐:统计总记录数时使用字段 SELECT count(name) FROM t_order; -- ✅ 如果必须统计某字段非NULL记录,建议加索引 CREATE INDEX idx_name ON t_order(name); SELECT count(name) FROM t_order;
2. 表结构优化
- 为大表建立合适的二级索引
- 优化器会自动选择最优的索引进行扫描
五、为什么InnoDB需要遍历计数?
MyISAM 和 InnoDB的区别
MyISAM存储引擎:
- 维护一个row_count变量存储总行数
- count(*)时间复杂度为O(1)
- 表级锁保证数据一致性
InnoDB存储引擎:
- 支持事务和MVCC(多版本并发控制)
- 同一时刻不同事务看到的行数可能不同
- 必须通过遍历来统计准确数量
举例说明MVCC影响
-- 会话A和会话B同时操作 -- 会话A: 删除一条记录但未提交 -- 会话B: 查询count(*) -- 两个会话看到的结果会不同!
六、大表count优化方案
方案1:近似值统计
-- 使用EXPLAIN获取估算值(速度很快) EXPLAIN SELECT * FROM t_order; -- 查看rows字段获取估算行数 -- 使用SHOW TABLE STATUS SHOW TABLE STATUS LIKE 't_order'; -- 查看Rows字段
方案2:独立计数表
-- 创建计数表 CREATE TABLE t_order_count ( table_name VARCHAR(50), row_count INT ); -- 在业务操作时同步维护 -- 插入记录时:count+1 -- 删除记录时:count-1 -- 查询时直接读取计数表 SELECT row_count FROM t_order_count WHERE table_name = 't_order';七、总结要点
- count(*) 和 count(1) 性能相近,都是最优选择
- count(字段) 效率最差,避免用于统计总记录数
- 建立二级索引可以显著提升count性能
- 大表统计考虑使用近似值或独立计数表
- 理解存储引擎差异:MyISAM直接返回,InnoDB需要遍历
八、常见误区澄清
❌ 错误认知: count(*)会读取所有字段,效率最低
✅ 正确理解: count(*)内部转换为count(0),效率很高
❌ 错误认知: count(1)一定比count(*)快
✅ 正确理解: 两者性能基本相同,MySQL官方确认无差异
❌ 错误认知: 有索引的字段用count(字段)效率很高
✅ 正确理解: 仍不如count(*),因为需要判断NULL值
- 必须进行全表扫描
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







