
Lambda架构与Kappa架构对比详解

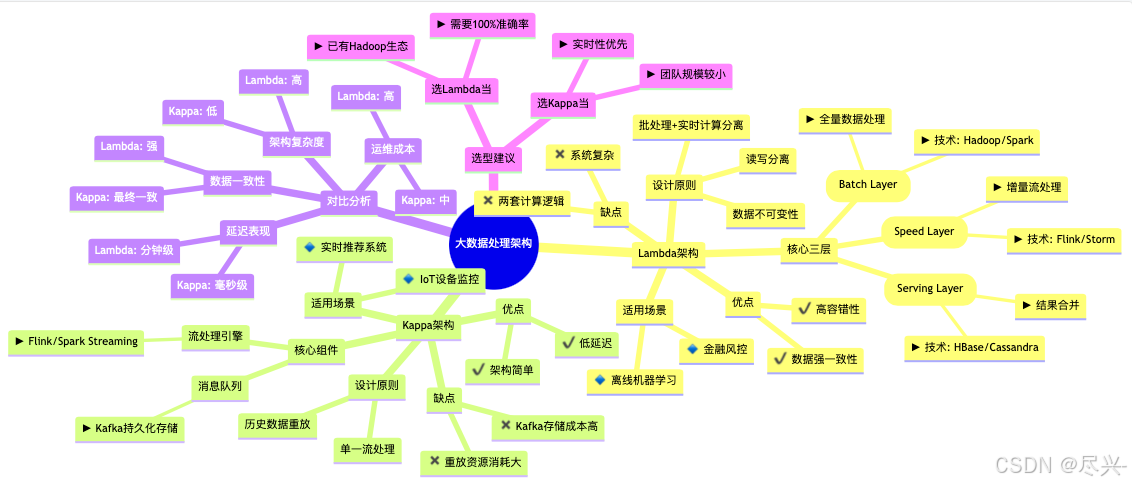
1. Lambda架构
1.1 设计目的
Lambda架构旨在满足大数据系统的关键特性,包括:
- 高容错性(Fault Tolerance)
- 低延迟(Low Latency)
- 可扩展性(Scalability)
其核心思想是整合离线计算与实时计算,并融合以下原则: - 数据不可变性(Immutable Data)
- 读写分离(Read-Write Separation)
- 复杂性隔离(Complexity Isolation)
Lambda架构适用于同时处理离线和实时数据的分布式系统,具备强鲁棒性,能提供低延迟查询和持续数据更新。
1.2 应用场景
- 机器学习(离线训练+实时预测)
- 物联网(IoT)(设备数据实时处理+历史数据分析)
- 流处理(如金融风控、广告点击分析)
1.3 架构分层
Lambda架构可分为三层:批处理层(Batch Layer)、加速层(Speed Layer)、服务层(Serving Layer)。
(1) 批处理层(Batch Layer)
- 功能:存储主数据集,并预先计算查询函数,生成Batch View(批处理视图)。
- 特点:
- 处理全量数据,确保高准确性。
- 计算周期较长(如每小时/每天计算一次)。
- 技术实现:
- 存储:HDFS(Hadoop Distributed File System)
- 计算:MapReduce、Spark
(2) 加速层(Speed Layer)
- 功能:处理增量数据流,生成Real-time View(实时视图)。
- 特点:
- 低延迟(毫秒级响应)。
- 仅处理最新数据,不保证全局一致性。
- 技术实现:
- 流计算引擎:Apache Storm、Apache Flink
- 消息队列:Apache Kafka
(3) 服务层(Serving Layer)
- 功能:合并Batch View和Real-time View,提供最终查询结果。
- 特点:
- 支持低延迟查询。
- 存储优化,支持快速检索。
- 技术实现:
- 数据库:HBase、Cassandra
- 查询引擎:Presto、Hive
1.4 架构图
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。







