
LLAMA-Factory微调大模型(非webui)

本文用来记录利用llama-factory对qwen大模型的微调过程。
LLAMA-Factory的配置
项目地址:hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
我的环境配置:
- Windows 2022 server
- NVIDIA A10
首先创建环境:
conda create -n lf python=3.10 conda activate lf git clone https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]"
运行完了之后验证一下cuda即可。我这次微调的大模型为qwen2.5-7B-instruct版本,可以从huggingface(不推荐,慢)或modelscope获取,如下所示:
from modelscope import snapshot_download model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')下载好后的模型位于.cache文件夹下,输出信息也会有详细的文件地址,这个路径要记住,或像我一样直接把整个Qwen文件夹搬到LLaMA-Factory文件夹下便于使用。
数据集准备
以我的微调为例,我想要对大模型预测信息这块进行微调,因此我准备的数据集也十分简单,格式如下所示:
[ { "prompt": "你是一个专业的用户性别分析专家。请根据用户观看的历史视频内容,分析用户的性别。请直接给出结果,不需要分析过程。-用户观看历史视频种类与标题:[xxx]", "answer": "女" }, { "prompt": "你是一个专业的用户性别分析专家。请根据用户观看的历史视频内容,分析用户的性别。请直接给出结果,不需要分析过程。-用户观看历史视频种类与标题:[xxx]", "answer": "女" }, { "prompt": "你是一个专业的用户性别分析专家。请根据用户观看的历史视频内容,分析用户的性别。请直接给出结果,不需要分析过程。-用户观看历史视频种类与标题:[xxx]", "answer": "女" }, { "prompt": "你是一个专业的用户性别分析专家。请根据用户观看的历史视频内容,分析用户的性别。请直接给出结果,不需要分析过程。-用户观看历史视频种类与标题:[xxx]", "answer": "女" }, { "prompt": "你是一个专业的用户性别分析专家。请根据用户观看的历史视频内容,分析用户的性别。请直接给出结果,不需要分析过程。-用户观看历史视频种类与标题:[xxx]", "answer": "女" } ]上面的是一个json文件,其中prompt为我们输入给大模型的内容,answer为预期的回答,也就是lable,至于这个数据集如何构建的这里就不做赘述了。
然后我们需要在LLaMA-Factory/data下修改dataset_info.json文件,假如我们上面的数据集名字为data_test.json,放在LLaMA-Factory/data下,我们需要添加如下一段话:
"data_train": { "file_name": "data_test.json", "columns": { "prompt": "prompt", "response": "answer" } },这段不难理解,就是告诉大模型我这个数据集里的内容是什么,file_name为data下数据集名称,"data_train"为自定义的数据集名称,后续使用数据集都用的这个自定义的名字。
微调大模型
我采用的是lora的方式对大模型进行微调,因此配置了一个yaml文件来使用,可以看examples/train_lora下的一堆yaml文件来编写,其实就是定义训练和评估的各种超参数,这里给出我用的例子:
### model model_name_or_path: C:/lds/LLaMA-Factory/Qwen/Qwen2.5-7B-Instruct ### method stage: sft do_train: true finetuning_type: lora lora_target: all ### dataset dataset: data_train template: qwen cutoff_len: 1024 max_samples: 10000 overwrite_cache: true preprocessing_num_workers: 16 ### output output_dir: C:/lds/LLaMA-Factory/output_model_age logging_steps: 10 save_steps: 1000 plot_loss: true overwrite_output_dir: true ### train per_device_train_batch_size: 1 gradient_accumulation_steps: 8 learning_rate: 1.0e-4 num_train_epochs: 10 lr_scheduler_type: cosine warmup_ratio: 0.1 bf16: true ddp_timeout: 180000000 ### eval val_size: 0.1 per_device_eval_batch_size: 1 eval_strategy: steps eval_steps: 1000
然后就可以开始运行微调代码了,打开一个lf环境的终端,输入如下命令:
llamafactory-cli train examples/train_lora/[你的yaml文件名].yaml
此时终端会输出训练的各种信息,然后就开始微调了:
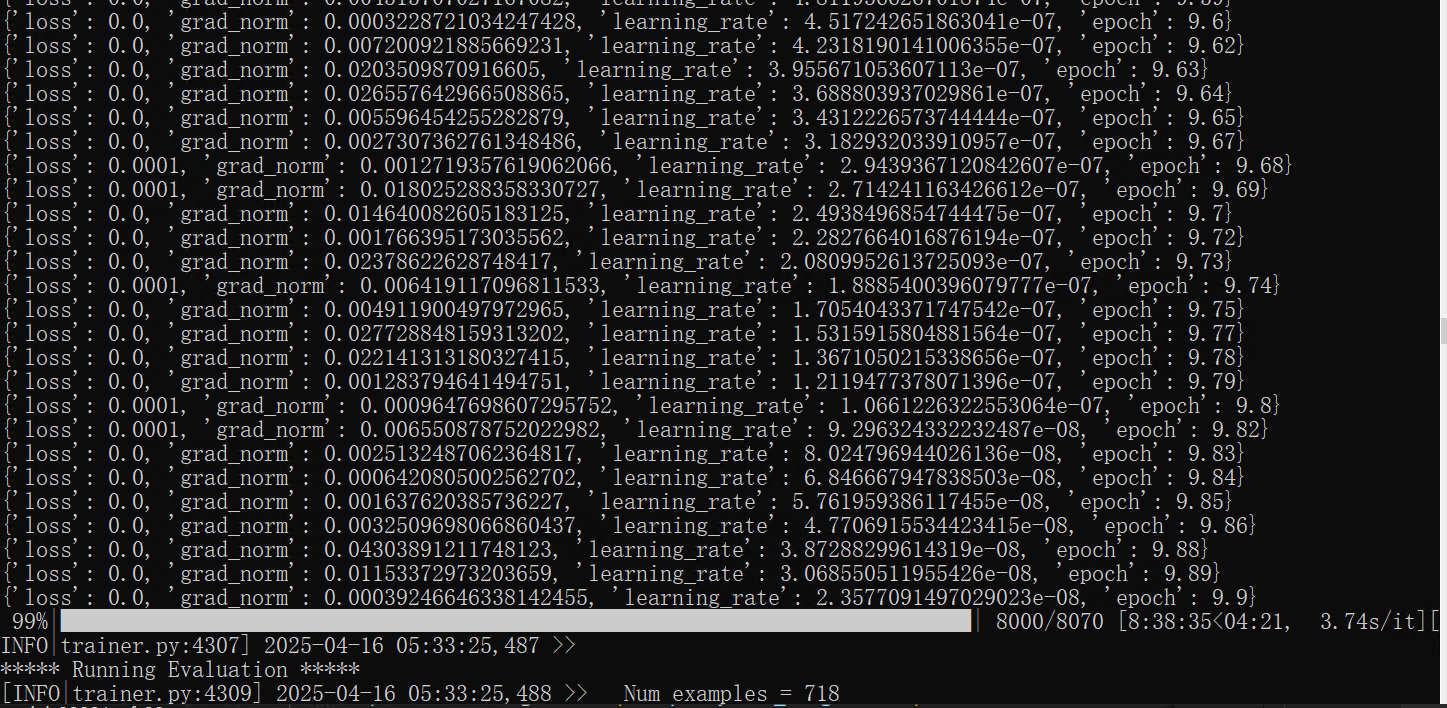
微调后使用
在上面的微调训练完成后,会把lora模型文件存放在预设好的目录下,我们可以自己写一个加载lora模型的代码供封装使用,当然也可以用llama-factory自带的来使用,同时这里也给出批量调用执行预测的一个案例:
正常单次循环调用
打开终端,执行:
llamafactory-cli chat --model_name_or_path C:/lds/LLaMA-Factory/Qwen/Qwen2.5-7B-Instruct --adapter_name_or_path C:/lds/LLaMA-Factory/output_model/checkpoint-2421
注意,这里都是我的绝对路径,需要替换为实际的模型路径以及lora模型路径,然后等加载完毕就会提示输入了:
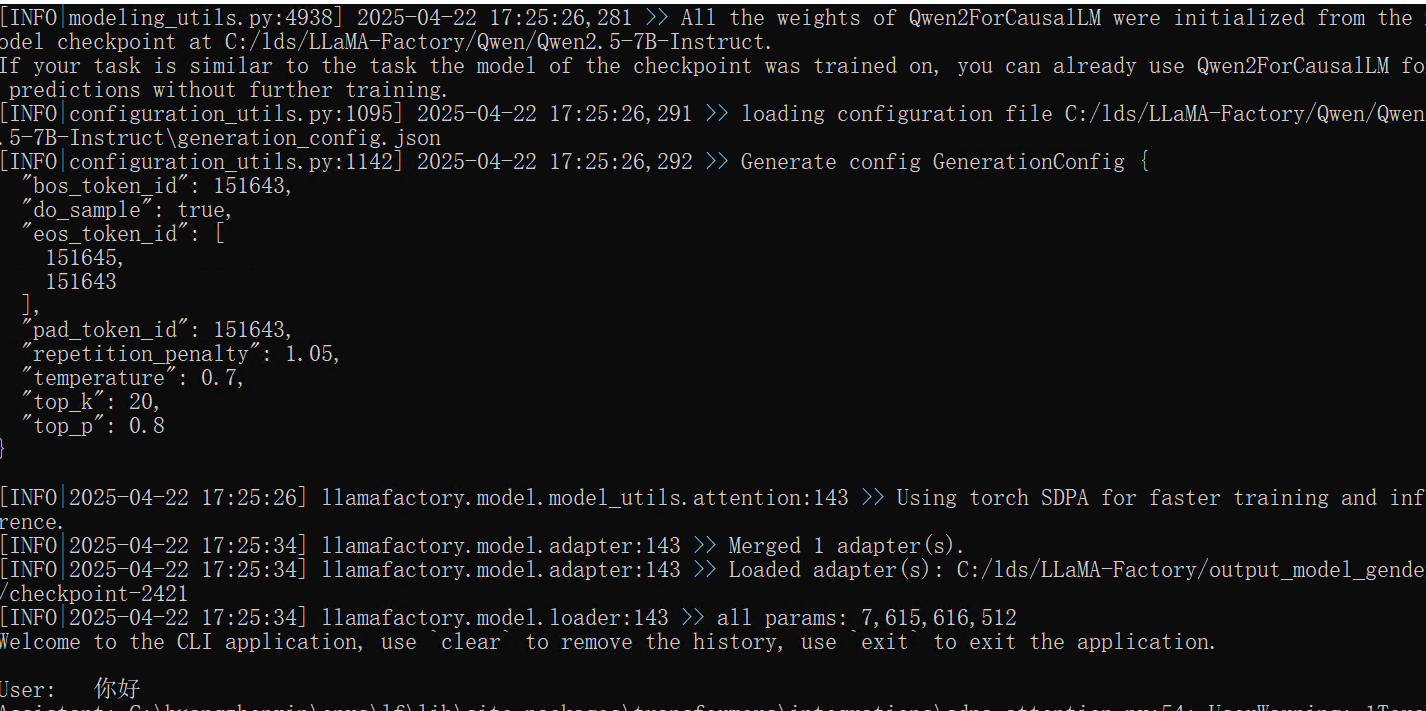
按数据集预测
按上面数据集准备的操作批量准备输入,此时的answer可以是任意值,因为用不到,然后准备如下的yaml文件(参考):
### model model_name_or_path: C:/lds/LLaMA-Factory/Qwen/Qwen2.5-7B-Instruct adapter_name_or_path: C:/lda/LLaMA-Factory/output_model/checkpoint-2000 ### method stage: sft do_predict: true finetuning_type: lora ### dataset dataset: data_test template: qwen cutoff_len: 1024 max_samples: 2000 overwrite_cache: true preprocessing_num_workers: 16 ### output output_dir: C:/lds/LLaMA-Factory/output_result overwrite_output_dir: true ### eval per_device_eval_batch_size: 1 predict_with_generate: true ddp_timeout: 180000000
然后同上面微调大模型的方法执行,即可在output_result文件夹下的generate_predictions.jsonl文件中看到结果了,包括原始的大模型信息与输入信息,还有大模型的回答(key为predict)以及前面设置的没用的answer(key为label)。



