
前端读取excel的xlsx文件,支持读取表格中的图片

本例使用react + antd 实现 核心代码没啥区别
核心步骤
- 读取文件,拿到file对象
- 处理file中的数据,其中分别包括文本数据以及图片数据
- 首先使用Upload组件拿到文件的file对象
{
// 这就拿到了file对象 handleUpload为处理file对象的方法
handleUpload(file);
return false;
}}
showUploadList={false}
>
添加
- 处理file中的数据
举一个简单的例子,这是一个xlsx文件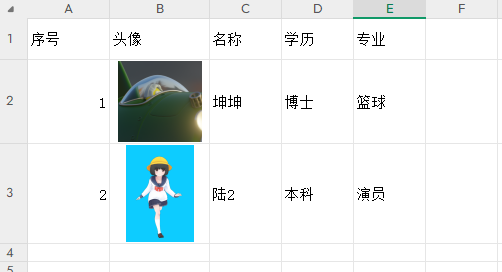
我们引入xlsx这个库,对读取的信息进行处理
import * as XLSX from "xlsx";
......
const handleUpload = async (file: Blob) => {
// 异步读取文件
const reader = new FileReader();
reader.onload = (e: any) => {
// 格式化数组
const data = new Uint8Array(e.target.result);
// 读取文件内容
const workbook = XLSX.read(data, {
type: "array" });
// 如果指定了 sheetName,则将其用于查找工作表;否则,使用默认的第一个工作表。
const worksheet = workbook.Sheets[workbook.SheetNames[0]];
// 将工作表数据转换为 JSON 格式
const jsonData: any = XLSX.utils.sheet_to_json(worksheet, {
header: 1 });
// 判断所选工作区的内容是否为空
if (jsonData.length > 0) {
const newData: any[] = [];
// 第一行默认认为是表头 除开第一行以外都是数据
jsonData.slice(1).forEach((item, itemIndex: number) => {
if (item.length === 0) return false;
const obj: any = {
key: itemIndex };
jsonData[0].forEach((header: any, index: any) => {
obj[header] = item[index];
});
newData.push(obj);
});
console.log(newData)
} else {
console.log("没数据");
}
}
reader.readAsArrayBuffer(file);
}
可以看到打印的数据中, 除了图片列,其他的文本列的数据都正常拿到了

而头像的数据没有返回图片的信息,仅仅是一个可能是id的字符串,既然是id,那说明这个图片一定可以根据这个id找到
根据xlsx这种类型的文件,官方给出解释
那么我们可以通过jszip这个库来对xlsx文件进行解析,从而可以拿到所有的xml文件。
try {
const zip = new JSZip();
let zipLoadRes = await zip.loadAsync(file);
console.log(zipLoadRes);
} catch (err) {
console.log("err", err);
}
通过打印数据,可以看到里面出现了图片信息
可以看到xl文件夹下面包含了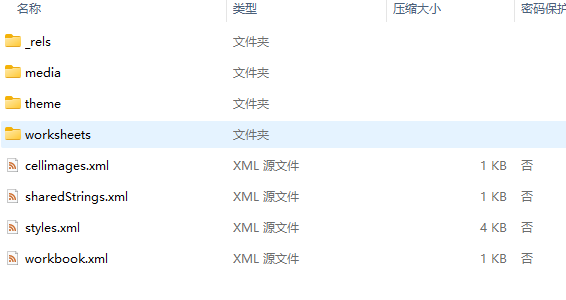
打开其中的cellimages.xml文件可以看到其中几条数据和我们前面拿到的id是一样的,同时各个id还对应了一个rid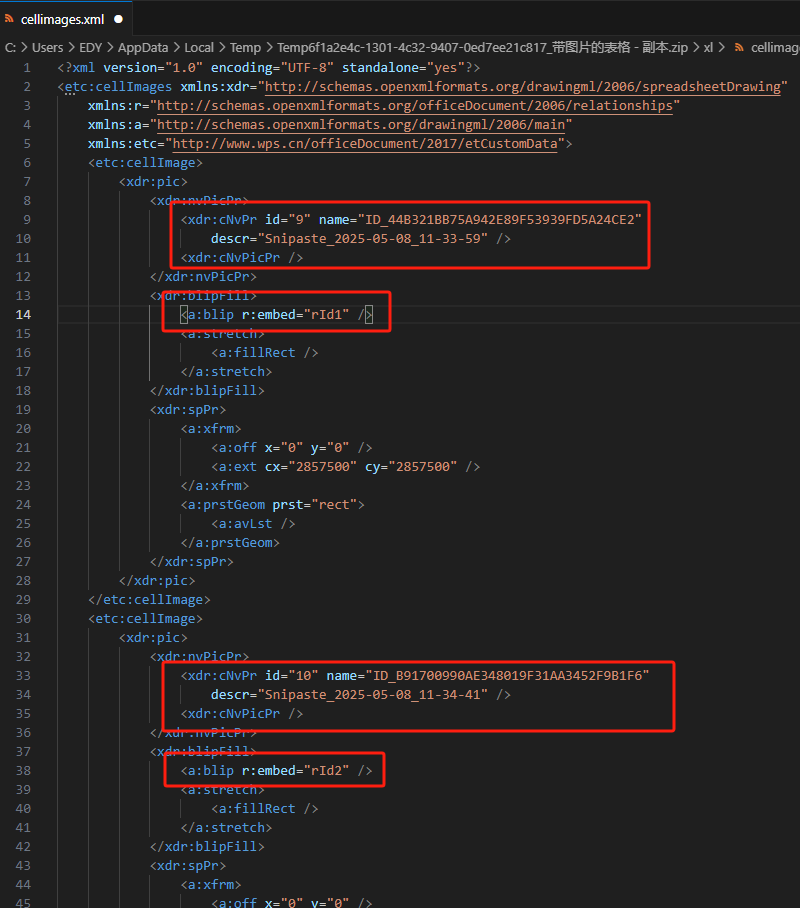
而在 xl/_rels/cellimages.xml.rels 文件下,对应的 rid 下,又分别对应着image的名称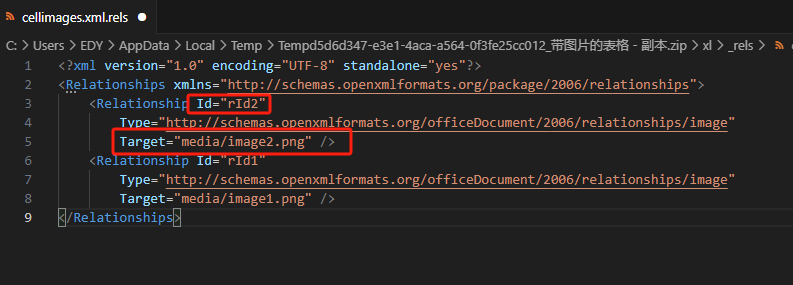
那么我们就可以一步一步的来根据id,组合出一个id对应的图片对象,代码如下:
let imageList: IImageInfo[] = [];
let implantBlobList = [];
/** @name 针对嵌入了单元格的图片 */
const implantFile = zipLoadRes.files["xl/cellimages.xml"];
if (implantFile) {
const xmlContent = await implantFile.async("string");
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(xmlContent, "text/xml");
if (xmlDoc.getElementsByTagName("parsererror").length > 0) {
console.error(
"XML 解析错误:",
xmlDoc.getElementsByTagName("parsererror")[0].textContent
);
return;
}
// 查找所有的 标签
const cellImage = xmlDoc.querySelectorAll("etc\\:cellImage, cellImage");
cellImage.forEach((cellImage) => {
// 查找 标签
const picElement = cellImage.querySelector("xdr\\:pic, pic");
if (picElement) {
let obj: Partial = {
};
// 查找 标签
const nvPicPrElement = picElement.querySelector(
"xdr\\:nvPicPr, nvPicPr"
);
// 查找 标签
const blipFillElement = picElement.querySelector(
"xdr\\:blipFill, blipFill"
);
if (nvPicPrElement && blipFillElement) {
// 查找 标签
const blipElement = blipFillElement.querySelector(
"a\\:blip, blip"
);
if (blipElement) {
const embedValue = blipElement.getAttribute("r:embed") || "";
obj.rid = embedValue;
}
// 查找 标签
const cNvPrElement = nvPicPrElement.querySelector(
"xdr\\:cNvPr, cNvPr"
);
if (cNvPrElement) {
const nameValue = cNvPrElement
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



