
【落羽的落羽 C++】stack和queue、deque、priority

文章目录
- 一、stack和queue
- 1. 概述
- 2. 使用
- 3. 模拟实现
- 二、deque
- 三、priority_queue
- 1. 概述和使用
- 2. 模拟实现
- 四、仿函数
一、stack和queue
1. 概述
我们之前学习的vector和list,以及下面要认识的deque,都属于STL的容器(containers)组件。而stack和queue,属于STL的配置器(或称为配接器)(adapters)组件,或者归类为容器配置器(container adapters),它们可以修饰容器的接口而呈现出全新的容器性质,即stack的“先进后出”和queue的“先进先出”特点。
2. 使用
stack的所有元素的进出都必须符合“先进后出”的条件,queue的所有元素的进出都必须符合“先进先出”的条件。换句话说,只有stack的栈顶元素和queue的队头元素才有机会被移除,因此stack和queue不提供遍历的功能,也不提供迭代器。
除此之外,stack和queue的功能和使用也都很好理解了,之前我们已经学过栈和队列。
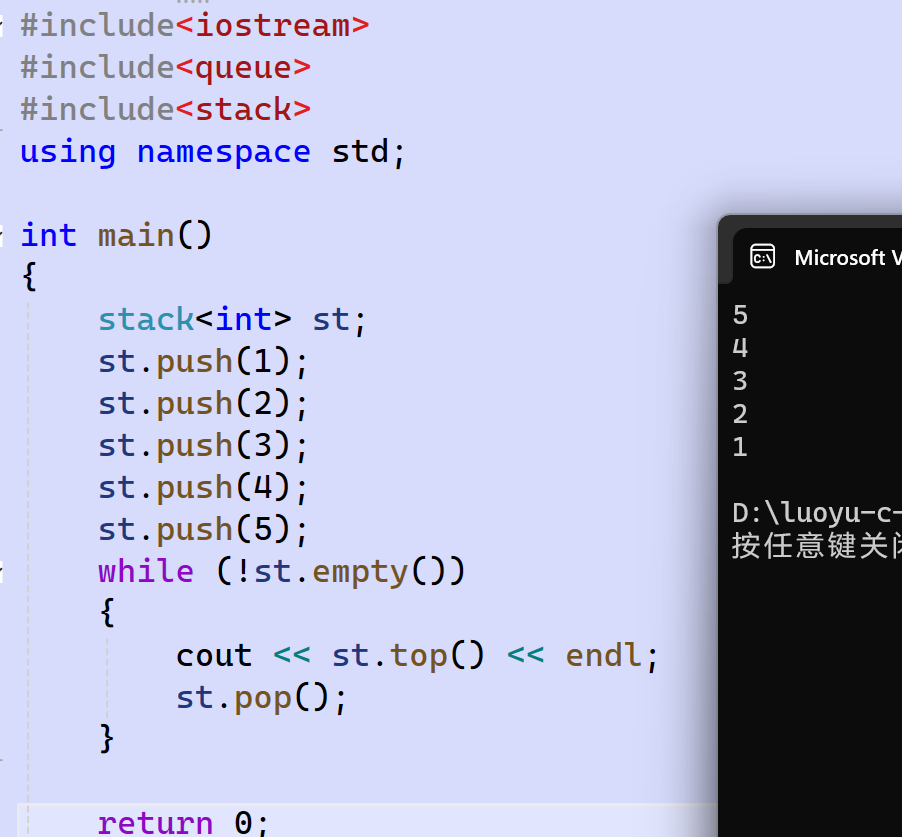
- stack:
函数声明 接口说明 stack() 构造空的栈 empty() 检测栈是否为空 size() 返回栈中元素个数 top() 返回栈顶元素的引用 push() 在栈顶入栈 pop() 将栈顶元素出栈 使用演示:
- queue:
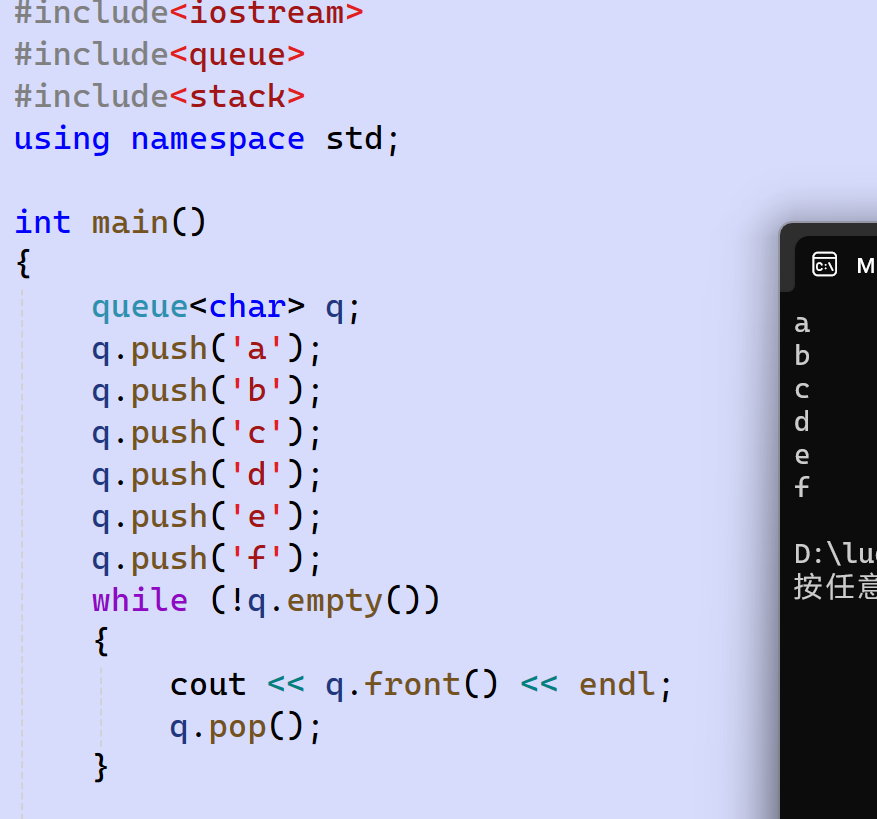
函数声明 接口说明 queue() 构造空的队列 empty() 检测队列是否为空 size() 返回队列中元素个数 front() 返回队头元素的引用 back() 返回队尾元素的引用 push() 在队尾入队列 pop() 将队头元素出队列 使用演示:
3. 模拟实现
STL库中的stack和queue的模板实际上有两个模板参数类型:


第一个就是要存储的数据类型了。第二个代表它们所修饰的容器类型,前面说过,它们不是独立的容器,而是容器配置器,要依靠别的容器才能实现它们,这就是第二个模板参数的意义。我们可以用vector或list来实现出stack和queue,如stack或queue,我们在上层使用stack和queue时是感受不到vector或list的区别的。不论是哪种容器,都有push、pop、front、back、empty等相关操作,得以再封装成stack和queue的功能。
模板参数也是可以有缺省值的,我们能看到STL标准库中的stack和queue的Container模板类型默认给了deque,deque也是一种容器,我们一会再介绍它。
除了这一点,stack和queue的模拟实现就很简单了,遵循它们的特性就好:
namespace lydly { template class queue { private: Container _con; public: void push(const T& x) { _con.push_back(x); } void pop() { _con.pop_front(); } T& front() { return _con.front(); } const T& front() const { return _con.front(); } T& back() { return _con.back(); } const T& back() const { return _con.back(); } bool empty() const { return _con.empty(); } size_t size() const { return _con.size(); } }; template class stack { private: Container _con; public: void push(const T& x) { _con.push_back(x); } void pop() { _con.pop_back(); } T& top() { return _con.back(); } const T& top() const { return _con.back(); } bool empty() const { return _con.empty(); } size_t size() const { return _con.size(); } }; }二、deque
关于deque,简单了解就好。
对比一下vector和list的优缺点:
容器 优点 缺点 vector 支持下标随机访问、CPU高速缓存命中率高 头部或中部插入删除数据效率低、扩容有一定成本,存在一定浪费 list 任意位置插入删除数据效率高、不用扩容,按需申请空间,不存在浪费 不支持下标随机访问、CPU高速缓存命中率低 可见,vector和queue都有各自的优缺点,deque包含了两种容器的优点,是一种双向开口的线性连续空间
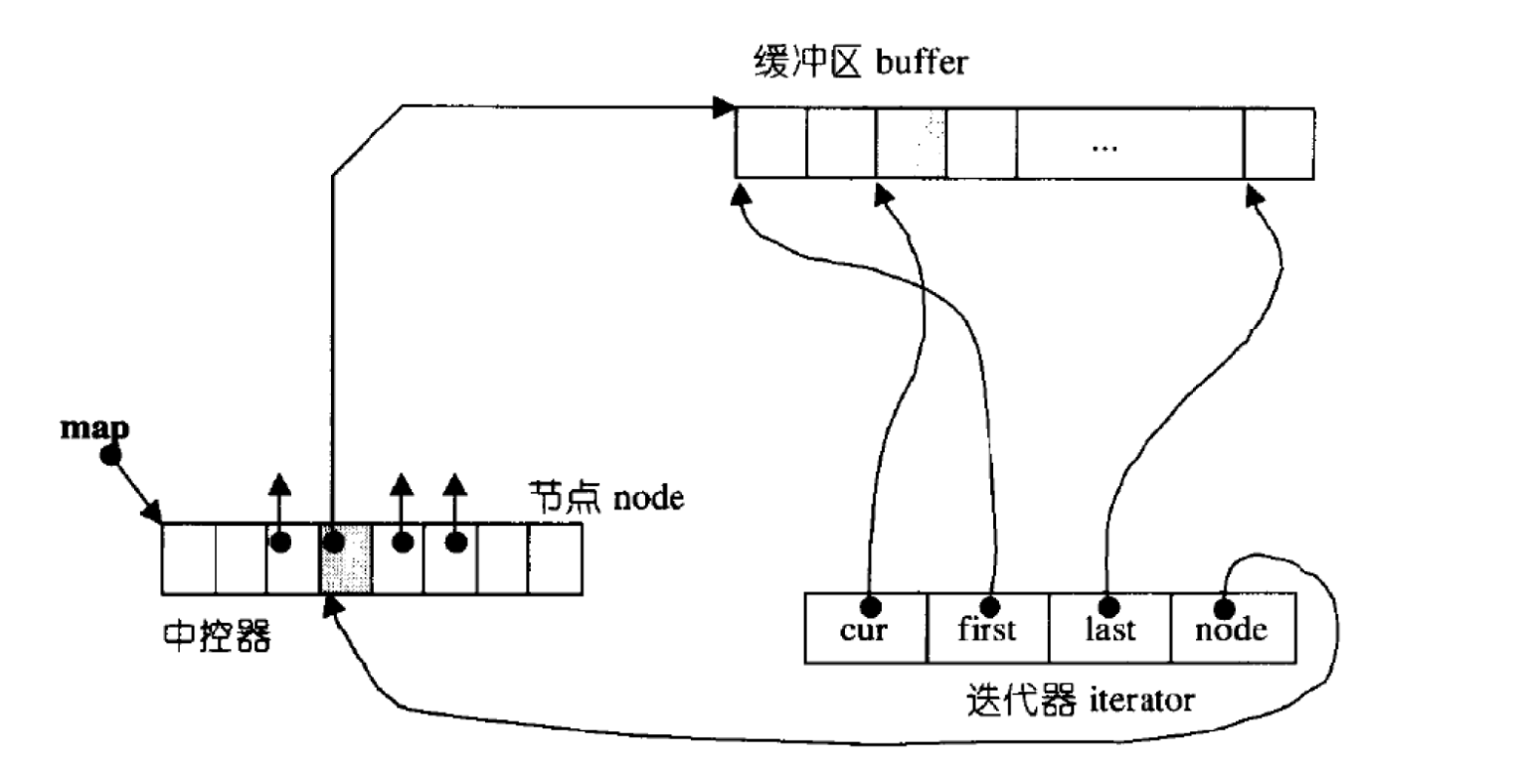
deque有一个中控器,存放着指向不同节点的指针,每一个节点是一个缓冲区buffer,是一个数组用于存放数据。执行尾插时,就在当前buffer的尾部插入数据,若当前buffer已满,就去中控器的下一个节点指向的buffer的第一个位置存放;执行头插时,要倒着看,当前buffer头部没有空间,就去中控器的上一个节点指向的buffer的最后一个位置存放,再头插一次就存放到倒数第二个位置,以此类推。头删和尾删也是一样的道理。
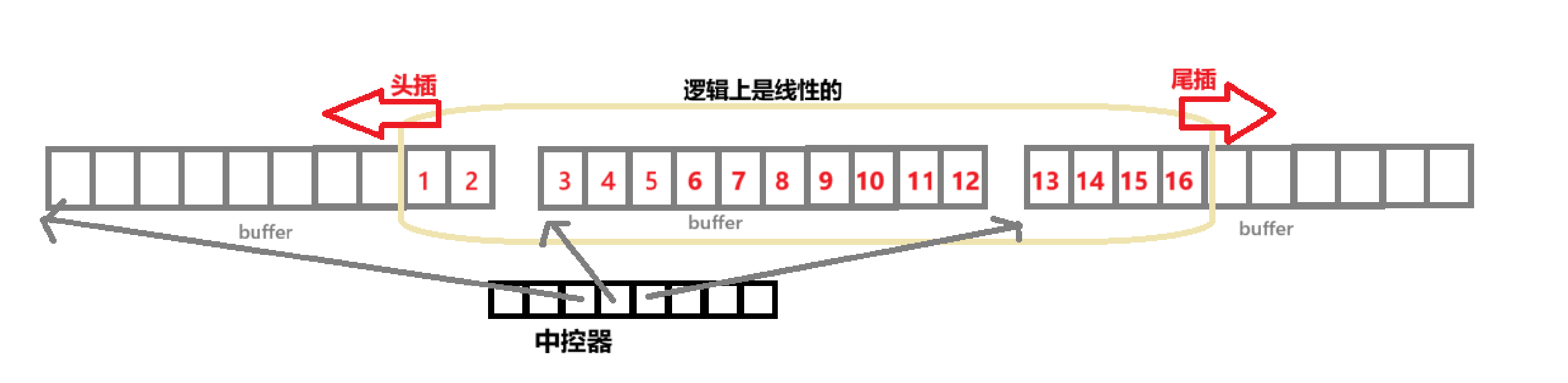
deque并不是真正完全连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似一个动态的二维数组,deque的迭代器的结构就更为复杂了。
所以,deque与vector相比,头部插入效率更高,不需要挪动元素;与list相比,空间利用率更高。但是,deque不适合遍历,因为在遍历时迭代器需要频繁检测每一个buffer是否到达边界,导致效率低下。而在序列式场景中,可能经常需要遍历,所以实际需要线性数据结构时,大多数情况下优先考虑vector和list,deque的应用并不多,目前能看到的一个应用就是STL用它作为stack和queue的底层数据结构。
而STL选择deque作为stack和queue的底层,主要原因也是stack和queue不需要遍历,只在固定的一端或两端进行操作,以及deque结合vector和list的优点了。
三、priority_queue
1. 概述和使用
priority_queue,意为优先级队列,是queue的一种,带有权值观念,其内的元素并非按照入队列的顺序排列,而是按照元素的权值排列,默认权值较高的元素排在前面。
举个栗子:
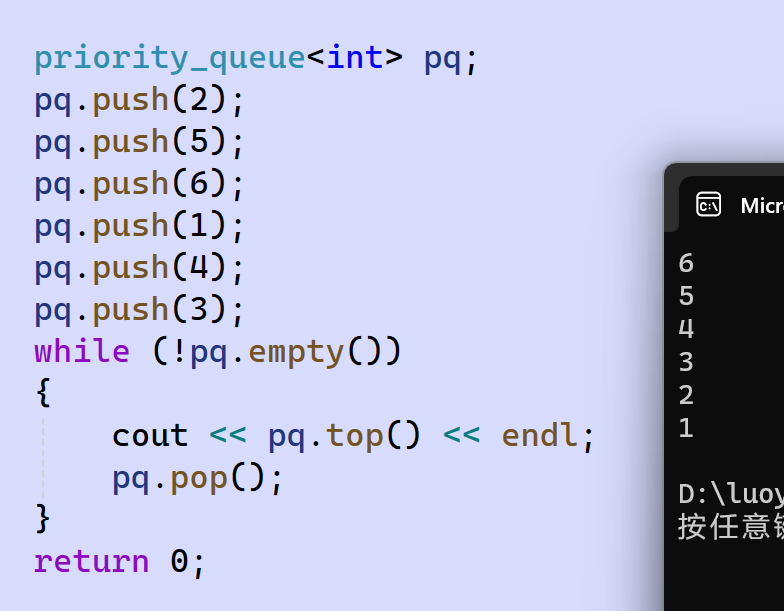
有没有发现,优先级队列其实就是我们之前学过的堆。

优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的场景,都可以考虑使用优先级队列。默认情况下,优先级队列是大堆。
函数声明 接口说明 priority_queue() 构造空的优先级队列 empty() 检测优先级队列是否为空 size() 返回优先级队列中元素个数 top() 返回优先级队列中的最大(最小)元素,即堆顶元素 push() 在优先级队列中插入元素 pop() 删除优先级队列中的最大(最小)元素,即堆顶元素 2. 模拟实现
既然优先级队列就是堆,那么实现优先级队列也就和实现堆道理类似了:
传送门:https://blog.csdn.net/2402_86681376/article/details/145808942?spm=1011.2415.3001.5331(堆的讲解
要用到的向上调整算法、向下调整算法,我们都学习过了。
namespace lydly { template class priority_queue { private: Container _con; public: priority_queue() { } void push(const T& x) { _con.push_back(x); adjustup(_con.size() - 1); } void pop() { swap(_con[0], _con[_con.size() - 1]); _con.pop_back(); adjustdown(0); } const T& top() const { return _con[0]; } bool empty() const { return _con.empty(); } size_t size() const { return _con.size(); } private: void adjustup(int child) { int parent = (child - 1) / 2; while (child > 0) { if (_con[parent]问题来了,我们想让优先级队列降序排列元素,再重载一次·未必太麻烦了,怎么办呢?这里就需要用到仿函数。
四、仿函数
在STL标准库中,我们看到优先级队列的模板参数中还有一个Compare,这个就是仿函数。

仿函数是一种类对象,顾名思义,它可以“模仿函数”,允许用户“以模板参数来指定所要采取的策略”。在priority_queue中,它的第三个模板类型参数就是仿函数,默认给了一个less,less其实是这样的:
template class less { public: bool operator()(const T& x, const T& y) { return xless是一个类,less就是一个匿名对象,它的里面重载了(),这样一来,倘若有less Com;那我们就可以写出Com(a, b),(a,b是T类型的)这个表达式的意思就是a
举一反三,STL中还有greater的仿函数:
template class greater { public: bool operator()(const T& x, const T& y) { return x > y; } };倘若有greater Com;那我们就可以写出Com(a, b),这个表达式的意思就是a > b!
大堆和小堆的区别在于AdjustUp和AdjustDown中几处的不同,有了上面的两种仿函数,我们就能在创建优先级队列时根据需要,模板参数传less或greater,区分大堆和小堆。具体是,就可以依靠传的是less还是greater来分别。STL的仿函数中的less和greater,就可以传给priority_queue的模板:
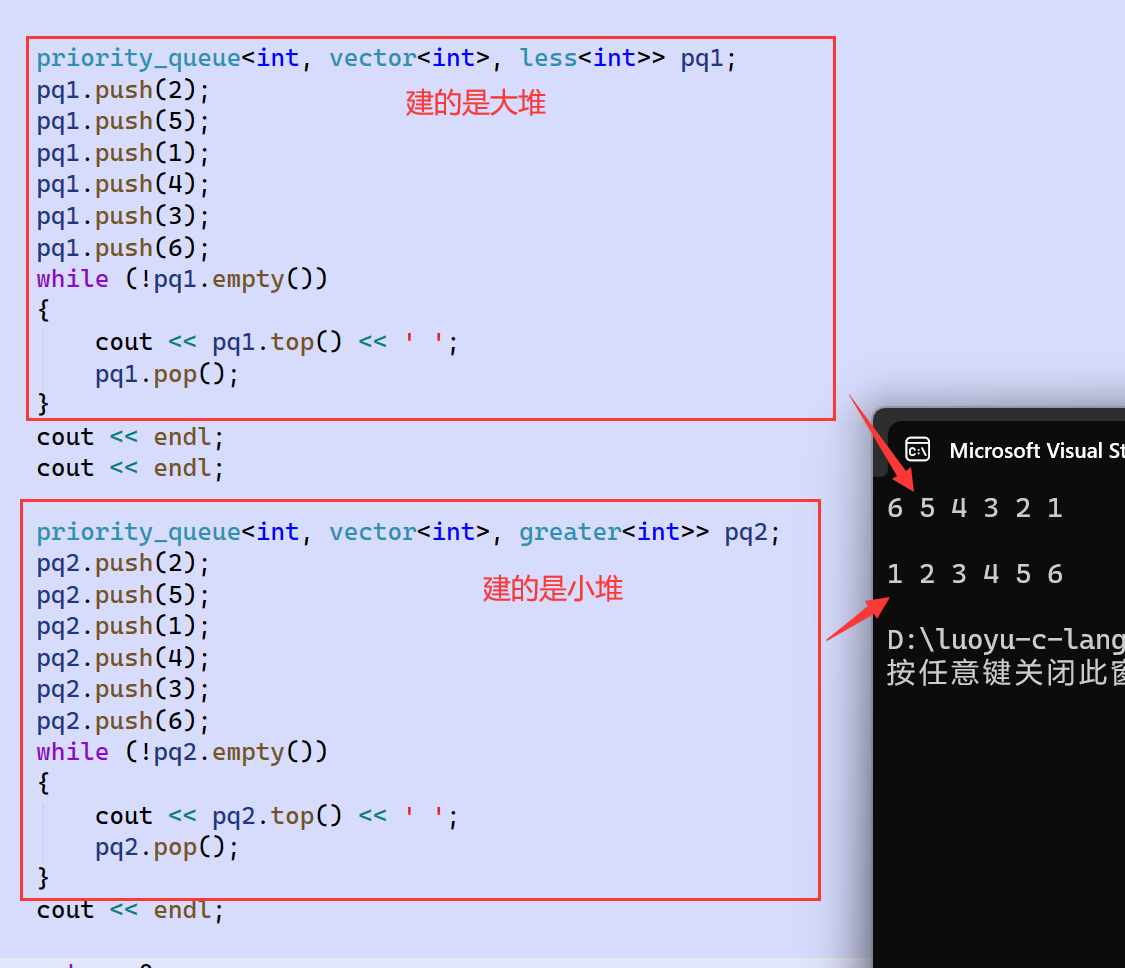
我们的模拟实现也按照这个思路来完成:
namespace lydly { template class less { public: bool operator()(const T& x, const T& y) { return x y; } }; template class priority_queue { private: Container _con; public: priority_queue() { } void push(const T& x) { _con.push_back(x); adjustup(_con.size() - 1); } void pop() { swap(_con[0], _con[_con.size() - 1]); _con.pop_back(); adjustdown(0); } const T& top() const { return _con[0]; } bool empty() const { return _con.empty(); } size_t size() const { return _con.size(); } private: void adjustup(int child) { //构造一个less或greater的对象 Compare com; int parent = (child - 1) / 2; while (child > 0) { if (com(_con[parent], _con[child])) { swap(_con[child], _con[parent]); // child = parent; parent = (child - 1) / 2; } else { break; } } } void adjustdown(size_t parent) { //构造一个less或greater的对象 Compare com; size_t child = parent * 2 + 1; while (child关于less,我们还可能会遇到其他情况:
- 当想要比较的是自定义类型时,就需要这个自定义类型中重载运算符,这一点很好理解。
- 当传入指针时,一般我们应该是想要比较的是指向的内容,但如果只把less写成刚才那样,会被解析成直接比较两个地址的值。这时,需要写成这样:
template class less { public: bool operator()(const T* const & x, const T* const & y) { return *x
- queue:
- stack:



