
π0源码剖析——从π0模型架构的实现(如何基于PaLI-Gemma和扩散策略去噪生成动作),到基于C/S架构下的模型训练与部署

前言
ChatGPT出来后的两年多,也是我疯狂写博的两年多(年初deepseek更引爆了下),比如从创业起步时的15年到后来22年之间 每年2-6篇的,干到了23年30篇、24年65篇、25年前两月18篇,成了我在大模型和具身的原始技术积累
如今一转眼已到25年3月初,时光走得太快,近期和团队接了好几个大客户订单,使得3月起 不得不全力加速落地,自己也得每天抠paper、搞代码
so,为何在明明如此之忙 一天当两天用的情况下,还要继续努力更新博客呢?
原因在于
- 一方面,我确实喜欢分享,因为写博的这10多年下来 确实可以帮到很多、很多人,不然本博客也不会有如今如此巨大的访问量与影响力
更何况有些文章是之前既定计划中的,在本文之前,上一篇关于π0的文章是π0_fast《π0开源了且推出自回归版π0-FAST——打造机器人动作专用的高效Tokenizer:比扩散π0的训练速度快5倍但效果相当》,文中提到,会解读π0的源码
至于什么是π0
详见此文《π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂(基于PaliGemma和流匹配的3B模型)》
- 二方面,我司「七月在线」在做一系列工厂落地场景的过程中,我们也希望团结到可以和我们一块做的朋友,而若想团结,便需要借助博客 顺带分享我们每个季度在重点做的业务场景
比如过去一周,我把lerobot、reflect vlm、π0的仿真环境都在我自己本地电脑上跑了下
过程中,GitHub copilot这种AI编程工具在环境的安装上帮了我很大的忙——各种环境 只要几句命令,直接帮我装好,真心不错)

如此硬着头皮冥思苦想、摸索了好几天,随后使得我自己知道怎么带队完成『太多工厂希望实现的一个生产线任务』了,3月初先仿真训练,2-3个月内部署到真机
当然了,也不单纯只是「这几天的想」就能想出来的,这几天之前
- 有把过去一年当三年用的具身技术积累
- 有一年多来,和同事们 如姚博士,以及朋友们许多的讨论
- 有去年十几个工厂对我们的支持与信任
我们正在不断壮大队伍
- 有我司内部同事,亦有我联合带的北理、中南等985的具身研究生,及一块合作开发的朋友,很快会把多个生产线任务并行开发起来
- 且无论哪个项目,都是不断长期迭代的,故过程中少不了科研层面的突破,欢迎更多伙伴加入我们(全、兼、实习皆可,有意者,敬请私我),和我们一块开发
话休絮烦,本文便按照如下图所示的源码结构,重点解读一下π的整个源码 「 π0及π0-FAST的GitHub地址:github.com/Physical-Intelligence/openpi」
- π0的源码结构非常清晰、可读性高,不愧是成熟的商业化公司,是我司七月的学习榜样之一
另,我在解读时,除了尽可能像解读iDP3那样,比如特意在分析代码文件之前,贴一下对应的代码结构截图——避免只是堆砌代码,我还会尽可能把模块之间、模块内部的函数之间彼此的联系及互相调用的关系 都阐述出来
如此,不但从宏观上做到一目了然(注意,本文按照上图π0的代码结构,先解读src模块下的model-对应下文第一部分、policy-对应下文第二部分、training-对应下文第三部分,第四部分则解读图中src上面的packages/openpi-client,以及scripts),更从微观上做到抽丝剥茧,看到彼此的联系与调用关系
- 我身边的很多朋友目前都在做π0的微调及二次开发,相信本文无论对我身边的朋友,还是对更多人的学习与工作,都会起到比较大的提升
PS,有兴趣或也在对π0做微调的,欢迎私我一两句自我简介(比如在哪个公司做什么,或在哪个高校研几什么专业),邀请进:『七月具身:π0复现微调交流群』
第一部分 π0模型架构的实现:src下models的全面分析与解读
接下来,我们来看核心src下的各个模块,首先是其中的src/openpi/models

1.1 models/model.py:核心基础模型的定义
这是模型框架的核心文件,定义了基础的抽象类和数据结构:
- `BaseModelConfig`: 所有模型配置的抽象基类
- `BaseModel`: 所有模型实现的抽象基类
- `Observation`: 保存模型输入的数据类
- `Actions`: 定义动作数据格式
- 提供了通用功能如`preprocess_observation`和`restore_params`
1.1.1 基础组件和关键常量
首先是模型类型枚举,定义了两种支持的模型类型:
- `PI0`:标准PI0模型
- `PI0_FAST`:自回归版PI0模型
class ModelType(enum.Enum): """Supported model types.""" PI0 = "pi0" PI0_FAST = "pi0_fast"接下来是 图像输入配置,定义了模型期望的图像输入的键名。这表明模型设计为同时接收三个视角的图像:
- 一个基础视图(机器人环境的全局视图)
- 左手腕视图(来自左手腕摄像头)
- 右手腕视图(来自右手腕摄像头)
# The model always expects these images IMAGE_KEYS = ( "base_0_rgb", "left_wrist_0_rgb", "right_wrist_0_rgb", )再其次,是图像分辨率设置——定义了模型处理图像的标准分辨率为224×224像素
# This may need change if we release a small model. IMAGE_RESOLUTION = (224, 224)
1.1.2 `Observation` 类与Actions类型的详解
`Observation` 类是 OpenPI 框架中的一个核心数据结构,用于存储和管理模型的输入数据
首先,它包含了机器人感知系统收集的所有必要信息:
- 图像数据 (`images`)
class Observation(Generic[ArrayT]): """Holds observations, i.e., inputs to the model. See `Observation.from_dict` to see the expected dictionary form. This is the format that should be produced by the data transforms. """ # Images, in [-1, 1] float32. images: dict[str, at.Float[ArrayT, "*b h w c"]]类型:`dict[str, at.Float[ArrayT, "*b h w c"]]用途:存储多个摄像头视角的图像数据
格式:浮点数数组,范围在 [-1, 1] 之间
维度:`*b` 表示任意批量维度,`h` 和 `w` 是图像高度和宽度,`c` 是颜色通道数
- 图像掩码 (`image_masks`)
# Image masks, with same keys as images. image_masks: dict[str, at.Bool[ArrayT, "*b"]]类型:`dict[str, at.Bool[ArrayT, "*b"]]`用途:标记对应的图像是否有效
格式:布尔值数组
维度:与图像批量维度相同
- 机器人状态 (`state`)
# Low-dimensional robot state. state: at.Float[ArrayT, "*b s"]类型:`at.Float[ArrayT, "*b s"]`用途:存储低维度的机器人状态向量
维度:`*b` 表示批量维度,`s` 表示状态向量维度
- 语言提示相关字段
`tokenized_prompt`:已经tokenized的语言提示
# Tokenized prompt. tokenized_prompt: at.Int[ArrayT, "*b l"] | None = None`tokenized_prompt_mask`:语言提示的掩码# Tokenized prompt mask. tokenized_prompt_mask: at.Bool[ArrayT, "*b l"] | None = None当然了,两者都是可选字段(可以为 `None`) - PI0-FAST 模型特有字段
`token_ar_mask`:自回归模型的标记掩码
# Token auto-regressive mask (for FAST autoregressive model). token_ar_mask: at.Int[ArrayT, "*b l"] | None = None`token_loss_mask`:损失计算的标记掩码# Token loss mask (for FAST autoregressive model). token_loss_mask: at.Bool[ArrayT, "*b l"] | None = None
接下来,定义了`from_dict` 方法,用于从非结构化的字典数据创建 `Observation` 对象:
- 数据验证:确保 `tokenized_prompt` 和 `tokenized_prompt_mask` 要么同时存在,要么同时不存在
def from_dict(cls, data: at.PyTree[ArrayT]) -> "Observation[ArrayT]": """This method defines the mapping between unstructured data (i.e., nested dict) to the structured Observation format.""" # Ensure that tokenized_prompt and tokenized_prompt_mask are provided together. if ("tokenized_prompt" in data) != ("tokenized_prompt_mask" in data): raise ValueError("tokenized_prompt and tokenized_prompt_mask must be provided together.") - 图像格式转换:如果输入图像是 `uint8` 格式(0-255 范围),自动转换为 `float32` 格式(范围 [-1, 1])
# If images are uint8, convert them to [-1, 1] float32. for key in data["image"]: if data["image"][key].dtype == np.uint8: data["image"][key] = data["image"][key].astype(np.float32) / 255.0 * 2.0 - 1.0 - 结构化数据创建:从字典数据创建结构化的 `Observation` 对象
return cls( images=data["image"], image_masks=data["image_mask"], state=data["state"], tokenized_prompt=data.get("tokenized_prompt"), tokenized_prompt_mask=data.get("tokenized_prompt_mask"), token_ar_mask=data.get("token_ar_mask"), token_loss_mask=data.get("token_loss_mask"), )
再接下来,又定义了`to_dict` 方法,将 `Observation` 对象转换回非结构化的字典格式:
- 使用 `dataclasses.asdict()` 将数据类转换为字典
def to_dict(self) -> at.PyTree[ArrayT]: """Convert the Observation to a nested dict.""" result = dataclasses.asdict(self) - 重命名字段以符合原始数据格式约定(`images` → `image`,`image_masks` → `image_mask`)
result["image"] = result.pop("images") result["image_mask"] = result.pop("image_masks") return result
最后,在类外定义了 `Actions` 类型,用于表示模型的输出动作:
# Defines the format of the actions. This field is included as "actions" inside the dictionary # produced by the data transforms. Actions = at.Float[ArrayT, "*b ah ad"]
- 类型:`at.Float[ArrayT, "*b ah ad"]`
- 维度:`*b` 表示批量维度,`ah` 表示动作时间步长,`ad` 表示每个动作的维度
一朋友在我组建的『七月具身:π0复现微调交流群』问了个比较细节的问题,即
我想采集自己的数据来微调这个openpi,然后在采自己的数据时,我的action到底应该采什么(如果采当前帧末端位姿的话,和state有什么区别,只是差个fk而已,不是冗余了么)
真正送到模型训练的时候,action又是什么,有大佬可以解决一下吗
根据OpenPI的代码结构,state和action在robotics任务中具有不同的含义:
State (状态),代表机器人当前的状态信息,包括:
- 机器人各关节的角度/位置
- 末端执行器(end-effector)的位置和方向
- 可能还包括物体的状态、环境信息等
如果只采集末端位姿,确实与状态信息存在冗余,只是差一步FK(正向运动学)计算。实际上,有效的Action (动作)代表机器人应该执行的下一步控制命令——通常是从当前状态到下一个目标状态的转换,可能是:
- 关节控制
关节角度的增量变化(delta)
- 相对位移/速度
末端位置到目标位置(target position)的增量变化,和方向
- 控制信号
直接发送给执行器的命令,或力矩
1.1.3 preprocess_observation
1.1.4 BaseModelConfig(abc.ABC)
1.1.5 class BaseModel(nnx.Module, abc.ABC)
1.1.6 restore_params
// 待更
1.2 models/pi0.py的实现
Pi0是一个多模态扩散模型:继承自`BaseModel`,使用SigLIP处理视觉输入、使用Gemma处理语言输入,实现了基于扩散的动作生成系统,且包含`compute_loss`和`sample_actions`方法的实现
总之,Pi0结合了多模态输入(图像和文本)来生成机器人动作序列。下面是对代码的详细解析:
1.2.1 make_attn_mask:注意力掩码生成函数
这个函数生成transformer中使用的注意力掩码,控制 token 之间的注意力流动方式
def make_attn_mask(input_mask, mask_ar): """ 从big_vision项目改编的注意力掩码生成函数 Token可以关注那些累积mask_ar小于等于自己的有效输入token。 这样`mask_ar` bool[?B, N]可用于设置几种类型的注意力,例如: [[1 1 1 1 1 1]]: 纯因果注意力。 [[0 0 0 1 1 1]]: 前缀语言模型注意力。前3个token之间可以互相关注, 后3个token有因果注意力。第一个条目也可以是1,不改变行为。 [[1 0 1 0 1 0 0 1 0 0]]: 4个块之间的因果注意力。一个块的token可以 关注所有之前的块和同一块内的所有token。 参数: input_mask: bool[B, N] 如果是输入的一部分则为true,如果是填充则为false mask_ar: bool[?B, N] 如果前面的token不能依赖于它则为true, 如果它共享与前一个token相同的注意力掩码则为false """ # 将mask_ar广播到与input_mask相同的形状 mask_ar = jnp.broadcast_to(mask_ar, input_mask.shape) # 计算mask_ar在序列维度上的累积和 cumsum = jnp.cumsum(mask_ar, axis=1) # 创建注意力掩码:当目标位置的累积值 Tuple[Type[_model.Observation], Type[_model.Actions]]- 其支持多种输入,比如
视觉输入(三个不同视角的RGB图像)、语言输入(分词后的文本prompt)、状态输入(当前机器人状态)
- 输出上
则是一个时序动作序列(包含50个连续的动作向量,每个动作向量有32个维度,可能对应关节角度或其他控制信号)
具体而言该函数进行如下4个操作
一、创建图像规格
image_spec = jax.ShapeDtypeStruct([batch_size, *_model.IMAGE_RESOLUTION, 3], jnp.float32)
其中的
- `[batch_size, *_model.IMAGE_RESOLUTION, 3]` 定义了图像张量的形状:比如
批次大小
- `jnp.float32` 指定了数据类型为 32 位浮点数
二、创建图像掩码规格
image_mask_spec = jax.ShapeDtypeStruct([batch_size], jnp.bool_)
其定义了图像掩码规格,每个批次中的每个图像都有一个布尔值,这个掩码用于指示哪些图像是有效的(`True`)或无效的(`False`)
三、创建观察规格:包含视觉输入、机器人状态、指令输入
`at.disable_typechecking()` 临时禁用类型检查,可能是因为这里创建的是类型规格而不是实际的数据,且观察规格包含多个组件:
- 多视角图像
base_0_rgb: 机器人底座/身体视角的RGB图像
left_wrist_0_rgb: 左手腕视角的RGB图像
right_wrist_0_rgb: 右手腕视角的RGB图像
with at.disable_typechecking(): observation_spec = _model.Observation( images={ "base_0_rgb": image_spec, "left_wrist_0_rgb": image_spec, "right_wrist_0_rgb": image_spec, }, - 图像掩码
对应每个视角图像的有效性掩码
- 机器人状态:
形状为 `[batch_size, self.action_dim]` 的浮点数张量,其中的`self.action_dim` 默认为32,表示状态向量的维度
state=jax.ShapeDtypeStruct([batch_size, self.action_dim], jnp.float32),
- 分词后的文本prompt
形状为 `[batch_size, self.max_token_len]` 的整数张量
`self.max_token_len` 默认为48,表示最大token数量
数据类型为 `jnp.int32`,表示token ID
- 提示掩码
与分词提示相同形状的布尔张量,用于指示哪些位置有有效的token
state=jax.ShapeDtypeStruct([batch_size, self.action_dim], jnp.float32), tokenized_prompt=jax.ShapeDtypeStruct([batch_size, self.max_token_len], jnp.int32), tokenized_prompt_mask=jax.ShapeDtypeStruct([batch_size, self.max_token_len], bool), )
四、创建动作规格
action_spec = jax.ShapeDtypeStruct([batch_size, self.action_horizon, self.action_dim], jnp.float32)
其定义了动作数据的形状和类型:
- `batch_size`: 批次大小
- `self.action_horizon`: 动作序列长度,默认为50
- `self.action_dim`: 每个动作的维度,默认为32
- `jnp.float32` 指定了数据类型为32位浮点数
然后返回
return observation_spec, action_spec
1.2.3.3 get_freeze_filter:参数冻结器,包含谁则相当于谁被冻结/过滤
此外,该配置类还实现了get_freeze_filter这个函数,作用是如果选择LoRA微调(冻结原始预训练模型的参数,只更新新添加的低秩适应层参数),则需要对模型中的某些参数做冻结
三种可能的情况:
- 只对 PaLI-Gemma 使用 LoRA
意味着只冻结 Gemma 原始参数,然后排除动作专家原始参数,微调Gemma原始参数之外的少量LoRA部分
注意
「关于什么是LoRA,详见此文《LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含对模型量化的解释)》的第4部分」
毕竟lora微调的本质是 原始参数冻结,而是微调「两个可以近似原矩阵的两个小矩阵」参数
- 只对动作专家使用 LoRA
意味着只冻结动作专家参数,微调动作专家原始参数之外的少量LoRA部分
- 对两者都使用 LoRA
意味着冻结两者的基础参数,微调两者原始参数之外的少量LoRA部分
如此,可以选择性地微调模型的特定部分(语言部分或动作预测部分)
具体而言,该get_freeze_filter分为4大阶段
第一阶段,定义函数本身、初始化变量,并创建参数过滤器
- 首先,定义函数
def get_freeze_filter(self) -> nnx.filterlib.Filter: """返回基于模型配置的冻结过滤器""" - 其次,初始化变量
filters = [] # 初始化过滤器列表 has_lora = False # 初始化LoRA标志 - 接着,创建参数过滤器
# 匹配所有LLM参数的正则表达式,用于选择 Gemma 语言模型的参数 gemma_params_filter = nnx_utils.PathRegex(".*llm.*") # 匹配动作专家参数的正则表达式 action_expert_params_filter = nnx_utils.PathRegex(".*llm.*_1.*")第二阶段,分情况添加LoRA权重
即要么只对语言模型使用LoRA(意味着不对动作专家使用LoRA),要么只对动作专家使用LoRA
- 即,接下来是对PaLI-Gemma变体的处理
如果只对PaLI-Gemma使用LoRA,则
# 如果只针对PaLI-Gemma使用LoRA if "lora" in self.paligemma_variant: # 过滤器列表添加Gemma的原始参数 filters.append( gemma_params_filter, )if "lora" not in self.action_expert_variant: # 因为只冻结Gemma参数,故过滤器列表不添加动作专家expert的原始参数 filters.append( nnx.Not(action_expert_params_filter), ) has_lora = True - 再下来是对动作专家变体的处理,如果对action_expert_variant使用LoRA,则过滤器列表添加动作专家expert的原始参数,而微调动作专家原始参数之外的少量LoRA部分
elif "lora" in self.action_expert_variant: # 如果动作专家使用LoRA,则过滤器列表添加动作专家expert的原始参数 filters.append( action_expert_params_filter, ) has_lora = True第三阶段,针对需要LoRA微调的少量参数处理,以及如果没有需要LoRA微调时的处理
- 如果有需要被LoRA微调的部分,则过滤器列表里不添加原始参数之外的LoRA相关参数(代表着不被过滤)
if has_lora: # If any lora is used, exclude all lora params. filters.append( nnx.Not(nnx_utils.PathRegex(".*lora.*")), ) - 如果没有被冻结/过滤的参数,则什么都不需要处理——即默认微调所有参数
if not filters: return nnx.Nothing第四阶段,返回所有需要被冻结/被过滤的参数,这毕竟是get_freeze_filter函数本身定义所追求的目标
return nnx.All(*filters)
值得注意的是,也是我之前看到这里思考过的一个问题,即在训练 π0 的动作预测能力时
- 默认会同时调整 VLM 和动作专家的参数
- 如果需要只调整动作专家的参数,可以通过修改 `get_freeze_filter` 方法来冻结 VLM 的参数
1.2.4 class Pi0:含特征嵌入(embed_prefix/embed_suffix)、损失函数(训练去噪的准确性)、推理(去噪生成动作)
核心模型类,继承自 `_model.BaseModel`,实现了:
- 多模态输入处理
处理多视角图像(基础视角、左手腕视角、右手腕视角)
处理文本提示(如指令)
处理机器人当前状态
- 扩散过程
训练时:将干净动作添加噪声,让模型学习去噪
推理时:从纯噪声开始,逐步降噪生成动作序列
- 注意力机制
使用精心设计的注意力掩码控制信息流动
前缀(图像和文本)内部使用全注意力
后缀(状态和动作)使用特殊的注意力模式
1.2.4.1 初始化方法 `__init__`
class Pi0(_model.BaseModel): def __init__(self, config: Pi0Config, rngs: nnx.Rngs): # 初始化基类 super().__init__(config.action_dim, config.action_horizon, config.max_token_len) # 获取PaLI-Gemma和动作专家配置 paligemma_config = _gemma.get_config(config.paligemma_variant) action_expert_config = _gemma.get_config(config.action_expert_variant)其组合了多个核心组件:
一个是PaLI-Gemma 模型:结合了 Gemma 语言模型和 SigLIP 视觉模型

- 先是对语言模型的初始化
# 创建并初始化语言模型 # TODO: 用NNX重写Gemma,目前使用桥接 llm = nnx_bridge.ToNNX( _gemma.Module( configs=[paligemma_config, action_expert_config], # 配置两个Gemma模型 embed_dtype=config.dtype, # 设置嵌入数据类型 ) ) llm.lazy_init(rngs=rngs, method="init") # 延迟初始化LLM - 然后是对视觉模型的初始化
# 创建并初始化图像模型 img = nnx_bridge.ToNNX( _siglip.Module( num_classes=paligemma_config.width, # 设置图像特征维度与语言模型宽度相匹配 variant="So400m/14", # 使用400M参数SigLIP模型 pool_type="none", # 不使用池化,保留所有图像token scan=True, # 启用扫描优化 dtype_mm=config.dtype, # 设置矩阵乘法数据类型 ) ) # 使用假观察中的图像初始化图像模型 img.lazy_init(next(iter(config.fake_obs().images.values())), train=False, rngs=rngs) - 最后,把语言模型和视觉模型组合成PaLI-Gemma多模态模型
# 组合LLM和图像模型为PaLI-Gemma多模态模型 self.PaliGemma = nnx.Dict(llm=llm, img=img)
另一个是线性投影层:用于
- 状态投影
# 状态投影层:将机器人状态投影到模型维度 self.state_proj = nnx.Linear(config.action_dim, action_expert_config.width, rngs=rngs) - 动作投影
# 动作输入投影层:将动作投影到模型维度 self.action_in_proj = nnx.Linear(config.action_dim, action_expert_config.width, rngs=rngs) - 时间-动作混合等
# 动作-时间MLP输入层:将连接的动作和时间特征投影到模型维度 self.action_time_mlp_in = nnx.Linear(2 * action_expert_config.width, action_expert_config.width, rngs=rngs) # 动作-时间MLP输出层 self.action_time_mlp_out = nnx.Linear(action_expert_config.width, action_expert_config.width, rngs=rngs) # 动作输出投影层:将模型输出投影回动作维度 self.action_out_proj = nnx.Linear(action_expert_config.width, config.action_dim, rngs=rngs)
1.2.4.2 特征嵌入方法:embed_prefix(图像和文本输入)、embed_suffix(状态和动作信息)
- `embed_prefix`:处理图像和文本输入(图像通过SigLip模型编码,文本通过Gemma LLM编码),创建前缀 token,皆为双向注意力,用ar_mask = false表示
- `embed_suffix`:处理机器人状态信息
、噪声化的动作信息
(状态和噪声动作经过线性投影和MLP处理),创建后缀 token
其中
首先,对于前者embed_prefix
def embed_prefix( self, obs: _model.Observation ) -> Tuple[at.Float[at.Array, Any], at.Bool[at.Array, Any], at.Bool[at.Array, Any]]: """嵌入前缀部分(图像和文本)""" input_mask = [] # 初始化输入掩码列表 ar_mask = [] # 初始化自回归掩码列表 tokens = [] # 初始化token列表其工作流程为
- 图像处理:说白了,就是把图像token化
使用SigLip视觉模型处理每个图像,生成图像tokens序列
# 嵌入图像 for name in obs.images: # 通过图像模型获取图像token image_tokens, _ = self.PaliGemma.img(obs.images[name], train=False) tokens.append(image_tokens) # 添加图像token - 图像掩码扩展
将图像掩码扩展到与图像tokens相同的序列长度,使用einops.repeat进行形状变换,这些掩码会指示哪些图像是有效的,而哪些是填充的
# 重复图像掩码以匹配token维度 input_mask.append( einops.repeat( obs.image_masks[name], "b -> b s", # 调整形状:批次维度保持不变,添加序列维度 s=image_tokens.shape[1], # 序列长度等于图像token数 ) ) - 自回归掩码设置
设置图像tokens之间的注意力为双向(False表示双向注意力),原因在于图像内容通常是非时序性的数据
# 图像token之间互相关注(非自回归) ar_mask += [False] * image_tokens.shape[1] - 文本处理
使用LLM模型对文本输入tokenized_inputs进行嵌入
# 添加语言(即分词后的输入) if obs.tokenized_prompt is not None: # 通过语言模型嵌入分词后的提示 tokenized_inputs = self.PaliGemma.llm(obs.tokenized_prompt, method="embed") tokens.append(tokenized_inputs) # 添加文本token input_mask.append(obs.tokenized_prompt_mask) # 添加提示掩码且同样设置为双向注意力,相当于语言token可以关注图像token,图像token反过来亦可关注语言token,最终实现多模态融合# 图像和语言输入之间完全关注(非自回归) ar_mask += [False] * tokenized_inputs.shape[1] - 最后,连接所有token和掩码,其中包含了
# 连接所有token和掩码 tokens = jnp.concatenate(tokens, axis=1) # 在序列维度上连接token input_mask = jnp.concatenate(input_mask, axis=1) # 在序列维度上连接输入掩码 ar_mask = jnp.array(ar_mask) # 转换自回归掩码为数组 return tokens, input_mask, ar_mask # 返回token、输入掩码和自回归掩码
顺便,再回顾下此图
其次,对于后者embed_suffix
定义如下,其参数包括obs(一般包含图像和机器人状态)、noisy_actions、timestep
def embed_suffix( self, obs: _model.Observation, noisy_actions: _model.Actions, timestep: at.Float[at.Array, Any] ) -> Tuple[at.Float[at.Array, Any], at.Bool[at.Array, Any], at.Bool[at.Array, Any]]: """嵌入后缀部分(状态和动作)""" input_mask = [] # 初始化输入掩码列表 ar_mask = [] # 初始化自回归掩码列表 tokens = [] # 初始化token列表其工作流程为
- 状态处理
将状态信息投影到embedding空间
# 添加单个状态token state_token = self.state_proj(obs.state)[:, None, :] # 投影状态并添加序列维度 tokens.append(state_token) # 添加状态token # 添加状态掩码(全为1),表示这个状态token是有效的 input_mask.append(jnp.ones((obs.state.shape[0], 1), dtype=jnp.bool_))并设置为单向注意力(True),表明图像和语言输入不能关注状态信息,因为image/language do not attend to state or actions# 图像/语言输入不关注状态或动作(自回归) ar_mask += [True] - 时间步嵌入,使用正弦-余弦位置编码生成时间步嵌入
# 使用正弦余弦位置编码嵌入时间步,敏感度范围为[0, 1] time_emb = posemb_sincos(timestep, self.action_in_proj.out_features, min_period=4e-3, max_period=4.0) - 动作和时间信息融合,比如通过action_time_tokens连接:「带噪声的动作」和「时间token」
# 混合时间步 + 动作信息,使用MLP action_tokens = self.action_in_proj(noisy_actions) # 投影带噪声的动作 # 重复时间嵌入以匹配动作序列长度 time_tokens = einops.repeat(time_emb, "b emb -> b s emb", s=self.action_horizon) # 连接动作和时间token action_time_tokens = jnp.concatenate([action_tokens, time_tokens], axis=-1) - MLP处理
使用两层MLP和swish激活函数对「动作和时间的组合表示」进行非线性变换,以进一步融合:(噪声)动作和时间信息
# 通过MLP处理 action_time_tokens = self.action_time_mlp_in(action_time_tokens) # 输入层 action_time_tokens = nnx.swish(action_time_tokens) # Swish激活函数 action_time_tokens = self.action_time_mlp_out(action_time_tokens) # 输出层 - 注意力掩码设置
第一个动作token设置为单向注意力「上面说过了的,单向注意力,用ar_mask = true表示」,其余动作tokens之间设置为双向注意力
# 添加动作时间token tokens.append(action_time_tokens) # 添加掩码(全为1),表示所有动作token都是有效的 input_mask.append(jnp.ones(action_time_tokens.shape[:2], dtype=jnp.bool_)) # 图像/语言/状态输入不关注动作token(动作第一个是自回归的——单向,其余不是——双向) ar_mask += [True] + ([False] * (self.action_horizon - 1)) - 最后连接所有token和掩码
# 连接所有token和掩码 tokens = jnp.concatenate(tokens, axis=1) # 在序列维度上连接token input_mask = jnp.concatenate(input_mask, axis=1) # 在序列维度上连接输入掩码 ar_mask = jnp.array(ar_mask) # 转换自回归掩码为数组 return tokens, input_mask, ar_mask # 返回token、输入掩码和自回归掩码
1.2.4.3 损失函数compute_loss:训练模型去噪的准确率
总的来讲
- 训练的时候,对其中的「原始动作action」数据加噪,最后去预测所添加的真实噪声
,预测噪声的结果为
,然后计算预测噪声
也就是说,训练时的本质 其实是为了让模型具备生成真正想要动作的能力,以确保在推理时,能得到真正想要动作的能力
那可能有同学疑问了,既然通过对原始动作
加噪
减掉预测噪声
其实我之前在此文《图像生成发展起源:从VAE、扩散模型DDPM、DDIM到DETR、ViT、Swin transformer》中的「2.1.1 从扩散模型概念的提出到DDPM(含U-Net网络的简介)、DDIM」已经讲了,原因在于
1 对噪声的预测,比对动作的预测更容易,一者 预测噪声收敛更稳定,二者 噪声通常是标准化的,比如高斯噪声的均值为0 方差为1,使得模型预测噪声时不需要适应不同尺度的输出
2
- 如此,便可以在推理的时候,针对一个随机生成的纯噪声,基于observation(包含图像和机器人状态),逐步去噪生成机器人的动作序列
具体而言,compute_loss实现了扩散模型的训练损失计算
- 对输入观察进行预处理,其中
preprocess_rng用于观察预处理(比如图像增强等)
noise_rng用于生成噪声
time_rng用于从beta分布采样时间步
def compute_loss( self, rng: at.KeyArrayLike, observation: _model.Observation, actions: _model.Actions, *, train: bool = False ) -> at.Float[at.Array, Any]: """计算扩散模型的损失函数""" # 分割随机数生成器为三部分,用于不同的随机操作 preprocess_rng, noise_rng, time_rng = jax.random.split(rng, 3) - 生成随机噪声并采样时间点 t
# 获取动作的批次形状 batch_shape = actions.shape[:-2] # 生成与动作相同形状的高斯噪声 noise = jax.random.normal(noise_rng, actions.shape) # 从Beta分布采样时间点,范围为[0.001, 1],Beta(1.5, 1)偏向较低的值 time = jax.random.beta(time_rng, 1.5, 1, batch_shape) * 0.999 + 0.001 # 扩展时间维度以匹配动作形状 time_expanded = time[..., None, None] -
创建带噪动作序列 x_t,相当于x_t是噪声化的动作,随着时间从0到1,原始动作
逐渐添加真实噪声
而
故所添加的噪声
# 创建带噪声的动作:t * noise + (1-t) * actions x_t = time_expanded * noise + (1 - time_expanded) * actions # 计算真实噪声减去动作的差异,这是模型需要预测的目标 u_t = noise - actions - 嵌入前缀和后缀
# 一次性前向传递前缀+后缀 # 嵌入前缀(图像和文本) prefix_tokens, prefix_mask, prefix_ar_mask = self.embed_prefix(observation) # 嵌入后缀(状态和带噪声的动作) suffix_tokens, suffix_mask, suffix_ar_mask = self.embed_suffix(observation, x_t, time) - 构建注意力掩码和位置编码
根据下图
可得
# 连接掩码:通过链接前缀和后缀的掩码,从而创建完整的输入掩码 input_mask = jnp.concatenate([prefix_mask, suffix_mask], axis=1) ar_mask = jnp.concatenate([prefix_ar_mask, suffix_ar_mask], axis=0) # 创建注意力掩码make_attn_mask,从而控制不同token之间的可见性 attn_mask = make_attn_mask(input_mask, ar_mask) # 计算位置编码 positions = jnp.cumsum(input_mask, axis=1) - 1 - 模型前向传播,即调用PaliGemma进行推理,处理前缀和后缀token
当然了,输出中我们只关注与后缀相关的部分,因为其中包含了我们想要的动作预测的部分
# 通过PaLI-Gemma模型处理token _, suffix_out = self.PaliGemma.llm( [prefix_tokens, suffix_tokens], mask=attn_mask, positions=positions ) - 预测噪声
# 将模型输出投影回动作空间 v_t = self.action_out_proj(suffix_out[:, -self.action_horizon :]) - 计算预测噪声
# 返回预测噪声和真实噪声之间的均方误差 return jnp.mean(jnp.square(v_t - u_t), axis=-1)
注解 LeRobotDataset:训练数据集的来源(即训练数据集长什么样)
不知道有没有同学会疑问这段代码里面的数据集 是从哪来的,比如原始动作action 从哪来的,我暂且不管有没有疑惑,假设有人有此疑惑,故我来解释下数据集的来源途径
π0主要使用两种数据集:
- FakeDataset - 生成随机数据用于测试
- LeRobotDataset - 真实的机器人操作数据
LeRobotDataset 是一个专为机器人学习设计的数据集格式,来自`lerobot.common.datasets.lerobot_dataset`模块。这个数据集包含了训练π0模型所需的观察数据和动作数据,其包含
- Aloha数据集,侧重双臂协同的精确操作,适合特定任务的模仿学习,比如这个是打开笔帽的任务
- Libero数据集,注重多样化任务和泛化能力,适合语言引导的通用机器人控制

LeRobotDataset 数据通常包含以下几个关键部分:
- 观察数据 (Observation)
图像数据:来自不同摄像头的图像
"observation.images.cam_high" "observation.images.cam_low" "observation.images.cam_left_wrist" "observation.images.cam_right_wrist"
状态数据:机器人的关节角度等状态信息"observation.state"
- 动作数据 (Actions)
动作序列:每个时间步的机器人动作指令
"action"
时间戳信息:通过`delta_timestamps`定义的时间间隔 - 任务信息
任务描述:可用于生成提示(prompt)
元数据:包括帧率(fps)等信息
数据集示例
- ALOHA数据集
physical-intelligence/aloha_pen_uncap_diverse
{ "observation": { "images": { "cam_high": np.ndarray(shape=(3, 224, 224), dtype=np.uint8), "cam_left_wrist": np.ndarray(shape=(3, 224, 224), dtype=np.uint8), "cam_right_wrist": np.ndarray(shape=(3, 224, 224), dtype=np.uint8) }, "state": np.ndarray(shape=(14,), dtype=np.float32) }, "action": np.ndarray(shape=(14,), dtype=np.float32), "prompt": "uncap the pen" }其中,14维机器人状态向量的含义[ # 左臂关节角度 (6维) left_shoulder_pitch, left_shoulder_roll, left_shoulder_yaw, left_elbow_pitch, left_elbow_roll, left_wrist_pitch, # 左手爪状态 (1维) left_gripper, # 右臂关节角度 (6维) right_shoulder_pitch, right_shoulder_roll, right_shoulder_yaw, right_elbow_pitch, right_elbow_roll, right_wrist_pitch, # 右手爪状态 (1维) right_gripper ] - 一个LeRobotDataset的样本可能看起来像这样
比如Libero数据集:physical-intelligence/libero
{ "observation": { "images": { # 高视角RGB图像,224x224x3 "cam_high": np.ndarray(shape=(224, 224, 3), dtype=np.uint8), # 低视角RGB图像 "cam_low": np.ndarray(shape=(224, 224, 3), dtype=np.uint8), # 左手腕视角RGB图像 "cam_left_wrist": np.ndarray(shape=(224, 224, 3), dtype=np.uint8), # 右手腕视角RGB图像 "cam_right_wrist": np.ndarray(shape=(224, 224, 3), dtype=np.uint8) }, # 机器人状态向量,包含关节角度等信息 "state": np.ndarray(shape=(14,), dtype=np.float32), }, # 动作序列,50个时间步,每步14维动作向量 "actions": np.ndarray(shape=(50, 14), dtype=np.float32), # 任务描述文本 "prompt": "fold the towel" }再比如{ "observation": { "images": { "cam_high": , "cam_left_wrist": , "cam_right_wrist": }, "state": [0.1, -0.5, 0.3, ...], # 14维机器人关节状态 }, "actions": [ [0.1, -0.2, 0.3, ...], # t=0时刻的动作 [0.15, -0.25, 0.35, ...], # t=1时刻的动作 ... # 共50个时间步 ], "prompt": "pick up the blue cube and place it in the red bowl" }
真实数据来自`lerobot_dataset`模块,通过以下代码加载——下文「2.2.2 create_dataset:创建适合训练的数据集」还会详解:
dataset_meta = lerobot_dataset.LeRobotDatasetMetadata(repo_id, local_files_only=data_config.local_files_only) dataset = lerobot_dataset.LeRobotDataset( data_config.repo_id, delta_timestamps={ key: [t / dataset_meta.fps for t in range(model_config.action_horizon)] for key in data_config.action_sequence_keys }, local_files_only=data_config.local_files_only, )这里的`repo_id`指向一个特定的数据仓库,是Hugging Face上的数据集或其他存储位置。数据集通过配置文件中的参数指定,例如我们在`config.py`中看到的配置——下文「2.1 配置系统 (config.py)」还会详解:
# Inference Aloha configs. # TrainConfig( name="pi0_aloha", model=pi0.Pi0Config(), data=LeRobotAlohaDataConfig( assets=AssetsConfig(asset_id="trossen"), ), ),以下是对数据流程总结
- 从LeRobot数据集加载原始数据,包含观察(observation)和动作(action)
- 通过数据转换管道处理数据,包括重打包和归一化
- 在训练期间,向原始动作添加噪声
- 模型学习预测添加的噪声,而不是直接预测原始动作
- 在推理时,模型从纯噪声开始,通过迭代去噪过程生成动作序列
这种基于扩散的方法允许π0从噪声中逐步精炼动作,最终生成平滑且符合任务要求的机器人动作序列
1.2.4.4 推理函数 `sample_actions`:基于扩散模型逆向采样(即去噪),生成机器人动作序列
sample_actions函数是Pi0模型的核心推理方法,实现了基于扩散模型的逆向采样过程——说白了 就是去噪,它从纯噪声开始,通过多步骤逐渐"去噪",最终生成符合条件分布的机器人动作序列
函数的核心是一个基于while循环的迭代过程,每一步都使用训练好的神经网络预测从当前噪声化动作到目标动作的方向——从噪声到目标的方向 代表速度场,毕竟咱们去噪的方向得对 不然就去歪了
总之,这个函数将观察数据(图像和可选的文本提示)转换为具体的动作轨迹,是模型部署时的主要接口,简言之,其包含以下流程
- 首先从纯噪声开始 (t=1)
- 通过重复迭代降噪步骤,逐步将噪声转化为有意义的动作序列
- 使用KV缓存优化推理速度
- 实现了一个迭代降噪过程
- 最终返回完全降噪后的动作序列 x_0
具体而言,包含如下步骤
第一,初始化
首先,函数对输入观察数据进行预处理,包括标准化图像大小等操作
def sample_actions( self, rng: at.KeyArrayLike, # 随机数生成器 observation: _model.Observation, # 观察输入,包含图像和文本等 *, num_steps: int = 10, # 扩散过程的步数,默认为10步 ) -> _model.Actions: # 返回生成的动作序列 # 对观察数据进行预处理,不进行训练时的数据增强 observation = _model.preprocess_observation(None, observation, train=False)然后设置时间步长`dt`为负值(因为是从t=1向t=0方向演化),生成初始随机噪声作为起点,且时间上约定:"t=1是噪声,t=0是目标分布",这是扩散文献中常见的约定,不过与Pi0论文相反
# 注意:这里使用扩散模型文献中更常见的约定,t=1是噪声,t=0是目标分布 # 这与pi0论文相反 dt = -1.0 / num_steps # 计算时间步长,从1到0 batch_size = observation.state.shape[0] # 获取批次大小 # 生成初始噪声,形状为[批次大小, 动作序列长度, 动作维度] noise = jax.random.normal(rng, (batch_size, self.action_horizon, self.action_dim))第二,Key-Value缓存初始化(预计算并存储前缀表示,减少冗余计算)
处理观察数据,得到前缀表示和相关掩码
# 首先通过前缀的前向传递填充KV缓存 # 获取前缀的token表示和掩码 prefix_tokens, prefix_mask, prefix_ar_mask = self.embed_prefix(observation) # 创建前缀的注意力掩码 prefix_attn_mask = make_attn_mask(prefix_mask, prefix_ar_mask) # 计算位置编码 positions = jnp.cumsum(prefix_mask, axis=1) - 1然后使用PaliGemma语言模型进行一次前向传递,生成Key-Value缓存(`kv_cache`)——这是一个性能优化:因为前缀部分在整个采样过程中保持不变,预先计算并缓存它们的表示可以避免重复计算
# 进行前向传递,获取KV缓存 _, kv_cache = self.PaliGemma.llm([prefix_tokens, None], mask=prefix_attn_mask, positions=positions)第三,通过step函数构建注意力掩码系统并让PaliGemma做推理
核心迭代通过 `jax.lax.while_loop` 实现
根据源码

可知,该class Pi0(_model.BaseModel)类的最后两行是
# 使用while循环进行迭代采样,从t=1(噪声)开始 x_0, _ = jax.lax.while_loop(cond, step, (noise, 1.0)) # 返回最终的去噪结果(生成的动作序列) return x_0具体而言,包含 `step` 函数和 `cond` 函数,其中,`step` 函数是每次迭代的核心
首先,step函数通过 `embed_suffix` 处理当前状态,包括状态信息嵌入、噪声化动作、时间步编码
def step(carry): """定义单步去噪函数""" x_t, time = carry # carry数组包含当前状态和时间 # 将时间广播到批次维度,并嵌入后缀(状态和动作) suffix_tokens, suffix_mask, suffix_ar_mask = self.embed_suffix( observation, x_t, jnp.broadcast_to(time, batch_size) )其次,构建复杂的注意力掩码系统,处理前缀-后缀之间的注意力关系——这个复杂的掩码系统允许后缀token(包括状态和动作)有选择地关注前缀token(图像和文本),实现了条件生成,具体而言,其构建了三层注意力掩码:
- 后缀内部注意力掩码,控制后缀token(状态和动作)之间的注意力关系
# 创建后缀内部的注意力掩码,形状为(批次, 后缀长度, 后缀长度) suffix_attn_mask = make_attn_mask(suffix_mask, suffix_ar_mask)- 前缀-后缀注意力掩码,控制后缀token如何关注前缀token(图像和文本输入)
# 创建后缀对前缀的注意力掩码,形状为(批次, 后缀长度, 前缀长度) prefix_attn_mask = einops.repeat(prefix_mask, "b p -> b s p", s=suffix_tokens.shape[1])- 完整注意力掩码,将前两个掩码组合,形成完整的注意力控制机制
# 组合掩码,形状为(批次, 后缀长度, 前缀长度+后缀长度) # 控制后缀token(生成查询)如何关注完整序列(生成键和值) full_attn_mask = jnp.concatenate([prefix_attn_mask, suffix_attn_mask], axis=-1)当然了,过程中还做了形状检查,确保张量维度正确
# 验证掩码形状正确 assert full_attn_mask.shape == ( batch_size, suffix_tokens.shape[1], prefix_tokens.shape[1] + suffix_tokens.shape[1], )接着,计算位置编码,为后缀token计算其在完整序列中的位置,这对于Transformer模型理解序列顺序很重要
# 计算后缀token的位置编码 positions = jnp.sum(prefix_mask, axis=-1)[:, None] + jnp.cumsum(suffix_mask, axis=-1) - 1之后,模型推理,使用PaliGemma语言模型进行推理,利用缓存的前缀信息(`kv_cache`)提高效率
# 使用KV缓存进行高效的前向传递 (prefix_out, suffix_out), _ = self.PaliGemma.llm( [None, suffix_tokens], mask=full_attn_mask, positions=positions, kv_cache=kv_cache ) # 且确保前缀输出为None(因为使用了KV缓存) assert prefix_out is None第四,step函数中做最后的速度预测与动作更新(去噪)
在每一步中,模型预测速度场 `v_t`(从噪声到目标的方向),并通过类欧拉法更新动作表示——使用简单而有效的欧拉方法
进行轨迹采样
本质就是对
去噪,而
是时间步长——如上面说过的「时间步长`dt`为负值(因为是从t=1向t=0方向演化),生成初始随机噪声作为起点,且时间上约定:"t=1是噪声,t=0是目标分布"」
具体而言
- 一方面,提取模型输出并预测速度场`v_t`——相当于本质是通过PaliGemma模型预测去噪方向 `v_t`
# 预测噪声 v_t = self.action_out_proj(suffix_out[:, -self.action_horizon :])- 二方面,使用欧拉法更新动作状态和时间步
# 使用欧拉方法更新状态和时间 return x_t + dt * v_t, time + dt至于cond函数确定何时停止迭代,通过检查时间是否接近零(当然,要考虑浮点精读可能存在的误差)
def cond(carry): """定义循环终止条件""" x_t, time = carry # 考虑浮点误差,当时间接近0时停止 return time >= -dt / 21.3 语言模型实现:models/gemma.py
src/openpi/models/gemma.py实现了Gemma语言模型的核心组件,定义了RMSNorm、Embedder、Attention、FeedForward等模块,且提供了不同规模Gemma模型的配置(300M, 2B等)
// 待更
1.4 视觉模型实现:models/siglip.py
`siglip.py`: 实现了视觉编码器,基于Vision Transformer (ViT),定义了位置编码、注意力池化等组件,支持不同大小的模型变体
// 待更
1.5 tokenizer.py: 提供文本tokenization功能
这段代码实现了两个相关但功能不同的tokenizer类:`PaligemmaTokenizer` 和 `FASTTokenizer`
1.5.1 PaligemmaTokenizer 类:专门处理文本prompt
`PaligemmaTokenizer` 是一个相对简单的Tokenizer,专门处理文本prompt
第一方面,在初始化阶段
- `__init__` 方法接收一个 `max_len` 参数(默认为 48)来设定token序列的最大长度
# 初始化方法,设置最大token长度,默认为48 def __init__(self, max_len: int = 48): # 存储最大token长度 self._max_len = max_len - 接着,它调用 `download.maybe_download` 函数从 Google Cloud Storage 获取预训练的 PaliGemma 分词模型
# 下载PaliGemma分词器模型 path = download.maybe_download("gs://big_vision/paligemma_tokenizer.model", gs={"token": "anon"})这个下载机制设计得很智能:如果本地缓存中已存在该模型,则直接使用,避免重复下载;否则,会创建一个锁文件确保并发安全,并从 `gs://big_vision/paligemma_tokenizer.model` 下载模型文件。参数 `gs={"token": "anon"}` 表示使用匿名方式访问 GCS 存储桶 - 下载完成后,代码以二进制读取模式打开文件,并使用 SentencePiece 处理器加载模型
# 以二进制读取模式打开下载的模型文件 with path.open("rb") as f: # 初始化SentencePiece处理器 self._tokenizer = sentencepiece.SentencePieceProcessor(model_proto=f.read())
第二方面,`tokenize` 方法是处理文本输入的核心,它执行以下步骤:
- 文本清理:首先通过 `strip()` 去除首尾空白,然后将下划线替换为空格,并将换行符也替换为空格,确保输入文本格式一致
# 定义分词方法,输入为提示文本,返回tokens和mask def tokenize(self, prompt: str) -> tuple[np.ndarray, np.ndarray]: # 清理文本:移除首尾空格,将下划线和换行符替换为空格 cleaned_text = prompt.strip().replace("_", " ").replace("\n", " ") - Tokenizer:将清理后的文本送入 SentencePiece 编码器,设置 `add_bos=True` 添加句子开始token
# 单独将"\n"作为"答案开始"的token # 对清理后的文本编码,添加开始标记,并附加换行符的编码 tokens = self._tokenizer.encode(cleaned_text, add_bos=True) + self._tokenizer.encode("\n")特别的是,它还单独编码了一个换行符 `\n` 并将其附加到token序列末尾,作为"答案开始"的特殊token。这种设计允许模型明确区分提示和生成内容的边界 - 长度处理:根据实际编码后的token序列长度
# 获取token列表长度 tokens_len = len(tokens)代码采取两种策略:# 如果token长度小于最大长度 if tokens_len# 如果token长度大于或等于最大长度 else: # 如果token长度大于最大长度 if len(tokens) > self._max_len: # 记录警告日志 logging.warning( # 警告token长度超出最大长度,将进行截断 f"Token length ({len(tokens)}) exceeds max length ({self._max_len}), truncating. " # 建议如果频繁发生,增加模型配置中的最大token长度 "Consider increasing the `max_token_len` in your model config if this happens frequently." ) # 截断token列表,只保留前max_len个 tokens = tokens[: self._max_len] # 创建全True的mask列表,长度为max_len mask = [True] * self._max_len - 返回结果:最后,方法将token序列和掩码转换为 NumPy 数组并返回,便于后续的模型处理
# 将token列表和mask列表转换为numpy数组并返回 return np.asarray(tokens), np.asarray(mask)
1.5.2 FASTTokenizer 类
`FASTTokenizer` 是一个更复杂的Tokenizer,可同时处理文本和动作数据,详见此文《π0开源了且推出自回归版π0-FAST——打造高效Tokenizer:比扩散π0的训练速度快5倍但效果相当(含π0-FAST源码剖析)》
首先是初始化过程
- 同样下载 PaliGemma Tokenizer模型
# 定义FAST分词器类 class FASTTokenizer: # 初始化方法,设置最大长度和FAST分词器路径 def __init__(self, max_len: int = 256, fast_tokenizer_path: str = "physical-intelligence/fast"): # 存储最大token长度 self._max_len = max_len # 下载PaliGemma分词器模型 path = download.maybe_download("gs://big_vision/paligemma_tokenizer.model", gs={"token": "anon"}) # 以二进制读取模式打开模型文件 with path.open("rb") as f: self._paligemma_tokenizer = sentencepiece.SentencePieceProcessor(model_proto=f.read() - 加载专门的 FAST Tokenizer——用于处理动作序列
# 实例化FAST分词器 # 从预训练路径加载FAST处理器 self._fast_tokenizer = AutoProcessor.from_pretrained(fast_tokenizer_path, trust_remote_code=True) - 设置 `_fast_skip_tokens = 128` 以跳过 PaliGemma 词汇表末尾的特殊token
# 跳过PaliGemma词表中的最后128个token,因为它们是特殊token self._fast_skip_tokens = 128
其次,是Tokenizer流程
- 接收文本提示、状态数组和可选的动作数组
# 定义分词方法 def tokenize( # 输入:提示文本、状态数组和可选的动作数组 self, prompt: str, state: np.ndarray, actions: np.ndarray | None # 返回四个numpy数组:tokens、token_mask、ar_mask和loss_mask ) -> tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]: # 清理文本:转小写,移除首尾空格,将下划线替换为空格 cleaned_text = prompt.lower().strip().replace("_", " ") - 将状态值离散化为 256 个区间(范围 [-1, 1])
# 约定:状态被离散化为256个离散区间(假设归一化后的范围:[-1, 1]) # 将状态数组离散化为0-255的整数 discretized_state = np.digitize(state, bins=np.linspace(-1, 1, 256 + 1)[:-1]) - 1 - 创建格式化前缀prefix,包含文本提示和状态信息
# 约定:前缀包括提示和状态的字符串表示,后跟';' # 将离散化状态转换为空格分隔的字符串 state_str = " ".join(map(str, discretized_state)) # 构建前缀文本,包含任务和状态信息 prefix = f"Task: {cleaned_text}, State: {state_str};\n" # 使用PaliGemma分词器编码前缀,添加开始token prefix_tokens = self._paligemma_tokenizer.encode(prefix, add_bos=True) - 如果提供了动作:
使用 FAST Tokenizer对动作进行Tokenizer
# 如果提供了动作 if actions is not None: # 使用FAST分词器对动作进行分词,并映射到PaliGemma词表的最后部分 # 将动作转换为token action_tokens = self._fast_tokenizer(actions[None])[0]通过 `_act_tokens_to_paligemma_tokens` 将这些动作token映射到 PaliGemma 词汇表中# 将FAST token转换为PaliGemma token action_tokens_in_pg = self._act_tokens_to_paligemma_tokens(action_tokens)创建包含 "Action:" 的后缀,后跟编码的动作和结束符 "|"# 约定:后缀包含'Action:',然后是FAST token,最后是'|' # 构建后缀token postfix_tokens = ( # 编码"Action: "文本 self._paligemma_tokenizer.encode("Action: ") # 添加转换后的动作token + action_tokens_in_pg.tolist() # 添加结束分隔符'|'的编码 + self._paligemma_tokenizer.encode("|") ) # 如果没有提供动作 else: # 后缀token为空列表 postfix_tokens = [] - 创建三种掩码:
# 创建输出token序列和掩码 # AR掩码在前缀上为0(双向注意力),在后缀上为1(对所有先前token的因果注意力) # 合并前缀和后缀token tokens = prefix_tokens + postfix_tokens # 创建token掩码,全为True token_mask = [True] * len(tokens) # 创建自回归掩码,前缀部分为0,后缀部分为1 ar_mask = [0] * len(prefix_tokens) + [1] * len(postfix_tokens) # 创建损失掩码,仅在后缀部分计算损失 loss_mask = [False] * len(prefix_tokens) + [True] * len(postfix_tokens) - 处理所有token序列和掩码的填充或截断
别忘了,上文所说的
1.2.4.2 特征嵌入方法:embed_prefix(图像和文本输入)、embed_suffix(状态和动作信息)
- `embed_prefix`:处理图像和文本输入(图像通过SigLip模型编码,文本通过Gemma LLM编码),创建前缀 token,皆为双向注意力,用ar_mask = false表示
- `embed_suffix`:处理机器人状态信息
其中
再其次,是动作提取功能
- 从token序列中提取动作
# 定义从token中提取动作的方法 def extract_actions(self, tokens: np.ndarray, action_horizon: int, action_dim: int) -> np.ndarray: # 解码预测的输出token —— 将token列表解码为文本 decoded_tokens = self._paligemma_tokenizer.decode(tokens.tolist()) - 定位 "Action:" 后和 "|" 前的部分
# 从FAST模型输出中提取动作:如果解码文本中不包含"Action: " if "Action: " not in decoded_tokens: # 返回全零动作数组 return np.zeros((action_horizon, action_dim), dtype=np.float32) - 重新映射token以恢复原始动作空间
# 从解码的token中提取动作 raw_action_tokens = np.array( # 提取"Action: "和"|"之间的内容,并编码为token self._paligemma_tokenizer.encode(decoded_tokens.split("Action: ")[1].split("|")[0].strip()) ) # 将原始action token转换为PaliGemma token格式 action_tokens = self._act_tokens_to_paligemma_tokens(raw_action_tokens) # 使用FAST分词器将token解码为动作向量 return self._fast_tokenizer.decode( [action_tokens.tolist()], time_horizon=action_horizon, action_dim=action_dim )[0]
最后是token映射函数
# 定义将FAST token转换为PaliGemma token的方法 def _act_tokens_to_paligemma_tokens(self, tokens: np.ndarray | list[int]) -> np.ndarray: # 如果输入是列表 if isinstance(tokens, list): # 转换为numpy数组 tokens = np.array(tokens) # 将FAST token映射到PaliGemma词表的对应位置 return self._paligemma_tokenizer.vocab_size() - 1 - self._fast_skip_tokens - tokens- `_act_tokens_to_paligemma_tokens` 方法实现了 FAST 动作token到 PaliGemma 词汇空间的双向映射
- 计算公式:`vocab_size - 1 - skip_tokens - token_id`
- 这种巧妙的映射让两个不同的Tokenizer系统能够协同工作
1.6 `lora.py` :实现了LoRA (Low-Rank Adaptation)微调方法
如之前所述,「关于什么是LoRA,详见此文《LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含对模型量化的解释)》的第4部分」
1.6.1 Einsum类中的setup
`setup` 方法,负责初始化模块所需的所有参数
- 首先,方法通过调用 `self.param` 创建了一个名为 "w" 的参数,这是模块的主要权重矩阵
- 接下来,代码使用海象运算符(`:=`)检查是否提供了 `lora_config`。如果存在配置,则进入 LoRA 参数的初始化流程
LoRA 的核心思想是将权重更新分解为两个低秩矩阵 A 和 B 的乘积。为此,代码首先创建了原始形状的可变副本 `shape_a` 和 `shape_b`,使用 `list()` 将可能是元组的 `self.shape` 转换为可修改的列表
- 随后,`shape_a` 的第二个指定轴(由 `config.axes[1]` 索引)被替换为 `config.rank`
而 `shape_b` 的第一个指定轴(由 `config.axes[0]` 索引)也被替换为相同的 `config.rank`
说白了,就是A矩阵是降维矩阵,故第二个指定轴是rank
b是升维矩阵,故b的第一个指定轴是rank
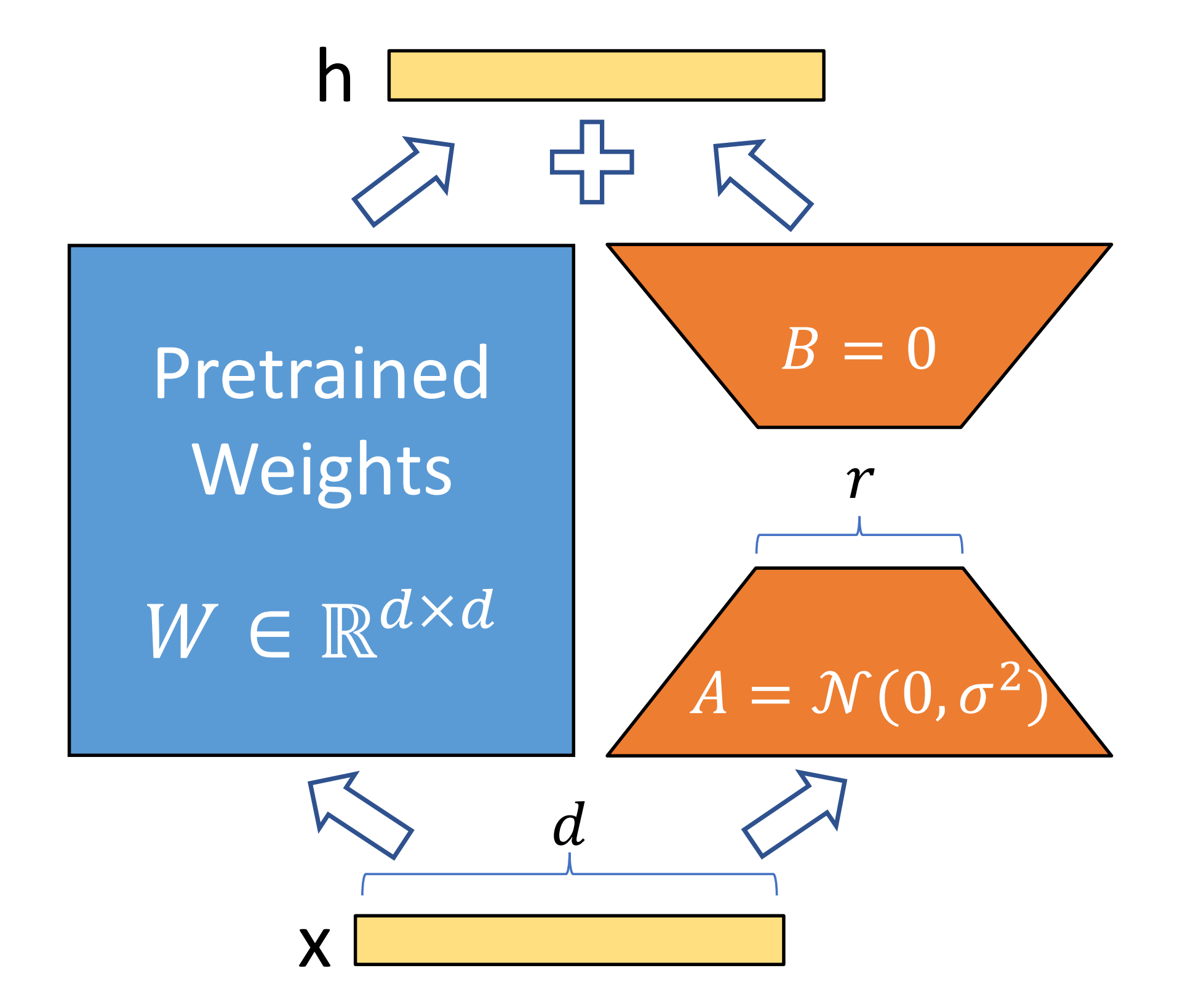
- 最后,代码使用 `config.init_fn` 初始化函数(通常是一个小标准差的正态分布)和修改后的形状,创建了两个 LoRA 参数:`self.w_a` 和 `self.w_b`。这些参数分别对应于 LoRA 的 A 和 B 矩阵,它们将在前向传播过程中用于计算 LoRA 更新
1.6.2 Einsum类中的__call__
`__call__` 方法实现了支持 LoRA (Low-Rank Adaptation) 技术的前向传播逻辑
- 首先,方法获取并存储输入张量 `x` 的数据类型 (`dtype`)
- 接下来,方法使用 `jnp.einsum` 函数计算标准的 Einstein 求和乘积,将输入 `x` 与权重矩阵 `self.w` 相乘。注意权重矩阵会被显式转换为与输入相同的数据类型,这是通过 `self.w.astype(dtype)` 实现的
此操作产生的 `result` 变量表示不带 LoRA 修正的基础输出
- 如果模块配置了 LoRA(通过 `self.lora_config` 存在),代码会进入 LoRA 计算分支。使用海象运算符 (`:=`) 既检查了 `lora_config` 的存在性,又将其赋值给局部变量 `config` 以便后续使用
LoRA 计算过程首先调用 `self._make_lora_eqns` 方法,将原始 einsum 方程转换为两个新方程 `eqn_a` 和 `eqn_b`,分别用于与 LoRA 矩阵 A 和 B 的乘法运算然后,代码执行这两个 einsum 运算:第一个将输入 `x` 与矩阵 A (`self.w_a`) 相乘,结果存储在 `lora` 变量中;第二个将 `lora` 与矩阵 B (`self.w_b`) 相乘,更新 `lora` 变量
同样,为保持数值一致性,LoRA 参数也会被转换为与输入相同的数据类型
最后,将 LoRA 计算结果乘以配置中指定的缩放值 (`config.scaling_value`)——缩放因子通常设置为 `alpha/rank` 或对于 RS-LoRA 为 `alpha/sqrt(rank)`,并将其添加到基础输出中,形成最终结果
1.6.3 Einsum类中的_make_lora_eqns
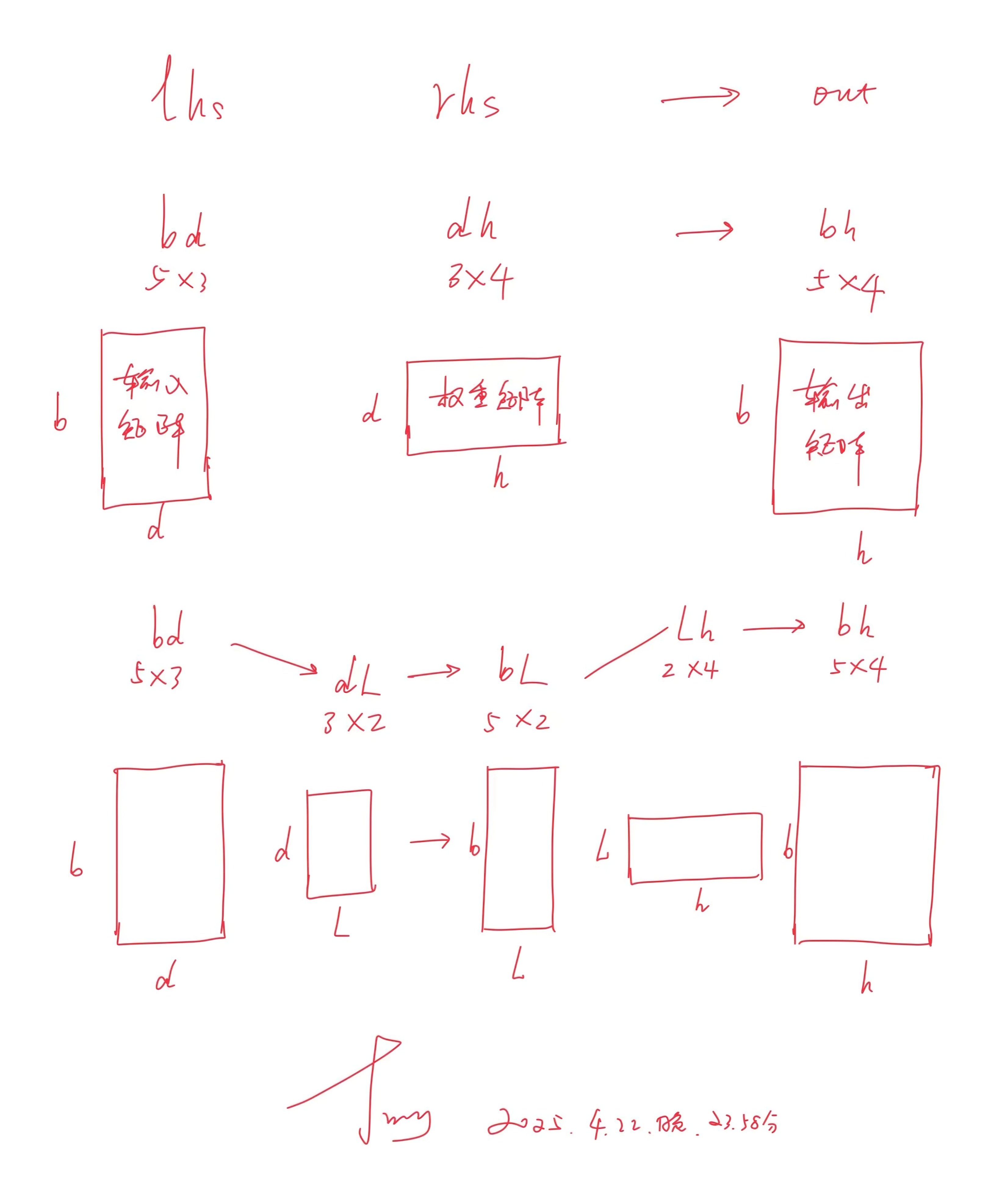
_make_lora_eqns负责将标准的 Einstein 求和表达式转换为两个新的表达式,以支持 LoRA 的低秩分解计算。其工作原理基于巧妙的字符串处理,将一个矩阵乘法操作分解为两个连续的矩阵乘法
- 方法首先执行两项重要的验证
如果存在,方法会抛出 `ValueError` 异常,因为 "L" 被保留用作 LoRA 的特殊维度标识符
def _make_lora_eqns(self, eqn: str) -> tuple[str, str]: if "L" in eqn: raise ValueError(f"L already in eqn: {eqn}")如果方程格式不符合此模式,方法会抛出另一个 `ValueError`
if not (m := re.match("(.*),(.*)->(.*)", eqn)): raise ValueError(f"Unsupported einsum eqn: {eqn}")成功匹配后,方法通过调用 `m.groups()` 提取这三个组件,并将它们分别存储在 `lhs`、`rhs` 和 `out` 变量中lhs, rhs, out = m.groups()
例如,对于方程 "bd,dh->bh",这些变量将分别包含 "bd"、"dh" 和 "bh" - 接下来是方法的核心部分
首先,根据 `self.lora_config.axes` 指定的索引,从 `rhs` 字符串中提取两个关键轴标签 `a_label` 和 `b_label`
assert self.lora_config is not None a_label, b_label = (rhs[x] for x in self.lora_config.axes) label = self.lora_config.label例如,如果 `rhs` 是 "dh" 且 `axes` 为 (-2, -1)——代表最后两个轴,则`a_label` 为 "d"
`b_label` 为 "h"
其次,进行两步字符串替换,创建两个新的 einsum 方程
例如,对于前面 "lhs,rhs->out所对应的例子"bd,dh->bh",`a_rhs`-dh 会变成 "dL",`a_out`-bh 会变成 "bL"
a_rhs = rhs.replace(b_label, label) a_out = out.replace(b_label, label)生成的 `eqn_a` 为 "bd,dL->bL",表示将输入bd 与 LoRA 矩阵 A dL相乘,得到此第一步的结果bLeqn_a = f"{lhs},{a_rhs}->{a_out}"使用前面 "lhs,rhs->out所对应的例子"bd,dh->bh"
`b_rhs-dh` 将变为 "Lh"
b_rhs = rhs.replace(a_label, label)
然后构造第二个方程 `eqn_b`,形式为 "bL/bL,Lh->bh"为何这里的输入是bL/bL呢,因为其表示的就是将第一步的结果bL/bL与 LoRA 矩阵 B Lh 相乘
eqn_b = f"{a_out},{b_rhs}->{out}" - 最后,方法返回这两个新创建的 einsum 方程作为元组
return eqn_a, eqn_b
这些方程将被用于在前向传播过程中计算 LoRA 的低秩更新
总的来说,上面的整个过程 还是比较绕的,为方便大家一目了然的快速理解,我特意花了10分钟画了个图示——而我一个人多花10分钟,可以让数千人、数万人在理解上 少花10分钟,这价值非常大,会更清晰
1.6.4 FeedForward类中的setup、__call__、_dot
1.7 `vit.py`: Vision Transformer实现
// 待更
第二部分 策略适配接口:src下policy的全面分析与解读
src/openpi/policies目录包含以下文件:
BasePolicy (policy.py)
├── Policy
│ ├── BaseModel
│ └── transforms.py
├── AlohaPolicy (aloha_policy.py)
├── DroidPolicy (droid_policy.py)
└── LiberoPolicy (libero_policy.py)
此外,每个特定机器人都有自己的策略文件,如
- aloha_policy.py
- droid_policy.py
- libero_policy.py
这些文件定义了特定于机器人的输入和输出转换函数,处理数据格式、规范化和特定的转换需求
- 比如每种机器人(ALOHA、DROID、LIBERO)的策略文件定义了特定的输入/输出转换类
- 这些转换类作为 `transforms` 参数传递给 `Policy` 构造函数,例如,`AlohaInputs` 处理 ALOHA 机器人特有的状态和图像格式,`AlohaOutputs` 处理对应的输出转换
2.1 policy.py:实现了Policy类和 PolicyRecorder类
2.1.1 Policy 类
policy.py 定义了基本的 `Policy` 类和 `PolicyRecorder` 类,它们继承自`openpi_client.base_policy.BasePolicy`
首先,做一系列初始化
class Policy(BasePolicy): # 定义Policy类,继承自BasePolicy def __init__( self, model: _model.BaseModel, # 模型参数,必须是BaseModel的实例 *, # 之后的所有参数必须使用关键字传递 rng: at.KeyArrayLike | None = None, # 随机数生成器,可选 # 输入转换函数序列,默认为空 transforms: Sequence[_transforms.DataTransformFn] = (), # 输出转换函数序列,默认为空 output_transforms: Sequence[_transforms.DataTransformFn] = (), # 传递给sample_actions的额外参数,可选 sample_kwargs: dict[str, Any] | None = None, metadata: dict[str, Any] | None = None, # 元数据字典,可选 ): # 使用JIT编译model的sample_actions方法提高性能 self._sample_actions = nnx_utils.module_jit(model.sample_actions) # 组合所有输入转换函数为一个函数 self._input_transform = _transforms.compose(transforms) # 组合所有输出转换函数为一个函数 self._output_transform = _transforms.compose(output_transforms) self._rng = rng or jax.random.key(0) # 设置随机数生成器,如果未提供则创建一个新的 self._sample_kwargs = sample_kwargs or {} # 存储采样参数,如果未提供则使用空字典 self._metadata = metadata or {} # 存储元数据,如果未提供则使用空字典其次,对于infer 方法——在策略内部流程上
- 复制输入观察数据
def infer(self, obs: dict) -> dict: # type: ignore[misc] # 推理方法,接收观察字典,返回动作字典 # 复制输入,因为转换可能会修改输入 inputs = jax.tree.map(lambda x: x, obs) # 使用JAX树映射创建输入的深拷贝 - 应用输入转换
Policy.infer` 方法首先应用输入转换:self._input_transform,将客户端提供的观察转换为模型所需的格式
inputs = self._input_transform(inputs) # 应用输入转换函数处理输入数据
- 将数据转换为批处理格式并转为 JAX 数组
# 将输入转换为批处理格式并转为jax数组 inputs = jax.tree.map(lambda x: jnp.asarray(x)[np.newaxis, ...], inputs) # 添加批次维度并转为JAX数组生成新的随机数键self._rng, sample_rng = jax.random.split(self._rng) # 分割随机数键以保持随机性
- 模型推理
调用模型的 `sample_actions` 方法「该方法的实现,详见上文的1.2.4.4 推理函数 `sample_actions`:基于扩散模型逆向采样,生成机器人动作序列」进行推理,即获取动作预测
outputs = { "state": inputs["state"], # 保留状态信息 "actions": self._sample_actions(sample_rng, _model.Observation.from_dict(inputs), **self._sample_kwargs), # 使用模型生成动作 } - 解除批处理并转换为 NumPy 数组
# 移除批次维度并转换为NumPy数组 outputs = jax.tree.map(lambda x: np.asarray(x[0, ...]), outputs) # 取第一个样本并转为NumPy数组 - 输出转换
最后应用输出转换 (`self._output_transform`),将模型输出转换为客户端期望的格式
return self._output_transform(outputs) # 应用输出转换并返回结果
2.1.2 `PolicyRecorder`
PolicyRecorder是一个装饰器类,它包装了一个基础策略,并在执行策略的同时将所有的输入和输出保存到磁盘,用于记录策略的行为
对于初始化函数:`policy`,涉及被包装的基础策略、record_dir`:保存记录的目录路径
对于infer 方法
- 调用被包装策略的 `infer` 方法获取结果
- 将输入和输出数据组织为字典
- 使用 Flax 的 `flatten_dict` 函数将嵌套字典展平
- 构建输出文件路径
- 将数据保存为 NumPy 数组文件
- 返回策略结果
// 待更
2.2 policy_config.py
policy_config.py 定义了 `PolicyConfig` 类和 `create_trained_policy` 函数
`create_trained_policy` 函数用于从训练好的检查点创建策略实例,加载模型参数、归一化统计数据,并配置转换函数
相当于客户端代码会实例化一个 `Policy` 对象,通常是通过 `create_trained_policy` 函数,客户端通过调用 `policy.infer(obs)` 方法获取策略输出
2.2.1 PolicyConfig 数据类
`PolicyConfig` 是一个使用 `@dataclasses.dataclass` 装饰的数据类,用于存储创建策略所需的所有配置信息:
# 定义策略配置类 class PolicyConfig: model: _model.BaseModel # 模型实例,必须是BaseModel类型 norm_stats: dict[str, transforms.NormStats] # 归一化统计信息,键是特征名称,值是归一化统计数据 input_layers: Sequence[transforms.DataTransformFn] # 输入数据转换函数序列 output_layers: Sequence[transforms.DataTransformFn] # 输出数据转换函数序列 model_type: _model.ModelType = _model.ModelType.PI0 # 模型类型,默认为PI0 default_prompt: str | None = None # 默认提示文本,可选 sample_kwargs: dict[str, Any] | None = None # 采样参数字典,可选这个类主要是作为配置容器,将所有策略创建时需要的参数组织在一起
2.2.2 create_trained_policy 函数
`create_trained_policy` 函数是从训练好的检查点创建可用策略的工厂函数
def create_trained_policy( train_config: _config.TrainConfig, # 训练配置对象,包含训练时的所有参数设置 checkpoint_dir: pathlib.Path | str, # 检查点目录路径,可以是Path对象或字符串 *, # 强制后续参数使用关键字传递 repack_transforms: transforms.Group | None = None, # 可选的重新打包转换组 sample_kwargs: dict[str, Any] | None = None, # 采样参数,可选 default_prompt: str | None = None, # 默认提示文本,可选 norm_stats: dict[str, transforms.NormStats] | None = None, # 归一化统计信息,可选 ) -> _policy.Policy: # 返回类型是Policy对象函数的核心流程是:
- 处理输入参数,确保 `repack_transforms` 不为空
且检查并可能下载检查点目录
repack_transforms = repack_transforms or transforms.Group() # 确保repack_transforms不为空,如果未提供则创建空Group checkpoint_dir = download.maybe_download(str(checkpoint_dir)) # 检查并可能下载检查点目录 - 使用 `train_config` 加载模型参数
logging.info("Loading model...") # 记录日志,表示正在加载模型 # 加载模型参数并创建模型实例,使用bfloat16数据类型 model = train_config.model.load(_model.restore_params(checkpoint_dir / "params", dtype=jnp.bfloat16)) - 创建数据配置
data_config = train_config.data.create(train_config.assets_dirs, train_config.model) # 创建数据配置 if norm_stats is None: # 如果未提供归一化统计信息 # 我们从检查点而非配置资源目录加载归一化统计信息,以确保策略使用与原始训练过程相同的归一化统计信息 - 如果未提供 `norm_stats`,从检查点加载归一化统计信息
if data_config.asset_id is None: # 如果数据配置中没有asset_id raise ValueError("Asset id is required to load norm stats.") # 抛出异常,需要asset_id来加载归一化统计信息 norm_stats = _checkpoints.load_norm_stats(checkpoint_dir / "assets", data_config.asset_id) # 从检查点加载归一化统计信息 - 构建并返回 `Policy` 实例,将所有转换函数组织为有序的处理流程:
return _policy.Policy( # 创建并返回Policy实例 model, # 传入模型输入处理:重新打包转换 → 注入默认提示 → 数据转换 → 归一化 → 模型特定转换transforms=[ # 输入转换函数序列 *repack_transforms.inputs, # 展开重打包转换的输入部分 transforms.InjectDefaultPrompt(default_prompt), # 注入默认提示 *data_config.data_transforms.inputs, # 展开数据转换的输入部分 transforms.Normalize(norm_stats, use_quantiles=data_config.use_quantile_norm), # 添加归一化转换 *data_config.model_transforms.inputs, # 展开模型特定转换的输入部分 ],输出处理:模型特定转换 → 反归一化 → 数据转换 → 重新打包转换output_transforms=[ # 输出转换函数序列 *data_config.model_transforms.outputs, # 展开模型特定转换的输出部分 transforms.Unnormalize(norm_stats, use_quantiles=data_config.use_quantile_norm), # 添加反归一化转换 *data_config.data_transforms.outputs, # 展开数据转换的输出部分 *repack_transforms.outputs, # 展开重打包转换的输出部分 ], sample_kwargs=sample_kwargs, # 设置采样参数 metadata=train_config.policy_metadata, # 设置策略元数据 )
`create_trained_policy` 函数是框架中连接训练过的模型与实际部署使用的关键桥梁,它通过组合各种转换函数,创建出可直接用于推理的 `Policy` 实例
2.3 policies/aloha_policy.py
这段代码实现了一个用于 Aloha 策略的输入输出处理和数据转换的模块
2.3.1 make_aloha_example:输入示例——状态向量、图像数据、文本prompt
首先,`make_aloha_example` 函数创建了一个随机的输入示例,包括一个14维的状态向量和四个摄像头的图像数据(高、低、左腕、右腕视角),以及一个文本提示信息
# 定义一个函数,创建Aloha策略的随机输入示例 def make_aloha_example() -> dict: # 返回一个字典,包含状态、图像和提示信息 return { # 创建一个14维的状态向量,所有值为1 "state": np.ones((14,)), # 创建一个包含四个摄像头图像的字典 "images": { # 高位摄像头图像 "cam_high": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), # 低位摄像头图像 "cam_low": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), # 左手腕摄像头图像 "cam_left_wrist": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), # 右手腕摄像头图像 "cam_right_wrist": np.random.randint(256, size=(3, 224, 224), dtype=np.uint8), }, "prompt": "do something", }这些数据将用于测试和验证 Aloha 策略的输入处理
可能有的同学对上面的4个摄像头有疑问,简单,详见此文《 一文通透动作分块算法ACT:斯坦福ALOHA团队推出的动作序列预测算法(Action Chunking with Transformers)》的「1.2 硬件套装:ALOHA——低成本的开源硬件系统,用于手动远程操作」如下图所示

- 左侧为前、顶部和两个手腕摄像机的视角(这4个相机的视角分别用从当前往后的蓝线、从顶向下的绿线、从左往右的红线、从右往左的红线表示),以及ALOHA双手工作空间的示意图
具体而言,总计4个Logitech C922x网络摄像头,每个流输出480×640 RGB图像
2.3.2 AlohaInputs:定义Aloha 策略的输入数据结构
接下来,`AlohaInputs` 类定义了 Aloha 策略的输入数据结构
class AlohaInputs(transforms.DataTransformFn): # 定义AlohaInputs类,继承自transforms.DataTransformFn """Inputs for the Aloha policy. # 预期输入格式 # 图像字典,键是名称,值是形状为[channel, height, width]的图像 - images: dict[name, img] # 状态向量,长度为14 - state: [14] # 动作矩阵,形状为[action_horizon, 14] - actions: [action_horizon, 14] """ # 模型的动作维度,将用于填充状态和动作 action_dim: int # 动作维度 # 如果为True,将关节和夹持器值从标准Aloha空间转换为pi内部运行时使用的空间 # pi内部运行时使用的空间用于训练基础模型 # 是否适配pi内部运行时,默认为True adapt_to_pi: bool = True # 预期的摄像头名称,所有输入摄像头必须在此集合中。缺失的摄像头将用黑色图像替代 # 缺失的摄像头将用黑色图像替代,对应的`image_mask`将设置为False # 预期的摄像头名称集合 EXPECTED_CAMERAS: ClassVar[tuple[str, ...]] = ("cam_high", "cam_low", "cam_left_wrist", "cam_right_wrist")- 这个类使用 `dataclasses.dataclass` 装饰器来简化类的定义,并确保实例是不可变的(`frozen=True`)
- 类中定义了输入数据的预期格式,包括图像、状态和动作数据
__call__方法,实现了对Aloha策略输入数据的标准化处理。该方法将原始输入数据转换为模型可接受的格式,包括多项关键处理步骤,比如进行必要的解码和填充操作,并检查图像数据是否包含预期的摄像头视角
- 首先,方法通过调用`_decode_aloha`函数对输入数据进行初步解码,根据`adapt_to_pi`参数决定是否将数据适配到π内部运行时环境
# 定义__call__方法,处理输入数据 def __call__(self, data: dict) -> dict: # 解码Aloha数据,根据adapt_to_pi参数进行适配 data = _decode_aloha(data, adapt_to_pi=self.adapt_to_pi)这一步主要处理状态向量以及将图像格式从`[channel, height, width]`转换为`[height, width, channel]` - 接着,方法将14维的状态向量使用零填充扩展到模型所需的动作维度(`action_dim`)
# 获取状态数据,将其从14维填充到模型的动作维度 # 使用transforms.pad_to_dim函数填充状态数据 state = transforms.pad_to_dim(data["state"], self.action_dim)随后,进行输入图像的验证:检查输入图像的键集合是否超出了预期的摄像头列表范围,若发现未知摄像头视角则抛出`ValueError`# 获取输入图像数据 in_images = data["images"] # 检查输入图像是否包含所有预期的摄像头 if set(in_images) - set(self.EXPECTED_CAMERAS): # 如果缺少预期的摄像头,抛出异常 raise ValueError(f"Expected images to contain {self.EXPECTED_CAMERAS}, got {tuple(in_images)}") - 在构建输出字典时,方法首先假定"cam_high"(高视角摄像头)图像必定存在
# 假设基础图像总是存在,获取高位摄像头图像 base_image = in_images["cam_high"]并将其作为基础图像(`base_0_rgb`)# 创建图像字典 images = { # 基础图像 "base_0_rgb": base_image, }同时创建了相应的图像掩码字典,标记该图像为有效# 创建图像掩码字典 image_masks = { # 基础图像掩码为True "base_0_rgb": np.True_, } - 对于其他摄像头视角(左腕和右腕),方法使用映射关系字典进行处理:
# 添加额外的图像 # 额外图像名称映射 extra_image_names = { # 左手腕图像 "left_wrist_0_rgb": "cam_left_wrist", # 右手腕图像 "right_wrist_0_rgb": "cam_right_wrist", }如果相应的源图像存在,则将其添加到输出图像字典并标记为有效;# 遍历额外图像名称映射 for dest, source in extra_image_names.items(): # 如果输入图像中包含该图像 if source in in_images: # 添加到图像字典 images[dest] = in_images[source] # 设置图像掩码为True image_masks[dest] = np.True_若不存在,则创建一个与基础图像相同大小的全零图像(黑图),并标记为无效# 如果输入图像中不包含该图像 else: # 用黑色图像替代 images[dest] = np.zeros_like(base_image) # 设置图像掩码为False image_masks[dest] = np.False_这种处理方式确保了模型在缺失某些视角图像时仍能正常工作# 创建输入字典 inputs = { "image": images, # 图像数据 "image_mask": image_masks, # 图像掩码 "state": state, # 状态数据 } - 方法还会处理训练时特有的数据,如动作序列
若输入数据包含"actions"字段,则将其转换为NumPy数组,应用`_encode_actions_inv`进行编码转换,并使用零填充扩展到模型动作维度
# 动作数据仅在训练期间可用 # 如果输入数据中包含动作数据 if "actions" in data: # 将动作数据转换为NumPy数组 actions = np.asarray(data["actions"]) # 编码动作数据,根据adapt_to_pi参数进行适配 actions = _encode_actions_inv(actions, adapt_to_pi=self.adapt_to_pi) # 填充动作数据到模型的动作维度 inputs["actions"] = transforms.pad_to_dim(actions, self.action_dim)最后,如果输入包含"prompt"文本提示,也会将其添加到输出字典中,然后返回处理后的输入数据# 如果输入数据中包含提示信息 if "prompt" in data: # 添加提示信息到输入字典 inputs["prompt"] = data["prompt"] # 返回处理后的输入数据 return inputs
整体而言,这个方法实现了从多样化的原始输入到标准化模型输入的转换流程,处理了数据格式转换、缺失数据补充、维度调整等核心问题,确保了Aloha策略模型能够接收一致的输入格式,从而实现稳定的推理和训练
2.3.3 AlohaOutputs:定义Aloha 策略的输出数据结构
`AlohaOutputs` 类定义了 Aloha 策略的输出数据结构,同样使用 `dataclasses.dataclass` 装饰器
# 定义AlohaOutputs类,继承自transforms.DataTransformFn class AlohaOutputs(transforms.DataTransformFn): # 如果为True,将关节和夹持器值从标准Aloha空间转换为pi内部运行时使用的空间 # pi内部运行时使用的空间用于训练基础模型 adapt_to_pi: bool = True # 是否适配pi内部运行时,默认为True`__call__` 方法处理输出数据,仅返回前14个维度的动作数据,并进行必要的编码转换
# 定义__call__方法,处理输出数据 def __call__(self, data: dict) -> dict: # 仅返回前14维的动作数据,即将动作数据转换为NumPy数组,并取前14维 actions = np.asarray(data["actions"][:, :14]) # 编码动作数据并返回字典 return {"actions": _encode_actions(actions, adapt_to_pi=self.adapt_to_pi)}2.3.4 多个辅助函数:数据的标准化、反标准化、关节角度翻转
此外,代码中还包含多个辅助函数,用于数据的标准化、反标准化、关节角度翻转、夹持器位置的线性和角度转换等
这些函数确保了数据在不同控制系统之间的兼容性和一致性
// 待更
第三部分 模型训练的配置:src下training模块的全面分析与解读
training模块是 OpenPI 项目中负责训练相关功能的核心部分,该目录下包含了以下主要文件:
- checkpoints.py - 检查点管理
- config.py - 配置系统
- data_loader.py - 数据加载器
- data_loader_test.py - 数据加载器测试
- optimizer.py - 优化器实现
- sharding.py - 模型分片工具
- utils.py - 通用工具函数
- weight_loaders.py - 模型权重加载器
3.1 配置系统 (config.py)
定义了训练过程的各种配置类型,包括:
- `TrainConfig`:顶级训练配置,包含模型、数据、优化器等所有训练参数
- `DataConfigFactory`:抽象工厂类,用于创建特定环境的数据配置
- `AssetsConfig`:管理资产(如归一化统计数据)的位置
- 预定义了多种常用配置(如 ALOHA、DROID、LIBERO 等环境的配置)
- 通过 `get_config` 函数根据名称检索预定义配置
在配置流程上
- 训练脚本通过 `_config.cli()` 或 `_config.get_config()` 获取配置
- 配置系统加载预定义的训练参数,确定训练环境和模型参数
- 数据配置通过工厂模式创建,根据不同环境(ALOHA、DROID 等)提供不同的预处理流程
3.1.1 基础配置类AssetsConfig、DataConfig
一个是AssetsConfig
class AssetsConfig: """用于确定数据pipeline所需资产(如归一化统计信息)的位置""" assets_dir: str | None = None # 资产目录 asset_id: str | None = None # 资产ID
一个是DataConfig
@dataclasses.dataclass(frozen=True) class DataConfig: repo_id: str | None = None # 数据集仓库ID asset_id: str | None = None # 资产ID norm_stats: dict[str, _transforms.NormStats] | None = None # 归一化统计信息 repack_transforms: _transforms.Group # 数据重打包转换 data_transforms: _transforms.Group # 数据预处理转换 model_transforms: _transforms.Group # 模型特定转换3.1.2 数据集配置:包含ALOHA、Libero两套数据集——LeRobotLiberoDataConfig
涉及两个配置
- 一个是LeRobotAlohaDataConfig
@dataclasses.dataclass(frozen=True) class LeRobotAlohaDataConfig(DataConfigFactory): """ALOHA数据集配置""" use_delta_joint_actions: bool = True # 是否使用关节角度增量 default_prompt: str | None = None # 默认提示语 adapt_to_pi: bool = True # 是否适配到π内部运行时 - 一个是LeRobotLiberoDataConfig
@dataclasses.dataclass(frozen=True) class LeRobotLiberoDataConfig(DataConfigFactory): """Libero数据集配置"""对于后者的结构,详见下图
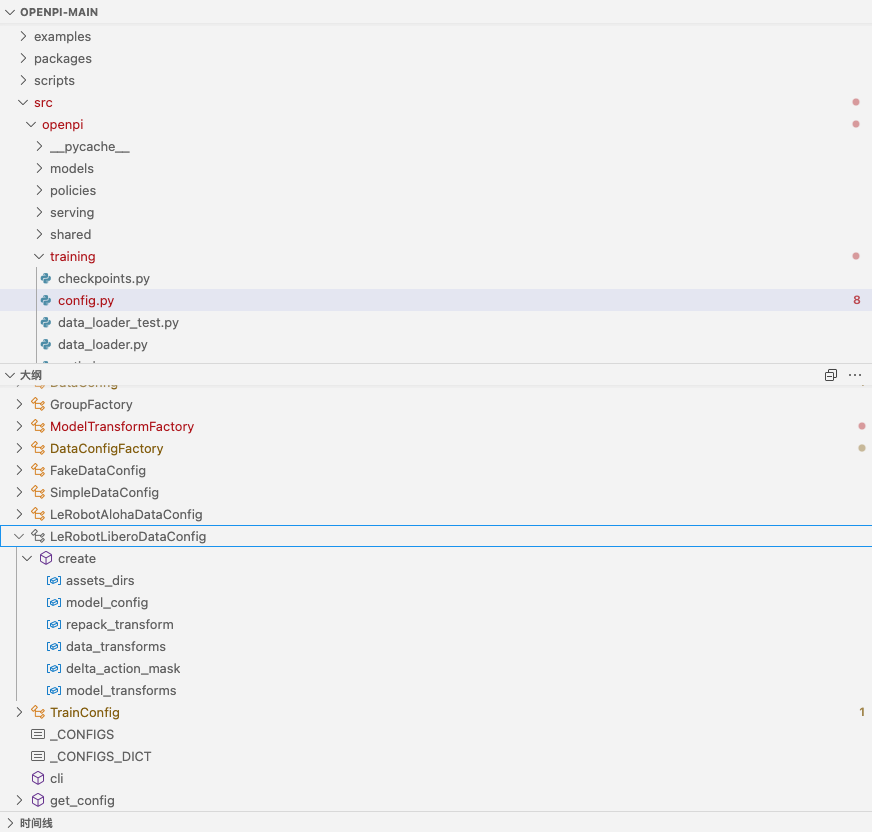
- `LeRobotLiberoDataConfig` 是一个用于机器人控制系统的数据配置类,它负责定义整个数据管道中不同阶段的数据转换操作。这个类通过 `@dataclasses.dataclass(frozen=True)` 装饰器声明为不可变数据类,确保配置一旦创建就不能被修改,增强了数据处理的稳定性
- 该类重写了基类 `DataConfigFactory` 的 `create` 方法,该方法是整个配置系统的核心,负责构建完整的数据配置
def create(self, assets_dirs: pathlib.Path, model_config: _model.BaseModelConfig) -> DataConfig: # 重写父类方法,创建数据配置。参数包括资产目录路径和模型配置,返回DataConfig对象 # ..方法接收两个关键参数:存放数据资产的目录路径和模型配置对象,然后返回一个完整的 `DataConfig` 对象 - 在方法内部,首先定义了 `repack_transform`,这是一个仅在训练阶段应用的转换器,用于将数据集中的键名映射到推理环境期望的键名
例如,将 `"observation/image"` 映射到 `"image"`。这种转换确保了训练数据和推理环境之间的一致性,是适配不同数据源的关键步骤
- 接下来,`data_transforms` 配置了同时应用于训练和推理阶段的转换操作
它使用 `libero_policy.LiberoInputs` 处理输入数据,`libero_policy.LiberoOutputs` 处理输出数据
# 数据转换应用于来自数据集的数据和推理过程中的数据 # 下面,定义了进入模型的数据转换("inputs")和从模型输出的数据转换("outputs")(后者仅在推理时使用) # 这些转换在`libero_policy.py`中定义 # 一旦创建了自己的转换,你可以用自己的替换下面的转换 data_transforms = _transforms.Group( # 定义输入转换,使用LiberoInputs处理器 inputs=[libero_policy.LiberoInputs(action_dim=model_config.action_dim, model_type=model_config.model_type)], # 定义输出转换,使用LiberoOutputs处理器 outputs=[libero_policy.LiberoOutputs()], )这些转换器负责将原始数据调整为模型能够处理的格式 - 特别值得注意的是关于动作表示的转换:该配置支持将绝对动作(如具体的关节角度)转换为相对动作(相对于初始状态的变化量)
通过 `delta_action_mask` 创建一个布尔掩码,指定哪些动作维度需要进行转换(这里是前6个维度对应机器人关节,保留最后一个维度对应夹爪不变)
# 创建动作掩码,指定哪些维度需要转换为相对动作(前6个关节),哪些保持绝对值(夹爪) # 创建布尔掩码,前6个维度为True,最后一个维度为False delta_action_mask = _transforms.make_bool_mask(6, -1)这对于训练基于相对动作的模型(如Pi0模型)非常重要 - 最后,`model_transforms` 处理模型特有的转换操作,比如提示文本的token化和图像尺寸调整
# 使用模型配置创建模型转换——处理提示文本的token化和其他模型特定的转换 model_transforms = ModelTransformFactory()(model_config)这些转换由 `ModelTransformFactory` 根据模型类型动态创建,支持不同类型的模型(Pi0或Pi0_FAST) - 整个方法通过 `dataclasses.replace` 将这些转换器与基础配置(通过 `create_base_config` 创建)合并,生成最终的数据配置对象
return dataclasses.replace( self.create_base_config(assets_dirs), # 创建基础配置 repack_transforms=repack_transform, # 设置重新打包转换 data_transforms=data_transforms, # 设置数据转换 model_transforms=model_transforms, # 设置模型转换 )
3.1.3 训练配置TrainConfig:模型、数据、优化器等训练参数的设置
class TrainConfig: name: str # 配置名称 project_name: str = "openpi" # 项目名称 exp_name: str # 实验名称 model: _model.BaseModelConfig # 模型配置 batch_size: int = 32 # 批次大小 num_train_steps: int = 30_000 # 训练步数 lr_schedule: _optimizer.LRScheduleConfig # 学习率调度 optimizer: _optimizer.OptimizerConfig # 优化器配置
3.1.4 预定义配置:基于ALOHA/Libero数据集微调π0——比如完成aloha_sim_transfer_cube_human
文件最后定义了多个具体的训练配置:
- 比如ALOHA的
TrainConfig( name="pi0_aloha_pen_uncap", # 配置名称,反映模型和数据集 model=pi0.Pi0Config(), # 使用pi0模型配置 data=LeRobotAlohaDataConfig( # 使用LeRobotAloha数据集配置 # 数据集仓库ID repo_id="physical-intelligence/aloha_pen_uncap_diverse", # 资产配置 assets=AssetsConfig( # 资产目录 assets_dir="s3://openpi-assets/checkpoints/pi0_base/assets", # 资产ID asset_id="trossen", ), # 默认提示语 default_prompt="uncap the pen", # 数据重打包转换 repack_transforms=_transforms.Group( inputs=[ # 重打包转换 _transforms.RepackTransform( { "images": { # 高视角摄像头图像 "cam_high": "observation.images.cam_high", # 左手腕摄像头图像 "cam_left_wrist": "observation.images.cam_left_wrist", # 右手腕摄像头图像 "cam_right_wrist": "observation.images.cam_right_wrist", }, # 机器人状态 "state": "observation.state", # 动作 "actions": "action", } ) ] ), base_config=DataConfig( # 是否只使用本地数据集,False表示允许从Hugging Face下载 local_files_only=False, ), ), # 加载预训练权重 weight_loader=weight_loaders.CheckpointWeightLoader("s3://openpi-assets/checkpoints/pi0_base/params"), # 训练步数为20,000步 num_train_steps=20_000, ),当然,这里面还涉及到ALOHA中一个仿真环境中的操作任务# 这个配置用于演示如何在简单的模拟环境中进行训练 TrainConfig( name="pi0_aloha_sim", # 配置名称 model=pi0.Pi0Config(), # 使用pi0模型配置 data=LeRobotAlohaDataConfig( # 使用LeRobotAloha数据集配置 # 数据集仓库ID repo_id="lerobot/aloha_sim_transfer_cube_human", default_prompt="Transfer cube", # 默认提示语 use_delta_joint_actions=False, # 是否使用关节角度增量 ), weight_loader=weight_loaders.CheckpointWeightLoader("s3://openpi-assets/checkpoints/pi0_base/params"), # 加载预训练权重 num_train_steps=20_000, # 训练步数为20,000步 ), - 再比如Libero的
TrainConfig( # 更改名称以反映你的模型和数据集 name="pi0_libero", # 在这里定义模型配置 - 这个例子中我们使用pi0作为模型架构并执行完整微调 # 在后面的例子中我们会展示如何修改配置来执行低内存(LORA)微调 # 以及如何使用pi0-FAST作为替代架构 model=pi0.Pi0Config(), # 在这里定义要训练的数据集。这个例子中我们使用Libero数据集 # 对于你自己的数据集,你可以更改repo_id指向你的数据集 # 同时修改DataConfig以使用你为数据集创建的新配置 data=LeRobotLiberoDataConfig( # 指定数据集的Hugging Face仓库ID repo_id="physical-intelligence/libero", # 基础配置设置 base_config=DataConfig( # 是否只使用本地数据集,False表示允许从Hugging Face下载 local_files_only=False, # 这个标志决定是否从LeRobot数据集的task字段加载提示(即任务指令) # 如果设为True,提示将会出现在输入字典的prompt字段中 # 推荐设置为True prompt_from_task=True, ), ), # 在这里定义要加载哪个预训练检查点来初始化模型 # 这应该与你上面选择的模型配置匹配 - 即在这种情况下我们使用pi0基础模型 weight_loader=weight_loaders.CheckpointWeightLoader( "s3://openpi-assets/checkpoints/pi0_base/params" ), # 在下面你可以定义其他超参数,如学习率、训练步数等 # 查看TrainConfig类以获取完整的可用超参数列表 num_train_steps=30_000, # 设置训练步数为30,000步 ),3.2 数据加载系统 data_loader.py
定义了数据集和数据加载器的接口(`Dataset` 和 `DataLoader`)
- 实现了数据转换管道,将原始数据转换为模型可用的格式
- 支持各种数据源:真实数据集(通过 LeRobot 数据集接口)、模拟数据(使用 `FakeDataset`)
- 提供数据归一化和转换功能
在数据加载流程上
TrainConfig
└── data (DataConfigFactory)
├── create() → DataConfig
│ ├── repo_id: 数据集 ID
│ ├── norm_stats: 归一化统计数据
│ ├── repack_transforms: 数据重包装转换
│ ├── data_transforms: 特定于环境的转换
│ └── model_transforms: 特定于模型的转换
└── _load_norm_stats() → 归一化统计数据
create_data_loader(config)
├── data_config = config.data.create()
├── dataset = create_dataset(data_config, config.model)
├── dataset = transform_dataset(dataset, data_config)
└── return DataLoaderImpl(data_config, TorchDataLoader(...))
3.2.1 FakeDataset类
3.2.2 create_dataset:创建适合训练的数据集
`create_dataset` 函数是一个关键的数据准备工具,负责根据配置参数创建适合模型训练的数据集。这个函数通过处理不同数据源和应用必要的转换,为模型提供标准化的训练数据。
- 首先,函数检查 `data_config.repo_id` 的值,这个参数指定了数据仓库的标识符
def create_dataset(data_config: _config.DataConfig, model_config: _model.BaseModelConfig) -> Dataset: """创建用于训练的数据集""" # 从数据配置中获取仓库ID repo_id = data_config.repo_id如果 `repo_id` 为 `None`,函数会抛出 `ValueError` 异常,明确指出无法创建数据集。这是一种防御性编程的体现,确保基本的配置参数存在# 如果仓库ID为空,抛出错误 if repo_id is None: raise ValueError("Repo ID is not set. Cannot create dataset.")如果 `repo_id` 的值为 "fake",函数则创建并返回一个 `FakeDataset` 实例,其样本数设为 1024。这种虚拟数据集在测试模型架构、调试训练流程或者进行性能基准测试时非常有用,无需加载真实数据即可快速验证系统功能# 如果是fake数据集,返回包含1024个样本的假数据集 if repo_id == "fake": return FakeDataset(model_config, num_samples=1024)对于其他情况(即使用真实数据),函数首先创建 `LeRobotDatasetMetadata` 对象来获取数据集的元信息# 创建数据集元数据对象,包含数据集的基本信息(如fps等) dataset_meta = lerobot_dataset.LeRobotDatasetMetadata( repo_id, local_files_only=data_config.local_files_only )然后初始化 `LeRobotDataset` 实例# 创建LeRobot数据集实例 dataset = lerobot_dataset.LeRobotDataset( data_config.repo_id, # 创建时间戳字典,用于采样动作序列 delta_timestamps={ # 对每个动作序列键,根据模型的动作视界长度和数据集的fps生成时间戳列表 key: [t / dataset_meta.fps for t in range(model_config.action_horizon)] for key in data_config.action_sequence_keys }, # 是否只使用本地文件 local_files_only=data_config.local_files_only, )特别值得注意的是,函数会根据模型的 `action_horizon`(动作预测的时间步长)和数据集的帧率(fps)计算 `delta_timestamps`,这些时间戳用于在时序数据中定位动作序列。这种计算确保了动作序列的时间间隔与模型预期一致,无论原始数据的采样率如何 - 最后,如果 `data_config.prompt_from_task` 设置为 `True`,函数会将原始数据集包装在 `TransformedDataset` 中,并应用 `PromptFromLeRobotTask` 转换
# 如果配置指定从任务中提取提示信息 if data_config.prompt_from_task: # 创建转换后的数据集,应用PromptFromLeRobotTask转换,将任务描述转换为提示 dataset = TransformedDataset( dataset, [_transforms.PromptFromLeRobotTask(dataset_meta.tasks)] )这个转换可能将任务描述转换为自然语言提示,增强模型对任务上下文的理解能力然后返回处理好的数据集
# 返回处理后的数据集 return dataset
3.2.3 transform_dataset:对数据集应用转换,比如数据清洗等(创建TransformedDataset实例)
`transform_dataset` 函数是数据预处理管道中的关键组件,负责对原始数据集应用一系列转换操作,以满足模型训练的需求。该函数接收一个原始数据集、数据配置对象以及一个可选的控制标志,并返回经过转换的新数据集
首先,函数会处理数据归一化统计信息(normalization statistics)。对于实际数据集(非"fake"数据集),如果没有显式跳过归一化统计(`skip_norm_stats=False`),函数会检查数据配置中是否包含必要的归一化统计数据。如果这些统计数据缺失,函数会抛出一个明确的错误信息,提示用户需要运行特定脚本来计算这些统计数据。这种检查机制确保了数据归一化步骤能够正确执行,避免了训练过程中可能出现的数值问题
核心转换逻辑通过创建一个 `TransformedDataset` 实例来实现,该实例封装了原始数据集和一系列转换函数。这些转换函数按照特定顺序应用:
- 首先是数据重新打包转换(`repack_transforms`),可能用于调整数据的基本结构
- 接着是一般数据转换(`data_transforms`),处理数据清洗、增强等操作
- 然后应用归一化转换(`Normalize`),使用前面获取的统计数据
- 最后是模型特定的转换(`model_transforms`),针对特定模型架构的数据格式要求
3.2.4 create_data_loader:创建用于训练的数据加载器
`create_data_loader` 函数是整个数据处理流水线的核心组件,它协调多个模块共同工作,创建一个用于模型训练的数据加载器
整个函数的工作流程可以分为三个主要阶段:
- 第一阶段:数据集准备
函数首先通过调用 `data_config.create()` 方法创建数据配置对象,该对象包含了所有数据处理相关的配置信息
随后,通过 `create_dataset` 函数创建原始数据集,这可能是一个真实的机器人数据集或者是一个用于测试的假数据集(当 `repo_id` 为 "fake" 时)
然后,调用 `transform_dataset` 函数应用一系列数据转换,包括数据重新打包、数据清洗、归一化和模型特定转换。这些转换确保了原始数据被正确处理为模型所需的格式
- 第二阶段:PyTorch 数据加载器创建
接下来,函数实例化一个 `TorchDataLoader` 对象,这是对 PyTorch 数据加载器的封装。这个过程涉及多个关键参数设置:计算各进程的本地批量大小(通过全局批量大小除以进程数)
配置数据分片策略(sharding)用于分布式训练
设置是否打乱数据、工作进程数和随机种子等
`TorchDataLoader` 的设计支持无限迭代数据(当 `num_batches` 为 `None` 时)或限定批次数的迭代,这对于训练和评估场景都很适用。其内部使用 JAX 的分片机制确保数据在分布式环境中正确分布
- 第三阶段:接口适配器实现
最后,函数通过定义嵌套类 `DataLoaderImpl` 来适配 `DataLoader` 协议接口。这个类封装了前面创建的 `TorchDataLoader` 实例,并提供了两个关键方法:
1. `data_config()` 返回数据配置信息,便于训练代码访问数据处理的元信息
2. `__iter__()` 生成器方法对数据批次进行最后的格式转换:
将字典格式的观察数据转换为结构化的 `Observation` 对象(通过 `Observation.from_dict`)提取动作数据
以元组形式 `(observation, actions)` 返回每个批次
这种设计实现了关注点分离,使数据加载、转换和格式适配各自独立,同时又协同工作,为模型训练提供了一个干净的数据流接口。函数还处理了多进程环境、数据分片和内存效率等复杂问题,这些都是大规模机器学习训练中的关键挑战
3.3 优化器系统 (optimizer.py)
定义了多种学习率调度策略:
- `CosineDecaySchedule`:余弦衰减学习率
- `RsqrtDecaySchedule`:反平方根衰减学习率
实现了常用优化器配置:
- `AdamW`:带有权重衰减的 Adam 优化器
- `SGD`:随机梯度下降优化器
通过 `create_optimizer` 函数统一创建优化器实例
3.4 检查点系统 (checkpoints.py)
负责模型状态的保存和恢复,比如管理训练状态的序列化,包括:
- 模型参数
- 优化器状态
- EMA 参数(如果使用)
且使用 Orbax 库实现高效的检查点存储
模型初始化流程 训练步骤流程 与 models 模块的交互 检查点管理流程 init_train_state(config, rng, mesh) ├── 创建模型:model = config.model.create(rng)
├── 加载权重:partial_params = config.weight_loader.load(params)
├── 设置冻结参数:params = state_map(params, config.freeze_filter, ...)
├── 创建优化器:tx = create_optimizer(config.optimizer, config.lr_schedule)
└── 返回 TrainState
train_step(config, rng, state, batch) ├── 计算梯度:loss, grads = value_and_grad(model.compute_loss)()
├── 更新参数:updates, new_opt_state = state.tx.update(grads, state.opt_state, params)
├── 应用更新:new_params = optax.apply_updates(params, updates)
├── 更新 EMA 参数(如果配置)
└── 返回 new_state, info
- 训练系统加载模型定义 (`BaseModel`) - 处理模型参数的保存和加载
- 调用模型的 `compute_loss` 方法计算损失——详见上文的「1.2.4.3 损失函数 `compute_loss`」
save_state(checkpoint_manager, state, data_loader, step) ├── _split_params(state) → 分离训练状态和推理参数
├── 保存归一化统计数据到 assets 目录
└── checkpoint_manager.save() → 保存检查点
restore_state(checkpoint_manager, state, data_loader)
├── checkpoint_manager.restore() → 恢复检查点
└── _merge_params() → 合并恢复的参数
// 待更
3.5 模型分片系统(sharding.py):含FSDP的实现
实现分布式训练时的模型参数分片
- 提供 `fsdp_sharding` 函数用于全参数数据并行(FSDP)的实现
- 基于 JAX 的分片机制,优化大规模模型的训练性能
- 通过 `activation_sharding_constraint` 处理激活值的分片
3.6 权重加载系统 (weight_loaders.py)
定义了 `WeightLoader` 协议,用于加载预训练权重,且实现了多种加载策略:
- `NoOpWeightLoader`:不加载权重(用于从头训练)
- `CheckpointWeightLoader`:从检查点加载完整权重
- `PaliGemmaWeightLoader`:从官方 PaliGemma 检查点加载权重
另,还支持权重合并功能,可以部分加载权重(如 LoRA 微调)
3.7 辅助工具(utils.py)
定义了 `TrainState` 数据类,封装了训练过程的状态
- 提供日志记录和调试功能
- 实现了 PyTree 转换和可视化功能
// 待更
第四部分 模型的训练与部署:基于客户端-服务器C/S架构——openpi-Client/Scripts
packages/openpi-client,是一个独立的客户端库openpi-client 库,主要负责:
- 提供与策略服务器通信的接口:使用 WebSocketClientPolicy 连接服务器
- 处理观察数据(图像、状态等)的发送,和动作数据的接收
- 管理客户端运行时环境
- 被各种机器人平台(如 ALOHA、DROID)使用来与服务器交互
scripts这个模块提供了服务器端的各种工具和脚本,主要包括:
- 策略服务相关——serve_policy.py:启动策略服务器,处理来自客户端的请求
- 训练相关——train.py: 模型训练的入口点
- 数据处理——compute_norm_stats.py: 计算数据归一化统计信息
- 部署相关:提供 Docker 相关的配置和安装脚本
总的来说,这是一个典型的分布式系统设计:packages/openpi-client 提供轻量级的客户端接口,而 scripts/ 则提供服务器端的功能实现,两者通过 WebSocket 协议进行通信,形成了一个完整的策略部署和执行系统
所谓客户端-服务器架构——Client-server model,也称C/S架构、主从zòng式架构,是一种将客户端与服务器分割开来的分布式架构。每一个客户端软件的实例都可以向一个服务器或应用程序服务器发出请求。有很多不同类型的服务器,例如文件服务器、游戏服务器等

客户端的特征:
- 主动的角色(主)
- 发送请求
- 等待直到收到响应
服务端的特征:
- 被动的角色(从)
- 等待来自客户端的请求
- 处理请求并传回结果
4.1 packages/openpi-client:帮真机或Sim与策略服务器进行通信和交互
该模块的目录结构如下

这个客户端包的设计非常模块化,具有良好的扩展性,主要用于:
- 连接到 OpenPI 服务器
- 处理观察数据和动作序列
- 管理机器人或仿真环境的运行
- 提供事件监控和记录功能
它的设计允许在不同的机器人平台上灵活部署,支持实时控制和异步通信,是 OpenPI 项目中连接模型服务器和实际机器人执行系统的重要桥梁
4.1.1 核心接口层
`BasePolicy`: 定义策略接口
`Environment`: 定义环境接口
`Agent`: 定义代理接口
4.1.2 通信层WebsocketClientPolicy
- `WebsocketClientPolicy`: 实现与服务器的 WebSocket 通信
- `msgpack_numpy`: 处理数据序列化
4.1.3 数据处理层
- `ActionChunkBroker`: 处理动作序列的分块和缓存
- `image_tools`: 提供图像处理和优化功能
4.1.4 运行时系统层
- `Runtime`: 核心运行时系统
- `Subscriber`: 事件订阅系统
- `agents`: 具体代理实现
4.1.5 工具支持
- 图像处理工具
- 数据类型转换
- 网络通信优化
4.2 scripts(策略服务器):包含数据处理、模型训练、模型推理的多个脚本
根据下图

可知,scripts 目录包含多个 Python 脚本,这些脚本用于数据处理、模型训练和服务部署等任务,每个脚本通常对应一个特定的功能或任务
- __init__.py
- compute_norm_stats.py: 计算数据的归一化统计信息
- serve_policy.py:启动策略服务,提供模型推理接口
- train_test.py: 训练和测试模型
- train.py: 训练模型
4.2.1 __init__.py
4.2.2 compute_norm_stats.py:计算数据的归一化统计信息
4.2.3(上) serve_policy.py:启动策略服务,用于模型推理——且支持定义特定任务的文本指令prompt
- 在这个代码片段中,首先导入了一些必要的模块和库,包括 `policy`、`policy_config`、`websocket_policy_server` 和 `config`,这些模块来自 `openpi` 项目
from openpi.policies import policy as _policy # 导入 openpi.policies.policy 模块并重命名为 _policy from openpi.policies import policy_config as _policy_config # 导入 openpi.policies.policy_config 模块并重命名为 _policy_config from openpi.serving import websocket_policy_server # 导入 openpi.serving.websocket_policy_server 模块 from openpi.training import config as _config # 导入 openpi.training.config 模块并重命名为 _config
接下来定义了一个枚举类 `EnvMode`,它表示支持的环境类型,包括 `ALOHA`、`ALOHA_SIM`、`DROID` 和 `LIBERO`class EnvMode(enum.Enum): """支持的环境。""" ALOHA = "aloha" # ALOHA 环境 ALOHA_SIM = "aloha_sim" # ALOHA 模拟环境 DROID = "droid" # DROID 环境 LIBERO = "libero" # LIBERO 环境 - 然后定义了几个数据类
`Checkpoint` 类用于从训练好的检查点加载策略,包含两个字段:`config`(训练配置名称)和 `dir`(检查点目录)
`Default` 类表示使用默认策略
`Args` 类定义了脚本的参数,包括环境类型、默认prompt、端口、是否记录策略行为以及如何加载策略
@dataclasses.dataclass class Args: """Arguments for the serve_policy script.""" # Environment to serve the policy for. This is only used when serving default policies. env: EnvMode = EnvMode.ALOHA_SIM # If provided, will be used in case the "prompt" key is not present in the data, or if the model doesn't have a default # prompt. default_prompt: str | None = None # Port to serve the policy on. port: int = 8000 # Record the policy's behavior for debugging. record: bool = False # Specifies how to load the policy. If not provided, the default policy for the environment will be used. policy: Checkpoint | Default = dataclasses.field(default_factory=Default)相当于如果你想定义你的特定任务指令prompt,则可以修改上面代码中的default_prompt - 接下来定义了一个字典 `DEFAULT_CHECKPOINT`,它为每个环境类型指定了默认的检查点配置
# 每个环境应使用的默认检查点 DEFAULT_CHECKPOINT: dict[EnvMode, Checkpoint] = { EnvMode.ALOHA: Checkpoint( config="pi0_aloha", dir="s3://openpi-assets/checkpoints/pi0_base", ), EnvMode.ALOHA_SIM: Checkpoint( config="pi0_aloha_sim", dir="s3://openpi-assets/checkpoints/pi0_aloha_sim", ), EnvMode.DROID: Checkpoint( config="pi0_fast_droid", dir="s3://openpi-assets/checkpoints/pi0_fast_droid", ), EnvMode.LIBERO: Checkpoint( config="pi0_fast_libero", dir="s3://openpi-assets/checkpoints/pi0_fast_libero", ), }`create_default_policy` 函数根据环境类型创建默认策略,如果环境类型不支持,则抛出异常def create_default_policy(env: EnvMode, *, default_prompt: str | None = None) -> _policy.Policy: """为给定环境创建默认策略 """ if checkpoint := DEFAULT_CHECKPOINT.get(env): # 获取环境对应的默认检查点 return _policy_config.create_trained_policy( _config.get_config(checkpoint.config), checkpoint.dir, default_prompt=default_prompt ) # 创建训练好的策略 raise ValueError(f"Unsupported environment mode: {env}") # 如果环境不支持,抛出异常`create_policy` 函数根据传入的参数创建策略,如果参数中指定了检查点,则从检查点加载策略,否则使用默认策略def create_policy(args: Args) -> _policy.Policy: """根据给定的参数创建策略 """ match args.policy: # 匹配策略类型 case Checkpoint(): # 如果是 Checkpoint 类型 return _policy_config.create_trained_policy( _config.get_config(args.policy.config), args.policy.dir, default_prompt=args.default_prompt ) # 创建训练好的策略 case Default(): # 如果是 Default 类型 return create_default_policy(args.env, default_prompt=args.default_prompt) # 创建默认策略 - `main` 函数是脚本的入口点,它首先调用 `create_policy` 函数创建策略,然后记录策略的元数据
def main(args: Args) -> None: policy = create_policy(args) # 创建策略 policy_metadata = policy.metadata # 获取策略的元数据如果参数中指定了记录策略行为,则使用 `PolicyRecorder` 包装策略# 记录策略的行为 if args.record: # 使用 PolicyRecorder 记录策略行为 policy = _policy.PolicyRecorder(policy, "policy_records")接着获取主机名和本地 IP 地址hostname = socket.gethostname() # 获取主机名 local_ip = socket.gethostbyname(hostname) # 获取本地 IP 地址 logging.info("Creating server (host: %s, ip: %s)", hostname, local_ip) # 记录服务器创建信息并创建一个 WebSocket 服务器来提供策略服务,最后调用 `serve_forever` 方法启动服务器server = websocket_policy_server.WebsocketPolicyServer( policy=policy, host="0.0.0.0", port=args.port, metadata=policy_metadata, ) # 创建 WebSocket 策略服务器 server.serve_forever() # 启动服务器,永远运行 - 在脚本的最后,使用 `logging` 模块配置日志记录,并调用 `main` 函数启动脚本,参数通过 `tyro.cli` 解析
4.2.3(下) 人类下达的任务指令prompt是如何在整个代码库中流转的
有一朋友在我建的「七月具身:π0复现微调交流群」里提问,为何不论设置怎样的指令prompt,机器人都执行同一套动作「后来,在他们使用多任务数据集训练后,π0可以实现prompt跟随,之前不能的原因是因为评估时机器人使用了和训练时的不同预备位姿」
对此,我特意梳理了下自定义的文本指令prompt在整个π0官方库中的数据流转——花了我一两个小时的时间,^_^
第一阶段,设定prompt,随后分别启动WebSocket服务器、WebSocket客户端并互联
- 在上面介绍的这里 设定prompt
class Args: """Arguments for the serve_policy script.""" # Environment to serve the policy for. This is only used when serving default policies. env: EnvMode = EnvMode.ALOHA_SIM # If provided, will be used in case the "prompt" key is not present in the data, or if the model doesn't have a default # prompt. default_prompt: str | None = None - 之后启动策略服务器scripts/serve_policy.py,在这个策略服务器的代码文件中,main函数中
def main(args: Args) -> None: policy = create_policy(args) policy_metadata = policy.metadata而create_policy中,要么调用create_trained_policy,要么调用create_default_policy比如,如果最终选择的是ALOHA的策略,则examples/aloha_real/main.py中的main函数会调用AlohaRealEnvironment类
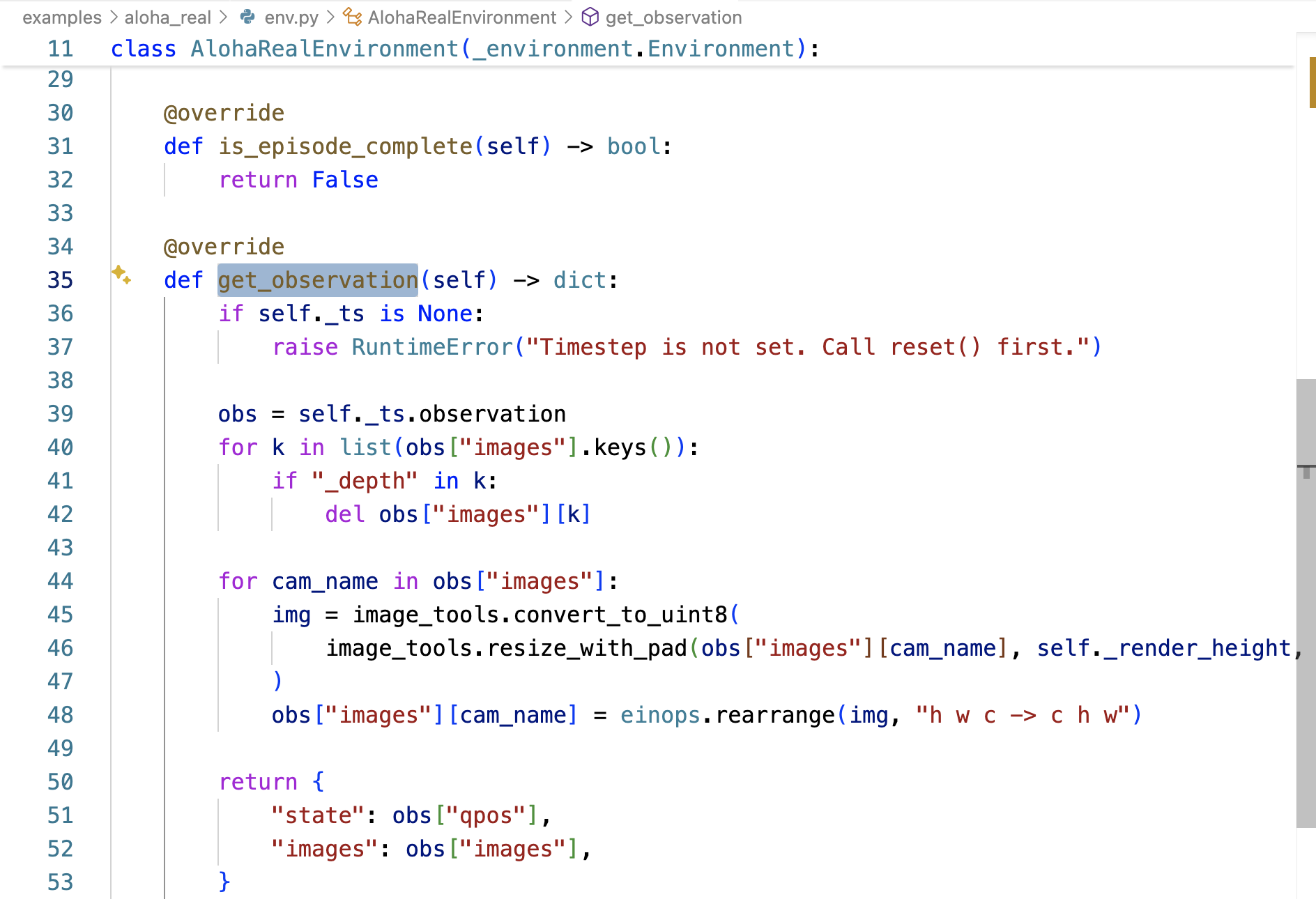
而AlohaRealEnvironment被定义在examples/aloha_real/env.py中的,随后AlohaRealEnvironment通过其中的-__init__函数设定环境的初始化「注意,这个AlohaRealEnvironment类中还定义了get_observation,下文会介绍」
而上面这个WebsocketPolicyServer,被定义在
src/openpi/serving/websocket_policy_server.py
于此,(scripts/serve_policy.py中的)policy_metadata传递给它(openpi/serving中的WebsocketPolicyServer),存储在服务器中的self._metadata
上面那个serve_forever被定义在src/openpi/serving/websocket_policy_server.py中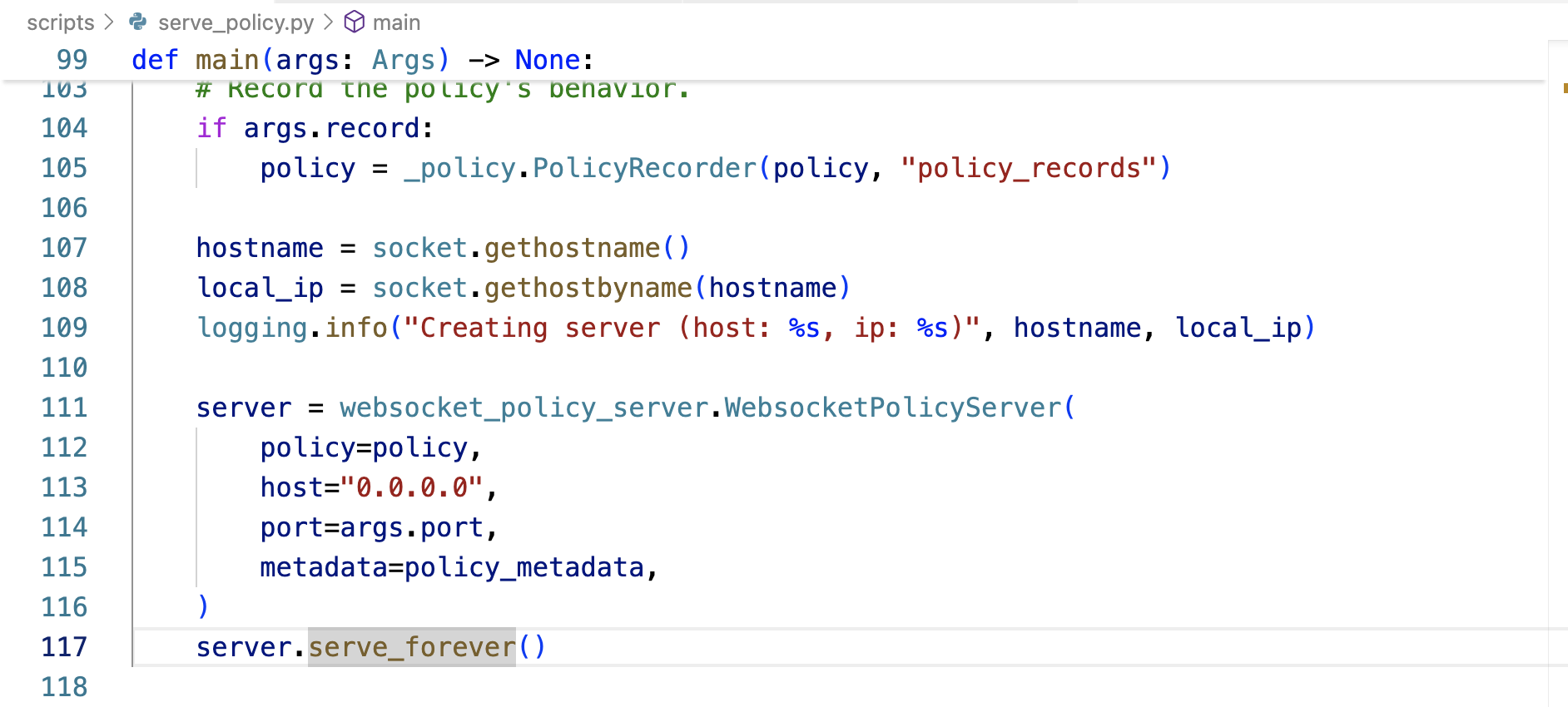
- 启动WebSocket客户端:WebsocketClientPolicy
packages/openpi-client/src/openpi_client/websocket_client_policy.py中的WebsocketClientPolicy被初始化时,调用_wait_for_server 连接WebSocket服务端
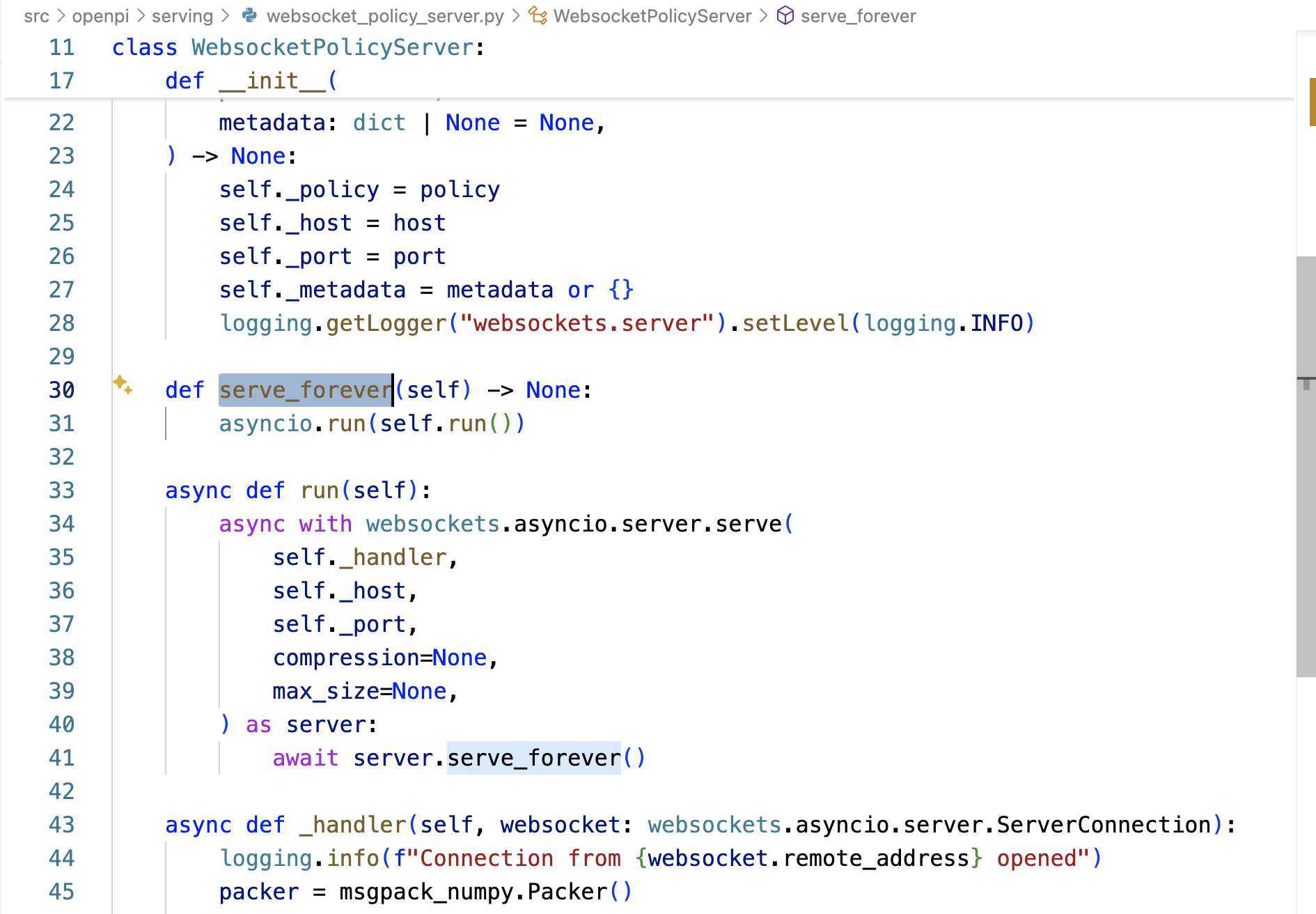
服务端WebsocketPolicyServer的_handler方法在接受连接后,立即发送self._metadata——await websocket.send(packer.pack(self._metadata)) 给客户端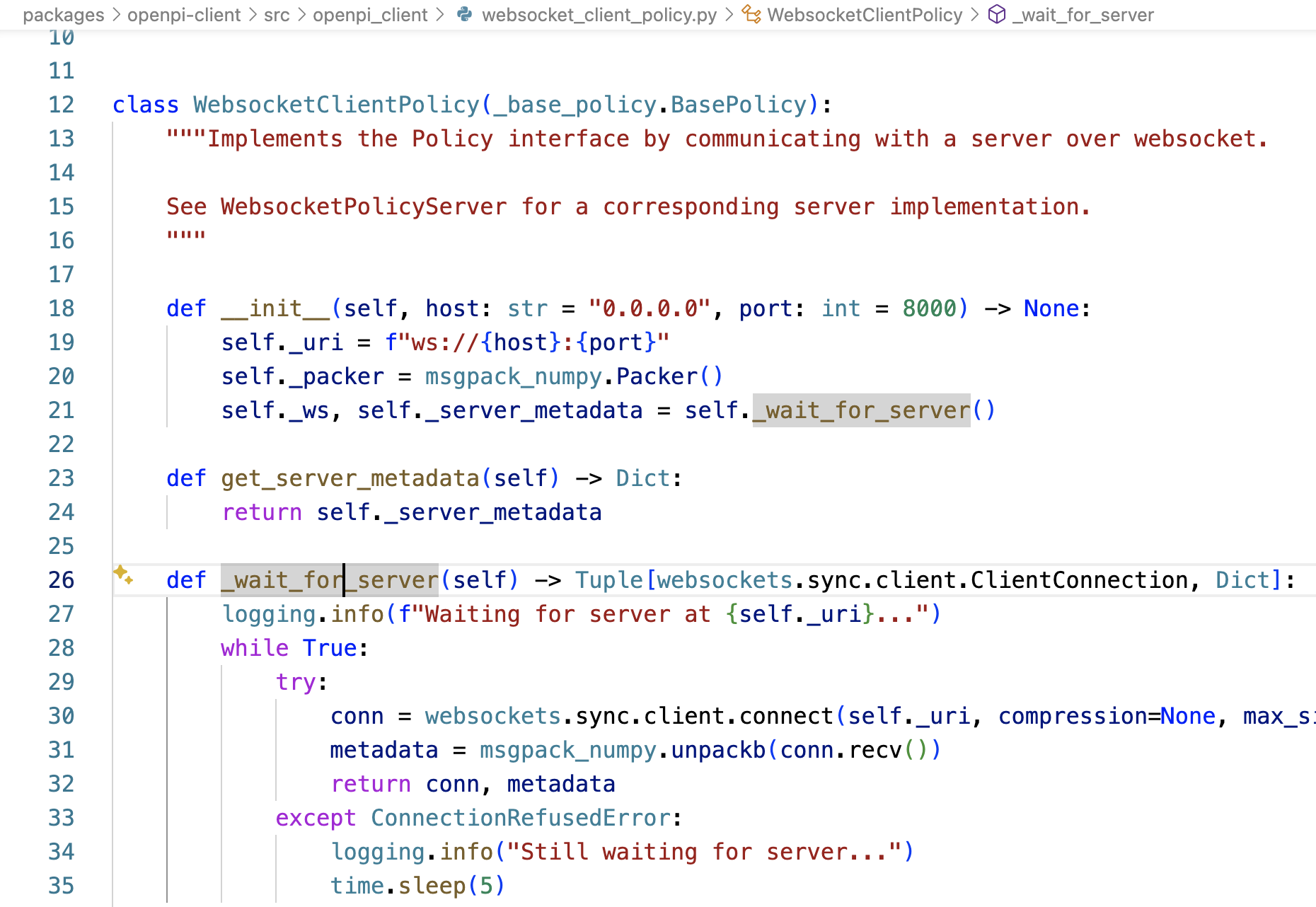
客户端_wait_for_server的接收到这个元数据之后,便存储在_server_metadata中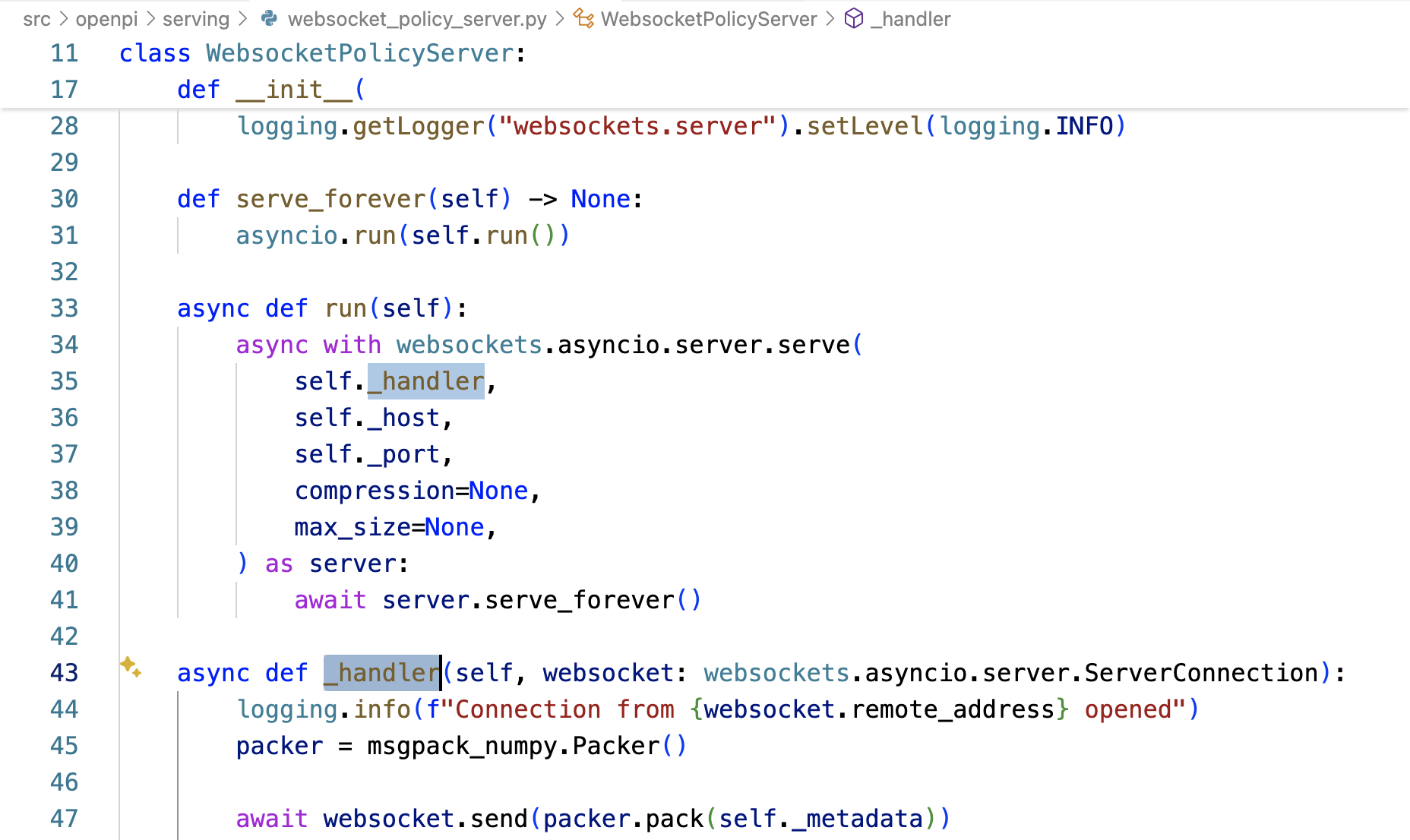
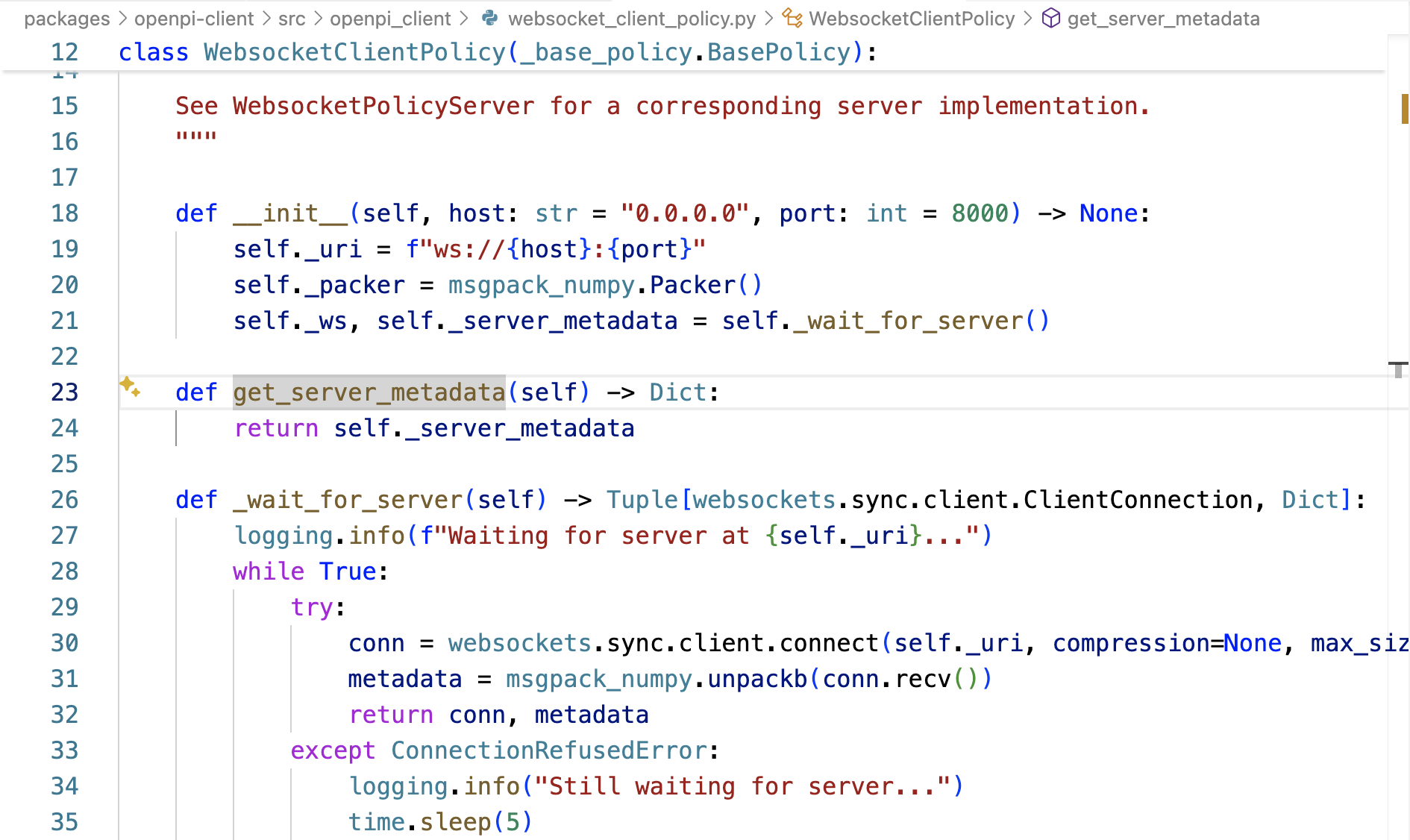
第二阶段,客户端发送推理请求、服务端处理推理请求
- 推理请求:客户端向服务端发送全部数据
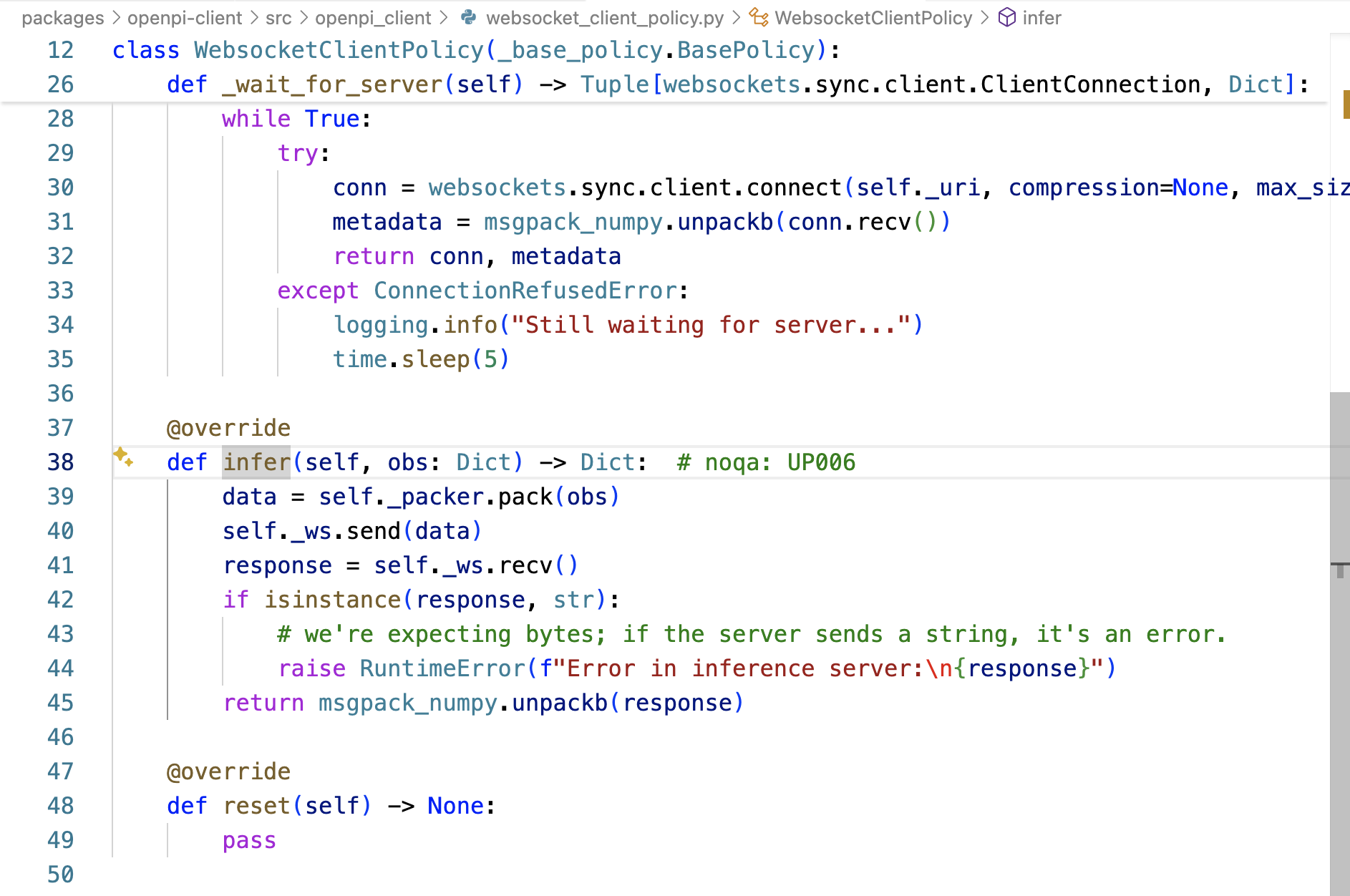
- 服务器处理推理请求
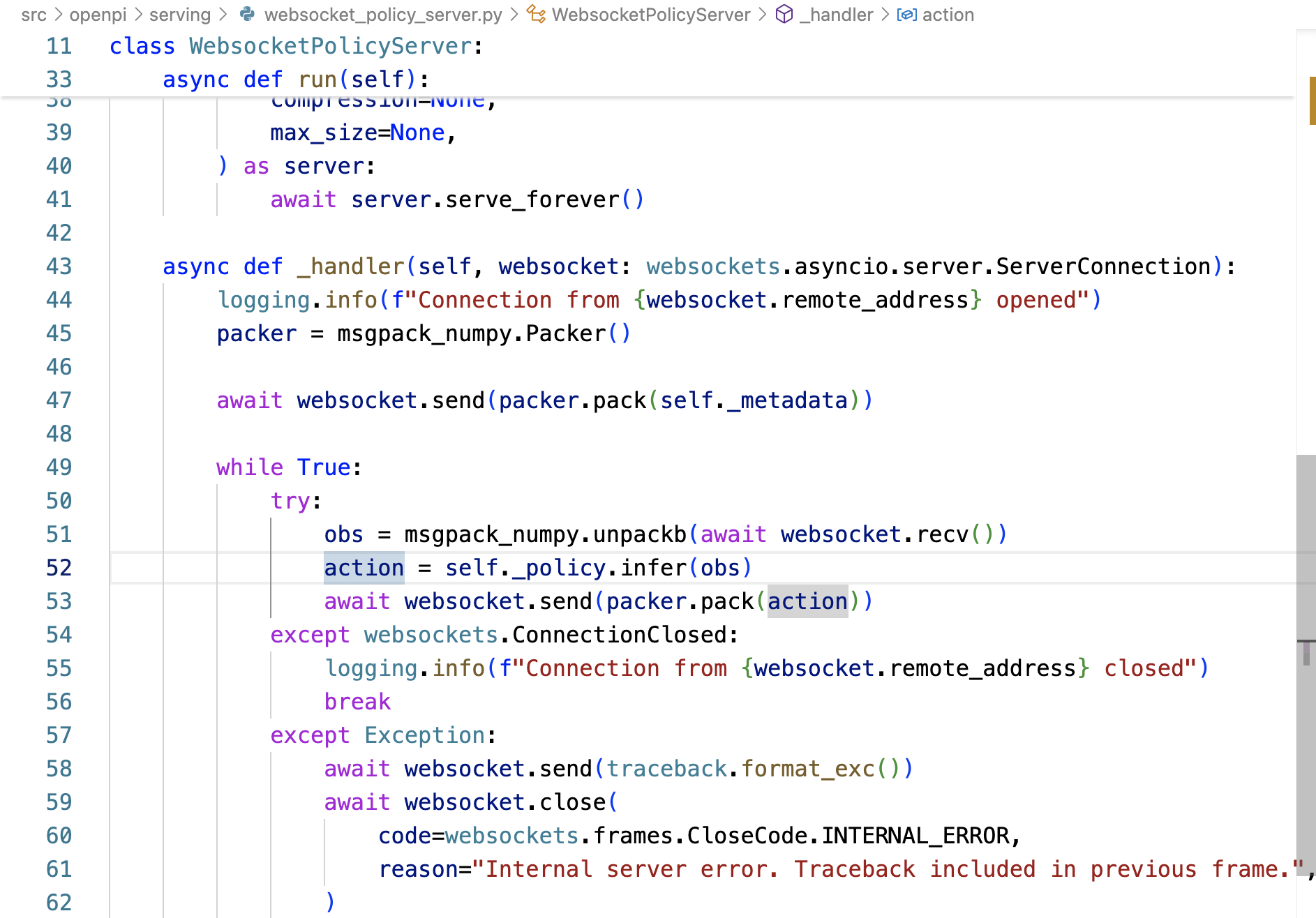
策略内部处理 (policies 下的具体策略文件)——策略的 `infer` 方法被调用以获取prompt
由于传入的 `obs` 字典没有 `"prompt"` 键,策略会查找并使用它在步骤 1 中存储的 `self._default_prompt`,类似prompt_to_use = obs.get("prompt", self._default_prompt)`。这里 `prompt_to_use` 会被赋值为自定义的指令字符串
第三阶段,模型获得全部输入数据,生成动作序列
- 获取到的prompt被传递给分词器Tokennizer,其将文本指令转换为token ID序列
这些token ID序列与图像数据、状态数据一起被输入到π0中
- π0处理这些输入,生成预测的动作序列
// 待更
4.2.4 train_test.py:训练和测试模型
4.2.5 train.py:训练模型——损失函数计算、梯度下降、参数更新
这段代码是一个基于JAX的分布式训练脚本,集成了模型初始化、训练循环、日志记录、实验跟踪和检查点管理等功能。以下是对代码的模块化解读:
一开始先后涉及日志初始化 (`init_logging`)、Weights & Biases 初始化 (`init_wandb`)、权重加载与验证 (`_load_weights_and_validate`)
之后是训练状态初始化 (`init_train_state`)
- 创建优化器(`tx`)和模型实例
- 合并预训练参数(若有)到模型状态
- 参数类型转换(如冻结参数转`bfloat16`)
- 定义分布式分片策略(`fsdp_sharding`)
- 返回值:包含模型参数、优化器状态、EMA参数的`TrainState`对象及分片信息
再之后,是单步训练`train_step`
- 前向计算:模型计算损失(启用训练模式),loss_fn中调用的损失函数来自——1.2.4.3 损失函数compute_loss:训练模型去噪的准确率(含训练数据集的来源介绍)
def train_step( config: _config.TrainConfig, rng: at.KeyArrayLike, state: training_utils.TrainState, batch: tuple[_model.Observation, _model.Actions], ) -> tuple[training_utils.TrainState, dict[str, at.Array]]: """执行单个训练步骤""" # 合并模型定义和参数 model = nnx.merge(state.model_def, state.params) model.train() # 设置模型为训练模式 @at.typecheck def loss_fn( model: _model.BaseModel, rng: at.KeyArrayLike, observation: _model.Observation, actions: _model.Actions ): """损失函数""" # 计算每个数据项的损失 chunked_loss = model.compute_loss(rng, observation, actions, train=True) return jnp.mean(chunked_loss) # 返回平均损失 - 随机数生成
# 根据当前步数折叠随机数种子,确保每步使用不同随机数 train_rng = jax.random.fold_in(rng, state.step) # 解包批次数据 observation, actions = batch - 梯度计算:通过`nnx.value_and_grad`获取梯度,仅更新可训练参数
# 过滤出可训练参数 diff_state = nnx.DiffState(0, config.trainable_filter) # 计算损失和梯度 loss, grads = nnx.value_and_grad(loss_fn, argnums=diff_state)(model, train_rng, observation, actions) - 参数更新:应用优化器更新,合并新参数到模型
# 过滤出可训练参数 params = state.params.filter(config.trainable_filter) # 使用优化器更新参数 updates, new_opt_state = state.tx.update(grads, state.opt_state, params) new_params = optax.apply_updates(params, updates) # 更新模型参数并返回新的完整状态 nnx.update(model, new_params) new_params = nnx.state(model) - EMA维护:指数平滑更新关键参数
# 创建新的训练状态,更新步数、参数和优化器状态 new_state = dataclasses.replace(state, step=state.step + 1, params=new_params, opt_state=new_opt_state) if state.ema_decay is not None: # 如果使用EMA,更新EMA参数 new_state = dataclasses.replace( new_state, ema_params=jax.tree.map( lambda old, new: state.ema_decay * old + (1 - state.ema_decay) * new, state.ema_params, new_params ), ) # 过滤出核心参数(不包括偏置、缩放等) kernel_params = nnx.state( model, nnx.All( nnx.Param, # 必须是参数 nnx.Not(nnx_utils.PathRegex(".*/(bias|scale|pos_embedding|input_embedding)")), # 排除特定名称 lambda _, x: x.value.ndim > 1, # 必须是多维的 ), ) - 指标收集:损失、梯度范数、参数范数(过滤非核参数)
# 收集训练信息 info = { "loss": loss, # 损失值 "grad_norm": optax.global_norm(grads), # 梯度范数 "param_norm": optax.global_norm(kernel_params), # 参数范数 } return new_state, info
最后是主函数`main`
- 环境初始化:日志、JAX配置、随机种子、设备分片
- 数据准备:分布式数据加载器,分片策略(数据并行)
- 状态恢复:检查点管理器处理恢复逻辑。
- 训练循环:
JIT编译的分布式训练步骤(`ptrain_step`)
定期日志记录(控制台 + W&B)
检查点保存(间隔保存 + 最终保存)
- 清理:等待异步保存操作完成
// 待更
4.2.6 scripts/docker
好的,下面是对 `openpi-main/scripts/docker` 目录的详细分析。这个目录通包含与 Docker 相关的脚本和配置文件,用于构建和管理 Docker 容器,具体而言,包含以下文件和子目录:

主要文件和功能如下所示
- docker/compose.yml
- docker/install_docker_ubuntu22.sh
- docker/install_nvidia_container_toolkit.sh
- docker/serve_policy.Dockerfile
// 待更
第五部分 examples :各种机器人平台及策略客户端的示例实现
根据π0对应examples模块的结构

其涉及以下模块
- aloha_real/:真实机器人ALOHA的示例
- aloha_sim/:ALOHA模拟器的示例
- droid/:DROID机器人的示例
- libero/:LIBERO基准测试的示例
- simple_client/:简单客户端的示例
- ur5/:UR5机器人的示例
- inference.ipynb:推理示例的Jupyter Notebook
- policy_records.ipynb:策略记录示例的Jupyter Notebook
5.1 aloha_real
// 待更
- 从token序列中提取动作
- `__init__` 方法接收一个 `max_len` 参数(默认为 48)来设定token序列的最大长度
- 二方面,使用欧拉法更新动作状态和时间步
- 一方面,提取模型输出并预测速度场`v_t`——相当于本质是通过PaliGemma模型预测去噪方向 `v_t`
- 完整注意力掩码,将前两个掩码组合,形成完整的注意力控制机制
- 前缀-后缀注意力掩码,控制后缀token如何关注前缀token(图像和文本输入)
- 图像处理:说白了,就是把图像token化
- 如果有需要被LoRA微调的部分,则过滤器列表里不添加原始参数之外的LoRA相关参数(代表着不被过滤)
- 即,接下来是对PaLI-Gemma变体的处理
- 只对 PaLI-Gemma 使用 LoRA
- 其支持多种输入,比如
- 关节控制
- π0的源码结构非常清晰、可读性高,不愧是成熟的商业化公司,是我司七月的学习榜样之一



