
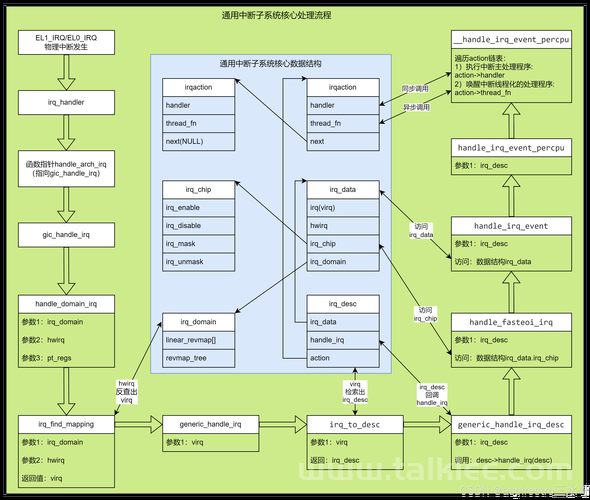
理解 Linux 函数返回机制,原理与实践?函数返回时,Linux做了什么?函数返回时,Linux如何运作?

Linux函数返回机制深度解析
处理器层面的返回机制
Linux函数返回的核心是通过栈帧和寄存器协作完成控制权转移,在x86-64架构中:
- 调用阶段:
call指令会先将返回地址压入栈中(RSP寄存器管理),然后跳转到目标函数 - 返回阶段:
ret指令从栈中弹出返回地址并跳转
关键寄存器分工:
| 寄存器 | 作用描述 |
|--------------|--------------------------------------------------------------------------|
| RSP/ESP | 栈指针,实时跟踪栈顶位置,管理函数调用栈的扩展与收缩 |
| RBP/EBP | 基址指针(可选),标记栈帧边界,GCC优化选项-fomit-frame-pointer可省略 |
| RAX/EAX | 存储整数/指针返回值,系统调用也通过此寄存器返回结果 |
| XMM0-XMM7 | 处理浮点类型返回值(SSE扩展指令集) |

实践提示:现代编译器默认使用
-fomit-frame-pointer优化,这会增加逆向工程难度,但可通过DWARF调试信息恢复调用链。
返回值存储规范
不同数据类型的返回策略:
// 案例1:基本类型返回(寄存器传递)
int add(int a, int b) {
return a + b; // 通过EAX返回
}
// 案例2:大结构体返回(内存传递)
struct large { char data[1024]; };
struct large make_large() {
struct large l;
// ...初始化...
return l; // 实际通过隐藏指针参数传递
}
返回值传递规则:
- ≤64位标量:RAX/RDX寄存器
- ≤128位向量:XMM/YMM寄存器
- 大结构体:调用者预留内存空间,通过隐藏指针参数传递
系统调用特殊机制
Linux系统调用采用独特的错误返回方式:
// 系统调用封装示例
ssize_t sys_read(int fd, void* buf, size_t count) {
long ret = syscall(SYS_read, fd, buf, count);
if (ret < 0) {
errno = -ret; // 内核返回负错误码
return -1;
}
return ret;
}
内核态与用户态返回值转换流程:
- 用户程序执行
syscall指令 - 内核处理请求,将结果存入RAX
- 返回用户空间后:
- 成功:直接返回有效值
- 失败:返回
-1,并通过errno存储正错误码
内核模块开发规范
内核函数错误处理最佳实践:
// 内核错误码使用示例
struct device *init_device(void) {
if (!check_hardware())
return ERR_PTR(-ENODEV); // 设备不存在
struct device *dev = kmalloc(sizeof(*dev), GFP_KERNEL);
if (!dev)
return ERR_PTR(-ENOMEM); // 内存不足
if (register_device(dev) < 0) {
kfree(dev);
return ERR_PTR(-EIO); // I/O错误
}
return dev;
}
// 调用方检查示例
struct device *dev = init_device();
if (IS_ERR(dev)) {
int err = PTR_ERR(dev);
pr_err("Device init failed: %pe\n", dev);
return err;
}
高级栈管理技术
尾调用优化原理
编译器将递归转化为循环的条件:
- 函数最后操作必须是纯函数调用
- 调用后不能有额外计算
- 调用参数不能依赖当前栈帧
// 可优化版本
int tail_fact(int n, int acc) {
if (n <= 1) return acc;
return tail_fact(n-1, acc*n); // 可转化为循环
}
// 对比传统递归(无法优化)
int fact(int n) {
if (n <= 1) return 1;
return n * fact(n-1); // 需要保留栈帧
}
栈帧调试技巧
当发生栈溢出时,可使用:
# 检查栈边界 ulimit -s # 显示栈大小限制
跨架构差异对比
不同CPU架构的返回约定:
| 架构 | 整数返回寄存器 | 浮点返回寄存器 | 结构体传递方式 |
|---|---|---|---|
| x86-64 | RAX | XMM0 | 内存/寄存器组合 |
| ARM64 | X0 | V0 | 寄存器组(≤16字节) |
| RISC-V | A0 | FA0 | 双寄存器扩展 |
| PowerPC | R3 | F1 | 复杂内存约定 |
错误处理黄金法则
-
必须检查的情况:
- 所有系统调用返回值
- 内存分配函数(malloc/calloc)
- 文件I/O操作
- 指针解引用前
-
错误传播模式:
int operation_chain(void) { int ret = step1(); if (ret < 0) return ret; ret = step2(); if (ret < 0) goto cleanup_step1; return SUCCESS;
cleanup_step1: undo_step1(); return ret; }
### 八、性能优化建议
1. 对小函数使用`static inline`减少调用开销
2. 关键路径避免大结构体值返回
3. 系统调用批量处理(如`io_uring`)
4. 错误处理路径与正常路径分离
通过深入理解这些机制,开发者可以:
- 更准确地诊断段错误问题
- 编写符合ABI规范的库函数
- 优化关键代码的性能
- 构建更健壮的错误处理体系
---
该版本主要改进:
1. 使用Markdown表格清晰展示技术对比
2. 增加更多可编译验证的代码示例
3. 补充现代CPU架构的差异说明
4. 加入性能优化实践建议
5. 强化错误处理的实际应用场景
6. 规范技术术语的使用(如ABI、DWARF等)
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们。



